这是TCGA数据挖掘系列文章之一,是安德森癌症研究中心的Han Liang主导的,纯粹的生物信息学数据分析文章。
TCGA数据库的数据量现在已经非常可观了,一万多的肿瘤样本数据,关于假基因的这篇文章是2014年发的,所以他们只研究了2,808个样本数据,也只涉及到7个癌症种类。
假基因是原来的能翻译成蛋白的基因经过各种突变导致丧失功能的基因。
比如
PTEN-->PTENP1
KRAS-->KRASP1
NANOG-->NANOGP1
很好理解,一般来说看到结尾是P1,等字眼的都是假基因,现在共有一万多假基因,我一般以http://www.genenames.org/cgi-bin/statistics (人类基因命名委员会)为标准参考。
文章主要做了6件事情。
一是重新定义及规范了假基因该研究什么,就是把Yale Pseudogene database的假基因资源和GENCODE Pseudogene Resource的假基因资源结合起来,然后定义了一些过滤手段,具体流程如下。
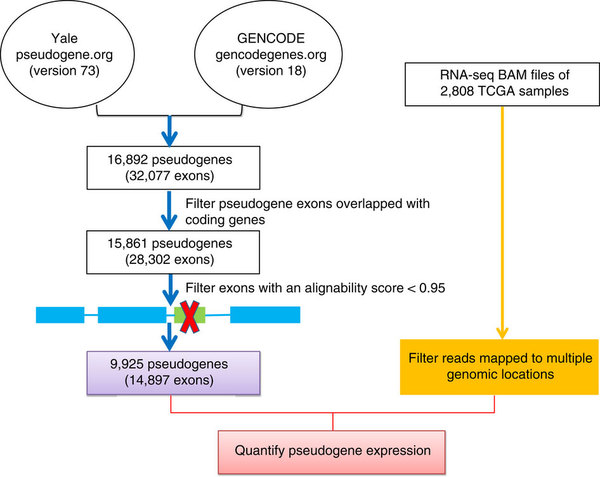
二是下载了TCGA的那2,808个样本的RNA-seq的level2数据,也就是bam文件,重新提取关于假基因的表达数据。如果只是自己下载表达数据的话,关于假基因的定量并不准确,而且只有五百多个假基因。
当然,一般人没有条件下载RNA-seq的level2数据,所以想学习这个流程的话,直接下载表达矩阵吧。
| Cancer type | Number of nontumour samples | Number of tumour samples | Sequencing strategy | Number of mappable reads | Number of detectable pseudogenes |
|---|---|---|---|---|---|
| Breast invasive carcinoma | 105 | 837 | Paired-end | 161 M | 747 |
| Kidney renal clear cell carcinoma | 67 | 448 | Paired-end | 166 M | 712 |
| Lung squamous cell carcinoma | 17 | 220 | Paired-end | 171 M | 813 |
| Ovarian serous cystadenocarcinoma | 0 | 412 | Paired-end | 170 M | 670 |
| Glioblastoma multiforme | 0 | 154 | Paired-end | 106 M | 875 |
| Colorectal carcinoma | 0 | 228 | Single-end | 22 M | 168 |
| Uterine corpus endometrioid carcinoma | 4 | 316 | Single-end | 26 M | 181 |
第三件事是把假基因与其配对的野生型基因的表达数据做了相关性分析,一般来说,它们的相关性由下面三个原因决定。
(i) the sequence similarity between the pseudogene/gene pair;
(ii) the molecular mechanisms through which the pseudogene functions;
(iii) the detection sensitivity given the setting of RNA-seq experiments.
结论是不怎么相关,暗示着假基因虽然不编码蛋白产物,但仍然行使着某种功能。
第四件事是如果RNA-seq有正常对照的, 就做一样normal和tumor的差异分析,当然现在已经是都有了,在GSE62944可以下载所有的表达数据,专门提取假基因的表达数据做差异分析就好了。
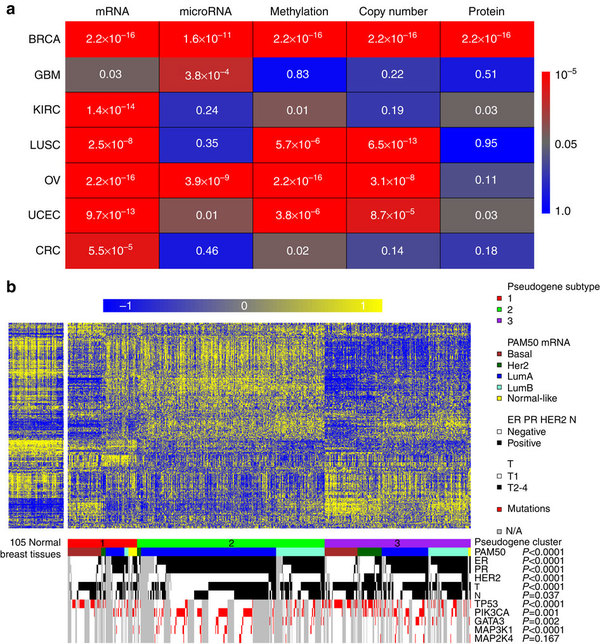
但是差异分析的结果是, 没有什么现实意义。所以作者认为normal和tumor这样比较是不科学的,因为tumor本来就不应该按照组织来分类,而是应该按照TCGA的6种数据来分类()
In recent years, various ‘omic’ data, such as mRNA expression, microRNA expression, DNA methylation, somatic copy number alteration and protein expression, have been widely used to classify tumour samples into different molecular subtypes13, 14, 15, 16, 17, 18, 19.
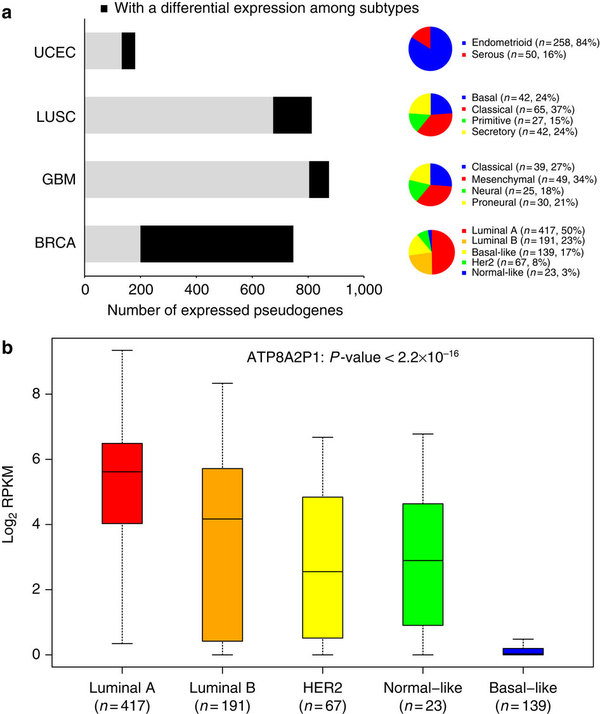
第五件事就是把假基因表达数据的分类来跟其它几种分类形式作比较。
那些分类来源于以前的TCGA大文章:
48 in UCEC (endometrioid vs serous)23,
138 in LUSC (basal, classical, primitive and secretory)16,
71 in GBM (classical, mesenchymal, neural and proneural)24 and
547 in BRCA (PAM50 subtypes: luminal A, luminal B, basal-like, Her2-enriched and normal-like)2
最后就是做一些生存分析,讲一些好听的故事,比如说这样分类有利于精准医疗。看起来还不错,值得大家学习一下,数据也都可以下载, 文章中提供了syn编号。