时间序列单细胞转录组数据分析
文章是: Reconstruction of developmental landscapes by optimal-transport analysis of single-cell gene expression sheds light on cellular reprogramming. 虽然于2017年9月公布在了bioRxiv上面,但是至今仍然没正式发表,包含了六万多个单细胞转录组数据,持续追踪了MEF细胞系诱导为IPSC细胞的动态变化过程,并且从发育的角度分析了这些数据
We demonstrate the power of WADDINGTON-OT by applying the approach to study 65,781 scRNA-seq profiles collected at 10 time points over 16 days during reprogramming of fibroblasts to iPSCs.
背景介绍
Waddington提出的发育景观
上世纪50年代,胚胎发育生物学家Conrad Hal Waddington提出的发育景观假说认为,分化成熟的细胞变回多能干细胞是个不可能发生的事件。但是日本京都大学教授山中伸弥于2006年却发现并验证,这种细胞可以发育成为身体各种组织细胞。iPS细胞的发现成就了目前轰轰烈烈的干细胞研究领域,山中伸弥教授也因此获得2012年诺贝尔生理或医学奖。
iPS (诱导多潜能干细胞)重编程实验的涌现使人们重新重视了上个世纪50年代胚胎发育生物学家Waddington提出的发育景观。虽然它只是一个隐喻,但其形象地描述了细胞的自发的层次分叉过程并隐含了细胞类型之间转换的可能性,从而作为一个整体框架最近被广泛应用来解释细胞发育和重编程。
详见:https://zhuanlan.zhihu.com/p/25333058
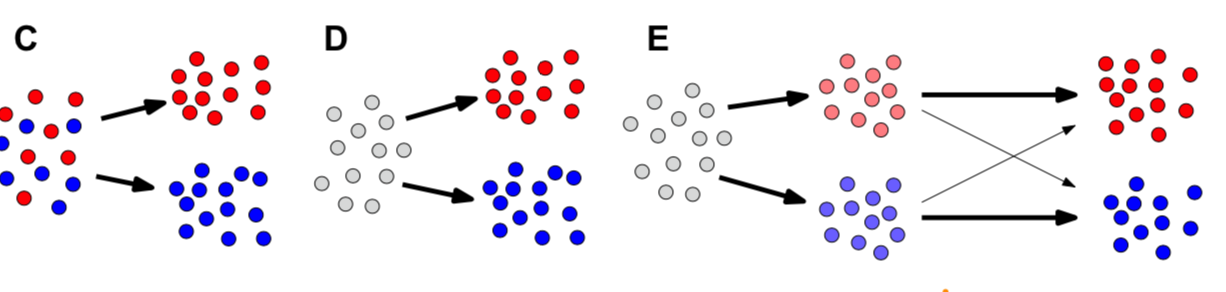
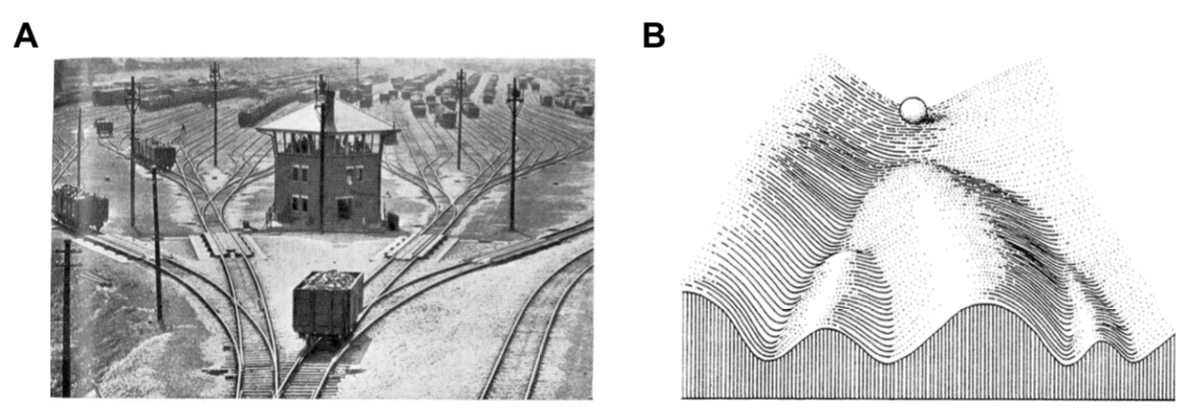
Waddington 在两个时期提出的假说:
- initially (1936) illustrated by railroad cars on switching tracks (A)
- later (1957) by marbles rolling in a landscape (B), with trajectories shaped by hills and valleys.
如图:
最优传输理论
最优传输理论(Optimal Transport),也叫Monge-Kantorovich Problem。最早由法国数学家Monge提出,二战期间由俄国数学家Kantorovich推广后开始迅速发展,Kantorovich也因他在这个领域做出的贡献得了1975年的经济学诺贝尔奖。
Monge最早提出的问题可以理解为,有一堆土在地点A,现在我们要将这堆土转移到地点B,但是我们运土是要费体力的,怎么搬这些土可以让我们的体力消耗降到最小。现在我们量化这个问题,将土在地点A的分布称之为”Initial Distribution”,在地点B的分布称为”Final Distribution”,我们称消费的体力为Cost,通过一个”Cost Function”计算得出,每种搬运方案为一个”Mapping”。我们现在要在所有Mapping中寻找Cost最低的那一个,这就是最优传输理论要解决的问题。
可能看完这些,有的小伙伴还是不太懂搬运方案和Mapping是怎样一回事。这里解释一下,比如在地点A和地点B的时候,土堆的形状都要形成一个标准正态分布 N(0, 1),我们”将A土堆中间的土先搬过去形成B土堆的尾巴”和”将A土堆的土直接放到B土堆对应位置”所消耗的体力大部分情况下是不一样的,这就是两种不同的方案对应着不同的Cost。
这几年,由最优传输理论衍生出来的”Martingale Optimal Transport”在金融数学有不少应用,有不少人在研究。简单的说就是给这些”Mapping”加了个限制,要求他们必须是”Martingale”。
如图:
发育生物学家感兴趣的基本问题
如下:
- What classes of cells are present at each stage?
- For the cells in each class, what was their origin at earlier stages, what are their potential fates at later stages, and what is the actual outcome of a given cell?
- To what extent are events along a path synchronous or asynchronous?
- What are the genetic regulatory programs that control each path?
- What are the intercellular interactions between classes of cells?
- How deterministic or stochastic is the process—that is: if, and how early, does it become determined that a particular cell or an entire cell class is destined to a specific fate?
- For a given origin and target fate, is there only a single path to the target, or are there multiple developmental paths?
- To what extent is the process cell-intrinsic, driven by intracellular mechanisms that do not require ongoing external inputs, or externally regulated, being affected by other contemporaneous cells?
- For artificial processes such as induced reprogramming, there are additional questions: What off-target cell classes arise?
- To what extent do cells activate normal developmental programs vs. unnatural hybrid programs?
- How can the efficiency of reprogramming be improved?
示意图如下;
然后列举一些前人在探索这些问题方面的研究成果,指出他们做的还不够。而单细胞转录组测序技术非常强大,适合解决这个问题。
单细胞转录组在探索发育轨迹这方面也有过一些应用了,主要的算法集中于3个:- k-nearest neighbor graphs
- binary trees
- diffusion maps
他们的缺陷很明显,有3个:- 首先为那些稳定的生物学过程设计的,比如cell cycle or adult stem cell differentiation
- 其次,单细胞本身也是多种生物学状态的叠加,比如cell proliferation and death就会影响那些算法的表现。
- 最后,大部分模型的假设限制很大,比如one-dimensional trajectories and zero-dimensional branch points
所以作者把Optimal Transport (OT)的算法,应用到了时间序列的单细胞转录组数据来探索发育的过程。当然,表现很好的啦,揭示了重编程的分子机理。
几大发现如下:- (1) identifying alternative cell fates, including senescence, apoptosis, neural identity, and placental identity;
- (2) quantifying the portion of cells in each state at each time point;
- (3) inferring the probable origin(s) and fate(s) of each cell and cell class at each time point;
- (4) identifying early molecular markers associated with eventual fates;
- (5) using trajectory information to identify transcription factors (TFs) associated with the activation of different expression programs.
单细胞转录组数据处理
首先得到表达矩阵
因为是 10X Genomics数据,所以直接用官方工具CELLRANGER 即可,过滤后得到
65,781 cells and G = 16, 339 genes 的表达矩阵然后降维
先过滤掉那些在所有细胞表达没什么变化的基因,这一步利用的是R包SEURAT的MeanVarPlot函数,剩下2076个基因。
然后使用 diffusion component embedding进行降维处理,,这一步利用的是R包 DESTINY。
分析了top100 diffusion components的,发现只有top20是显著的富集到 developmental processes ,所以作者只选取了top 20 diffusion components可视化
现在剩下了20*65781的矩阵,首先使用R语言的FNN包里面的 fast k-NN algorithm ,然后利用ForceAtlas2算法计算 force-directed layout on the k-NN graph
单细胞聚类
同样的剩下了20*65781的矩阵,使用了 Louvain-Jaccard community detection 算法,默认参数分成33类
最优传输算法
主要就是考量 proliferation score和growth rate,
基因调控网络
自己写Python脚本做的分析,公式有点多而且有点复杂,但是里面提到了Shannon diversity of the transport maps
基因表达模块
使用了Graphical Lasso算法,来自于R包glasso,还用了R包IGRAPH的Infomap community detection 算法看基因模块的网络结构。
使用HOMER软件的findGO.pl测序对基因模块注释到biological signatures
每个基因集合的特征分数算法就是它里面的所有基因的z-score的平均值。与3个已有算法比较
见文末
实验环节:iPSC
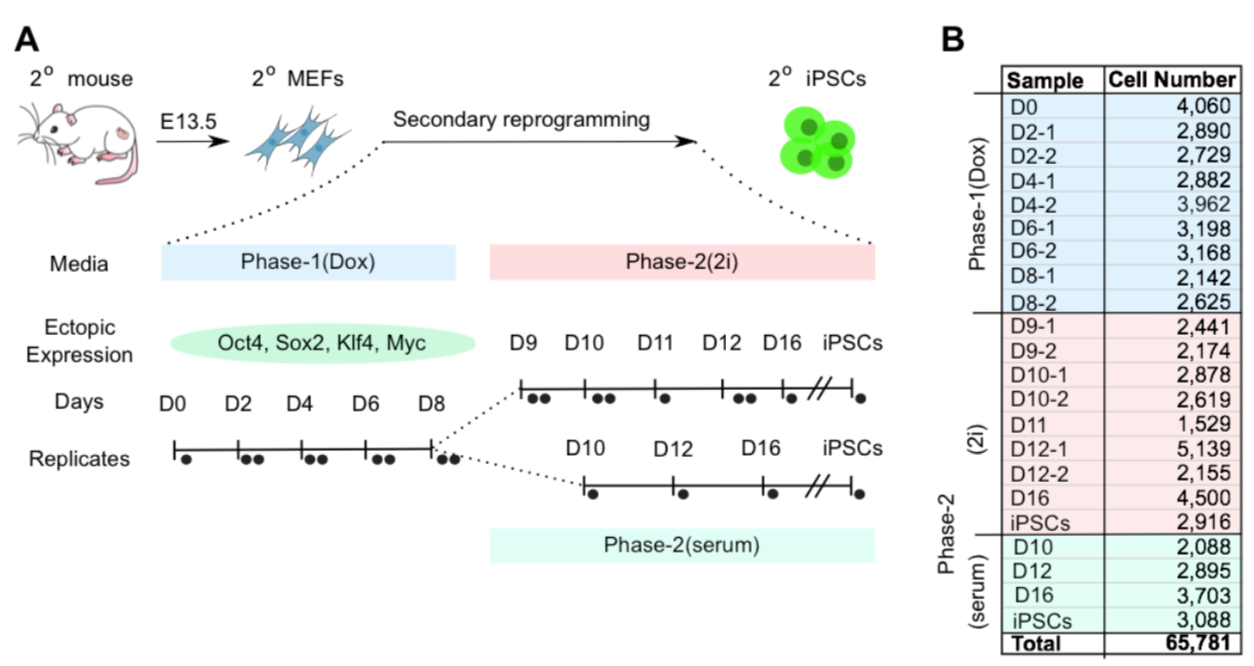
We obtained mouse embryonic fibroblasts (MEFs) from a single female embryo homozygous for ROSA26-M2rtTA, which constitutively expresses a reverse transactivator controlled by doxycycline (Dox)
多西环素(Doxycycline),具有抗炎作用,也称作是强力毒素(doxycycline),a Dox-inducible polycistronic cassette carrying Pou5f1 (Oct4), Klf4, Sox2, and Myc (OKSM), and an EGFP reporter incorporated into the endogenous Oct4 locus (Oct4-IRES-EGFP).
We plated MEFs in serum-containing induction medium, with Dox added on day 0 to induce the OKSM cassette (Phase-1(Dox)).
第八天之后把添加的dox取出来,然后把细胞转移到serum-free N2B27 2i medium (Phase-2(2i)) 和serum (Phase-2(serum)).这两种培养条件下,直到细胞系表达出内源性的Oct4,认为是重编程成功。
如图:
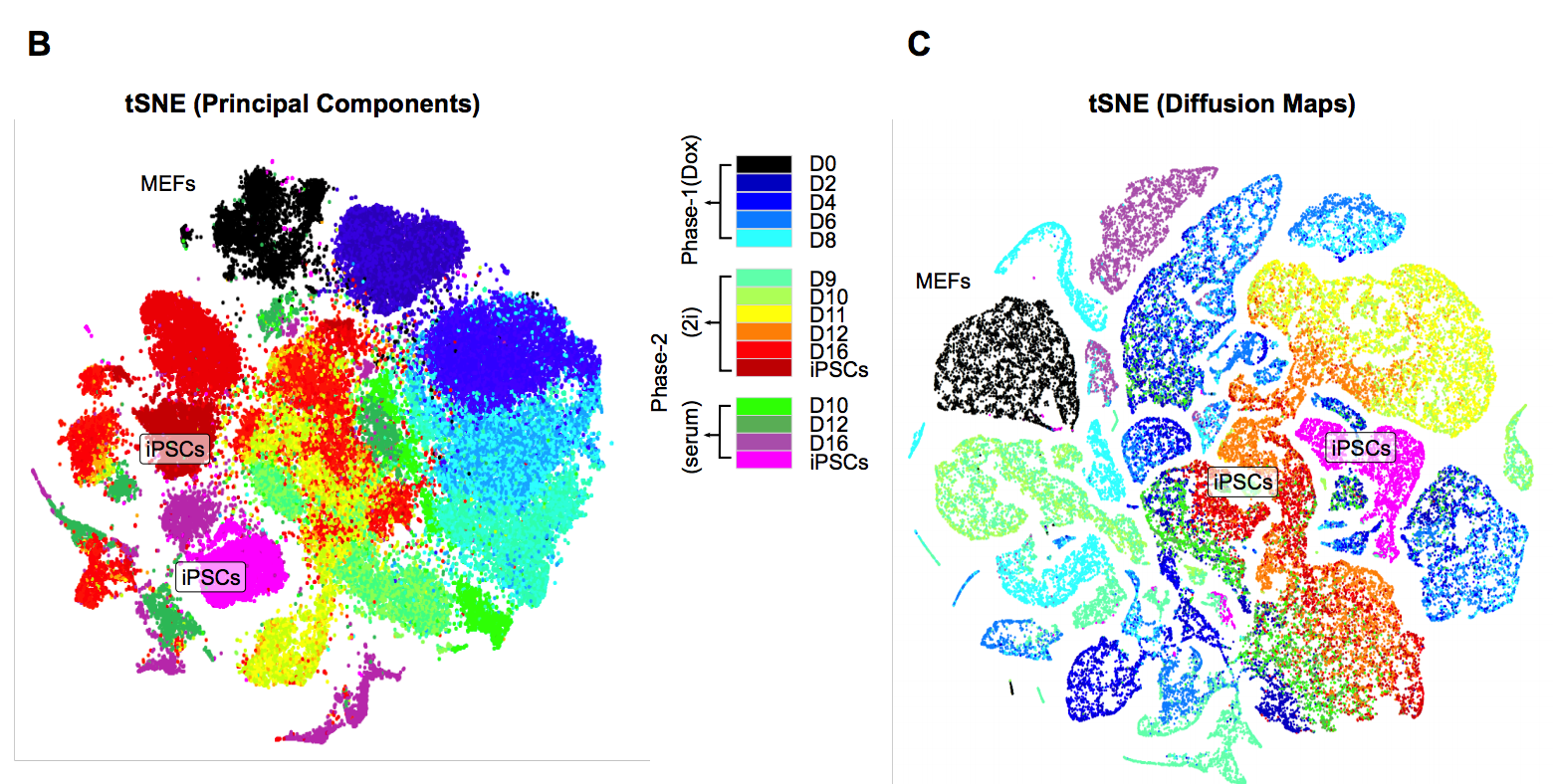
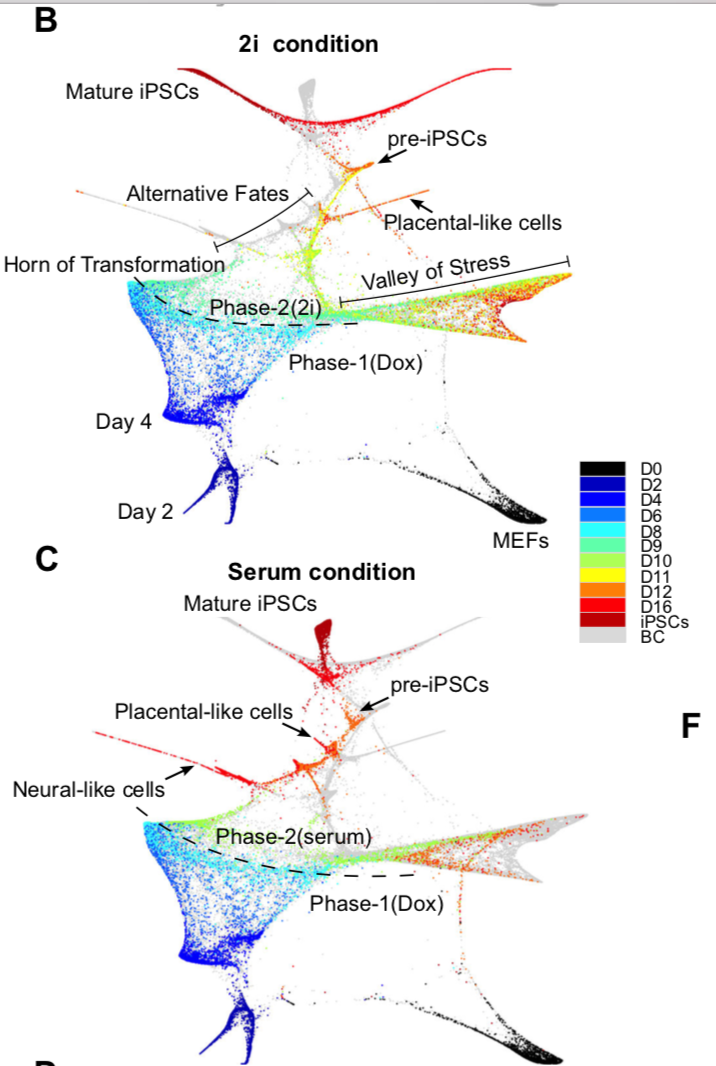
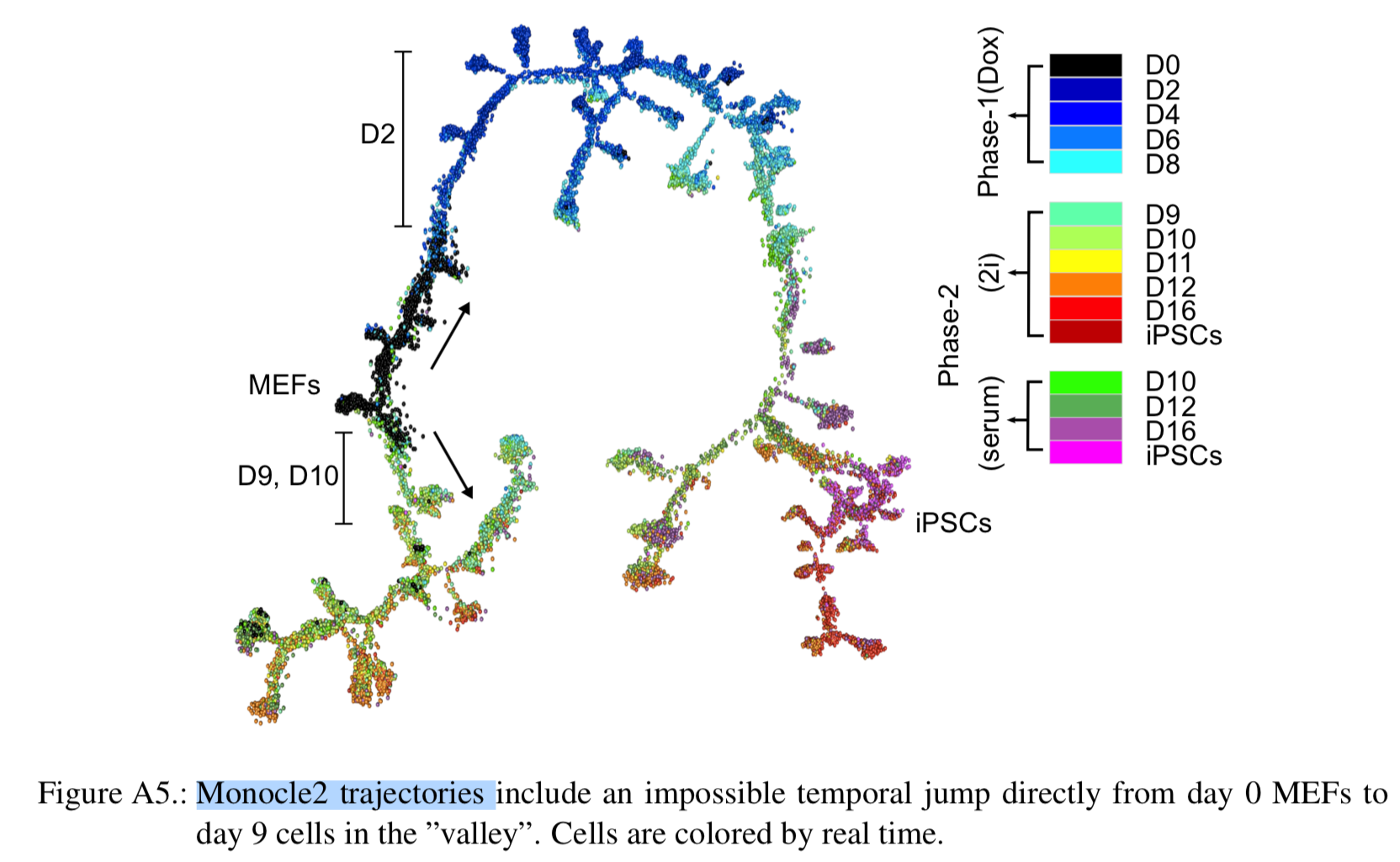
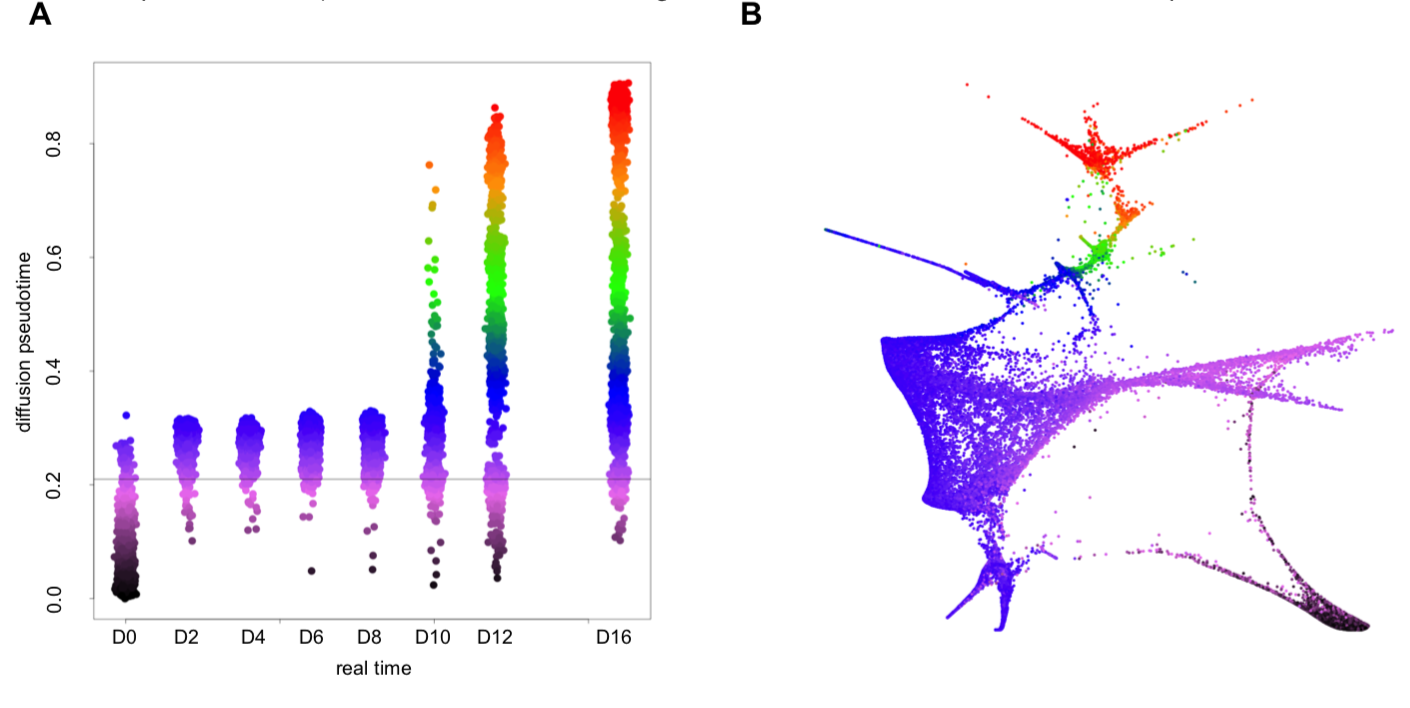
在各个时间段均测量了好几千个细胞的表达谱,总共65781个细胞。发育景观
作者花了5大段在描述下面的图:
可以看到细胞发育始于第0天,很容易理解,而且绝大部分的0天细胞都能被聚成一个类,表现为强烈MEF identity的signature信号。但是第二天的Dox处理后,细胞被诱导高表达OKSM cassette,而且开始转变为3个不同的clusters,但总体来说这3类都表现很强的增殖信号。
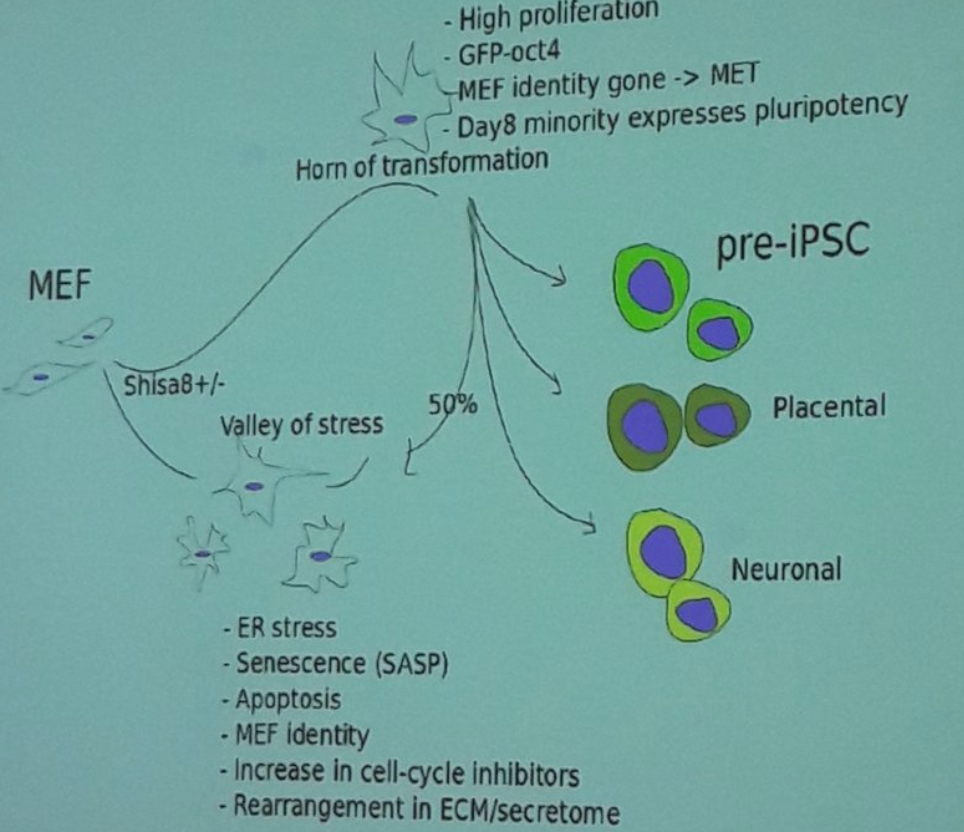
第4天后细胞很明显朝着两个不同的方向变化,这里定义为:Valley of Stress and the Horn of Transformation。
Following Dox withdrawal and media replacement on day 8, the cells in the Horn adopt one of four alternative outcomes by day 12 (senescence, neuronal program, placental program, and pre-iPSCs).cluster之间的转移
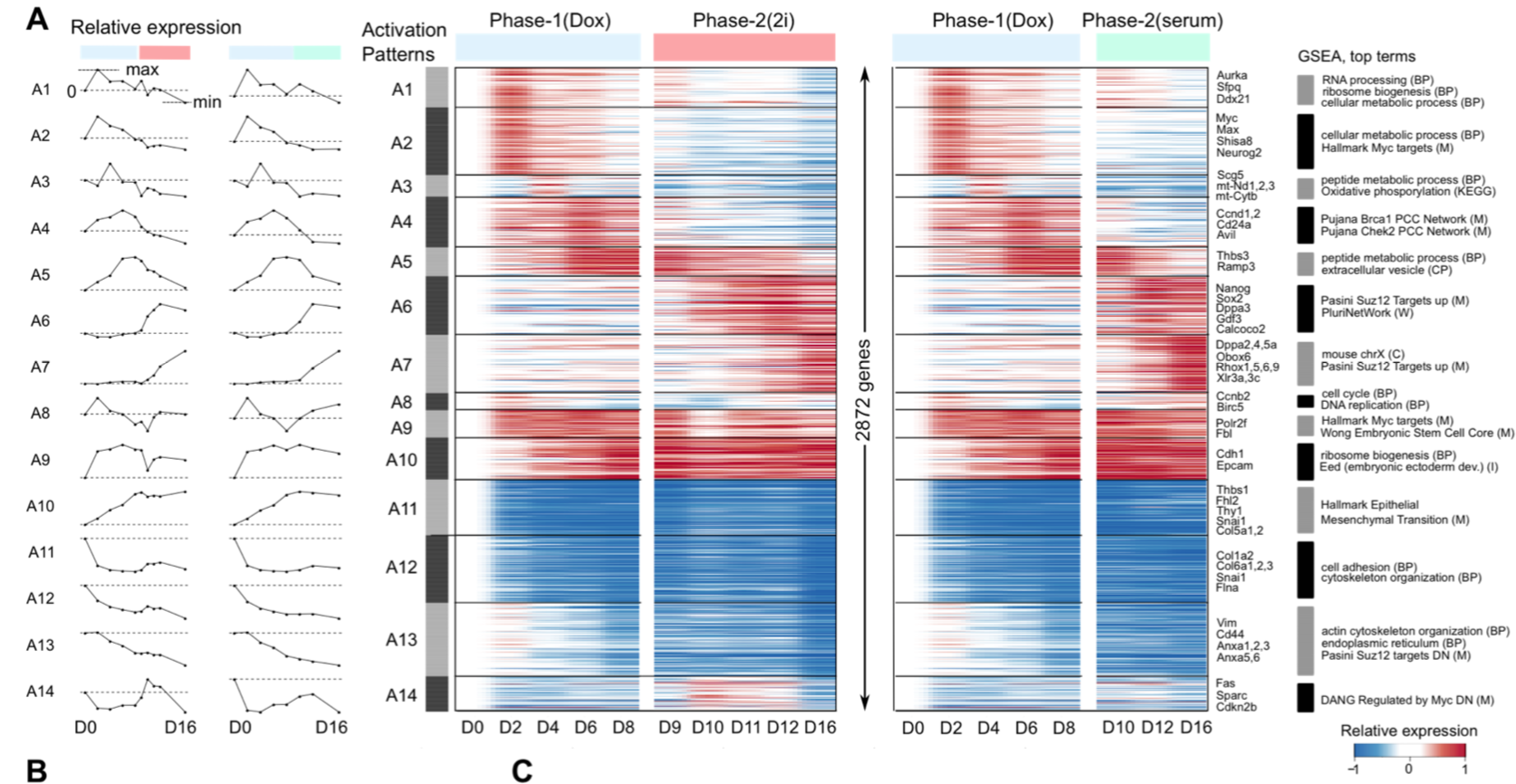
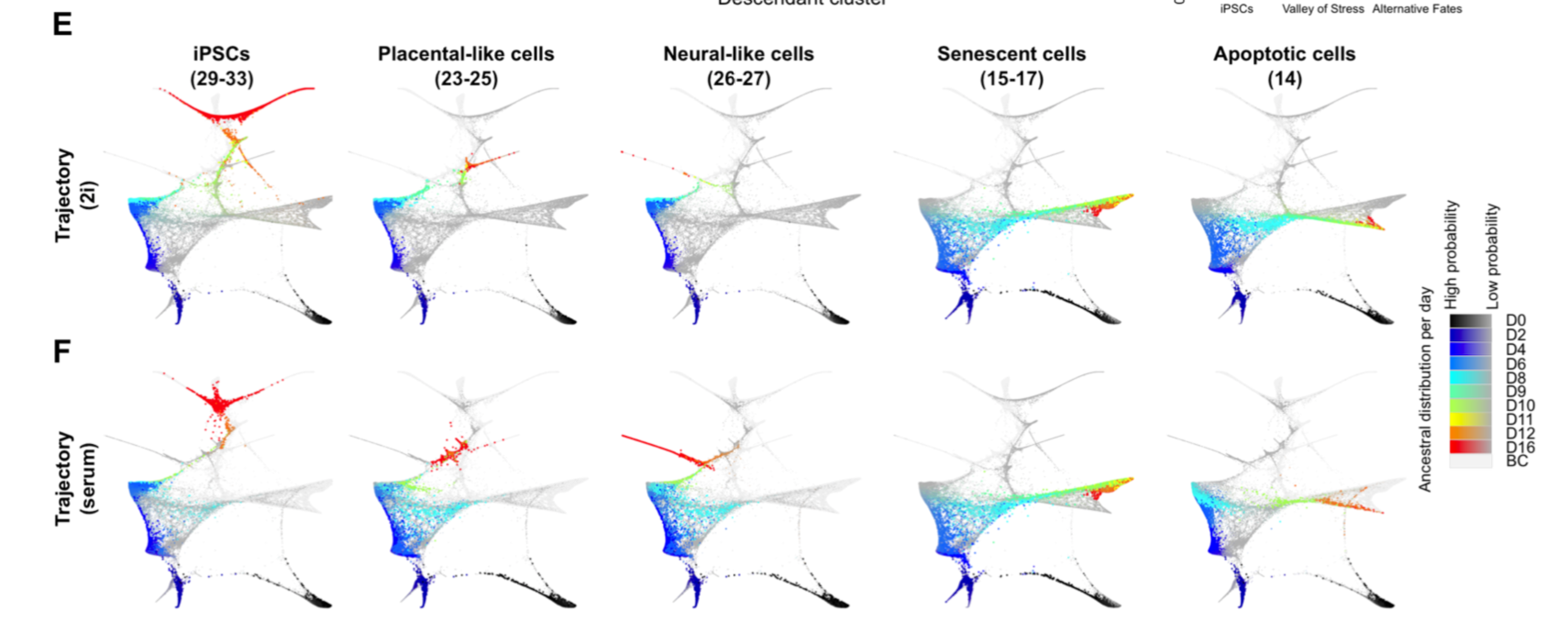
作者提到了we partitioned the 16,339 detected genes into 44 gene modules and the 65,781 cells into 33 cell clusters,那这33个cluster分属于不同的发育时间,它们之间的发育转移关系如下图:
尽管属于同一个发育时间节点,但是仍然是有发育快慢等多样性,同一发育时间点的不同特性的cluster细胞接下来的命运也差异很大:
By day 4, cells display a bimodal distribution of properties that is strongly correlated with their eventual descendants:- cells in cluster 8 (low proliferation, high MEF identity) have 95% of their descendants in the Valley,
- while cells in cluster 18 (high proliferation, low MEF identity) have 94% of their descendants in the Horn
- Cells in cluster 7 show intermediate properties and have roughly equal probabilities of each fate
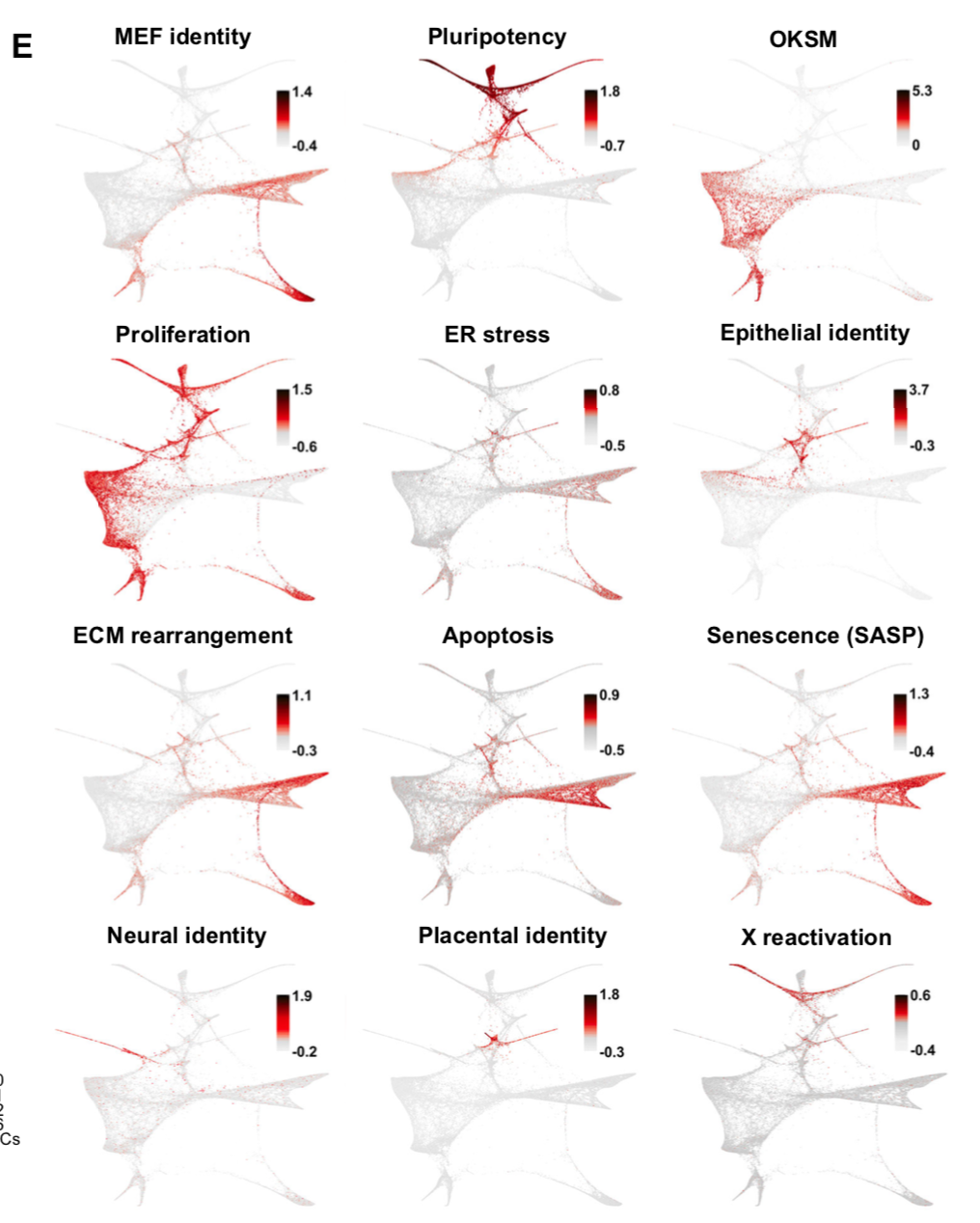
同时挑选了一系列已有的signature来检查它们在发育景观的表现:
当然,也检查了一下marker基因的表达变化情况,就不截图了。重点关注5类细胞
不同发育时期的细胞可以分成33类,写起了太麻烦,作者挑选了值得讲故事的5类细胞:
- placental-like cells (clusters 24 and 25) at day 12
- neural-like cells (clusters 26 and 27) at day 16.
还有iPSCs,Senescent cells, Apoptotic cells.
主要也就是提一下他们的特征,高表达哪些基因,它们的来源和去向问题。3个其它软件的效果
这些软件之所以不适用于作者的这个实验设计出来的数据,因为没有考虑到发育时期这个已知的变量。
虽然在作者写作的时候也已经出来了一款新的软件,但测试了,效果也不如作者自己开发的算法。后记
这篇文章做的数据实在是太大,而且分析要点太多,涉及到的算法也非常多,实在是没办法一一解读,估计得开一个讨论班,五六个人一起解读。
比如下面这个课题组就讨论过;