2015发在BMC Cancer的文章:Anticancer drug sensitivity prediction in cell lines from baseline gene expression through recursive feature selection
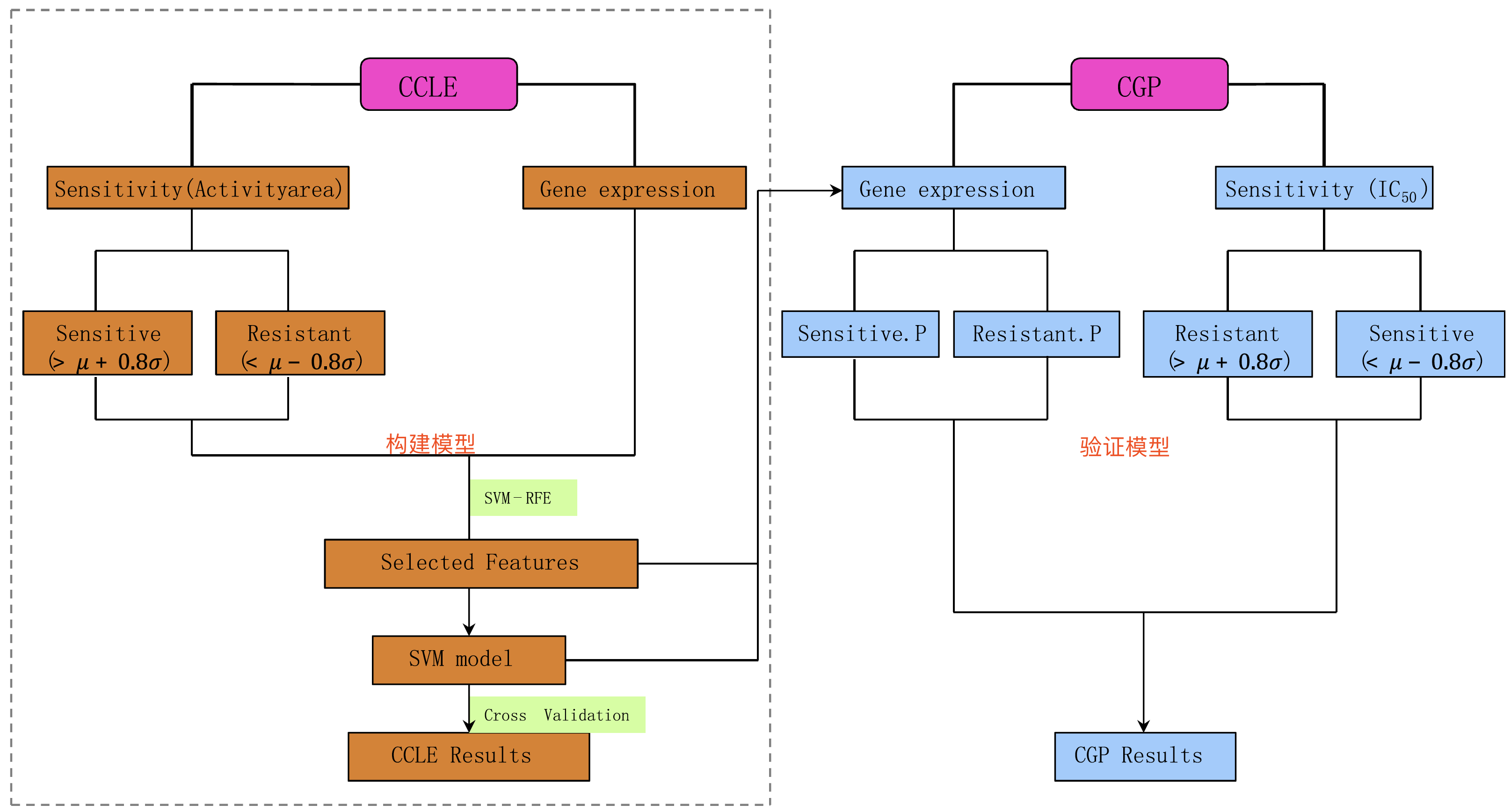
主要就是整合了 Cancer Cell Line Encyclopedia (CCLE) 和 Cancer Genome Project (CGP) 这两个数据库,使用 支持向量机来预测药物反应。
- CCLE (www.broadinstitute.org/ccle/)
- CGP (www.cancerrxgene.org/)
值得一提的是我在我的生信菜鸟团博客也介绍过它们: - 使用CGP数据库的表达矩阵进行药物反应预测
- 详细了解GDSC数据库
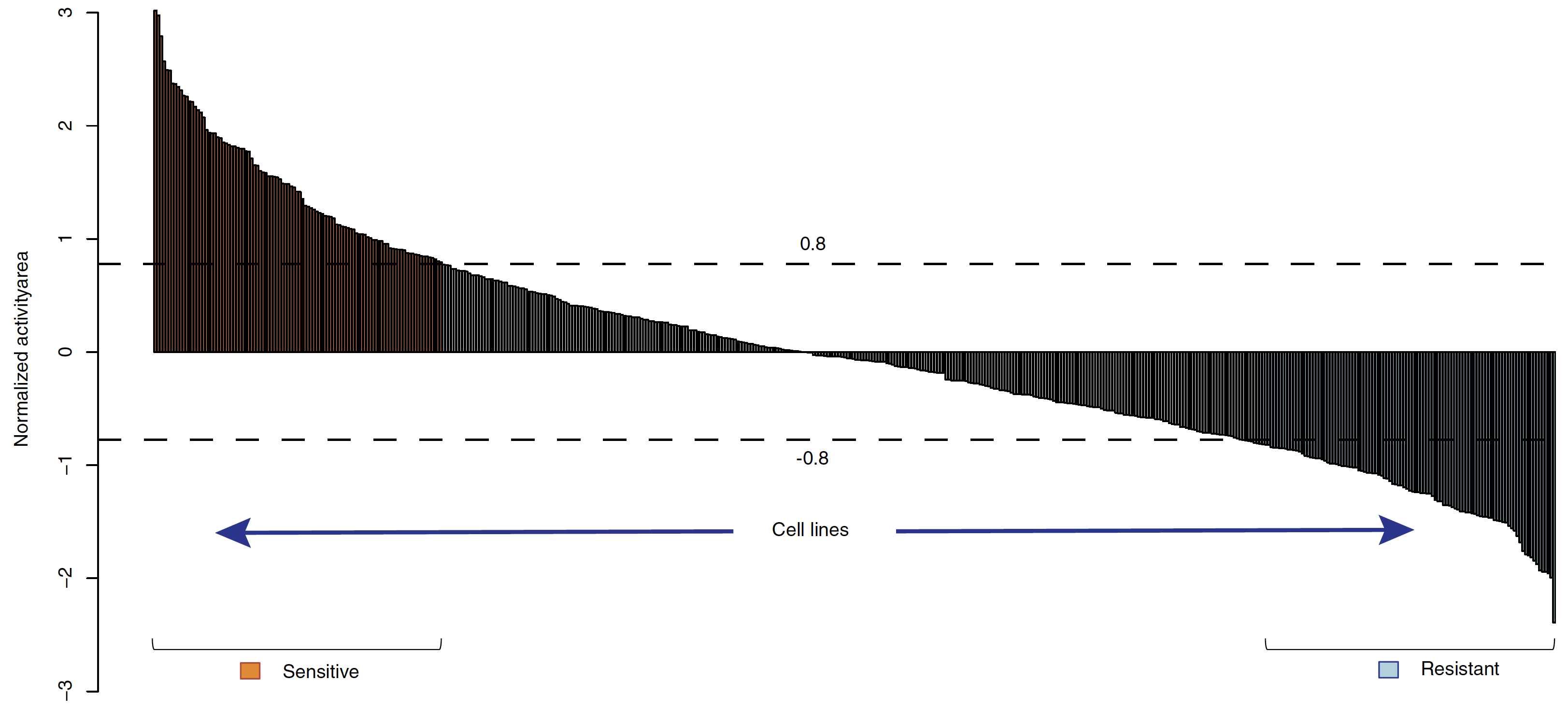
通常人们关心的是药物在病人的反应是敏感还是耐受,而不是具体的某个值,所以是二分类变量,而不是回归。所以作者把CCLE数据库的药敏反应值划分为3个等级,构建SVM模型,可以得到80%的accuracy,还使用了CGP数据库的同样的药物来做验证,效果也很不错。药物反应分类
对每一个药物来说,各种细胞系的反应值先zscore,然后根据0.8倍的sd来进行分类,分成该药物敏感的组,还有耐药的组,处于中间值的那些细胞系剔走。
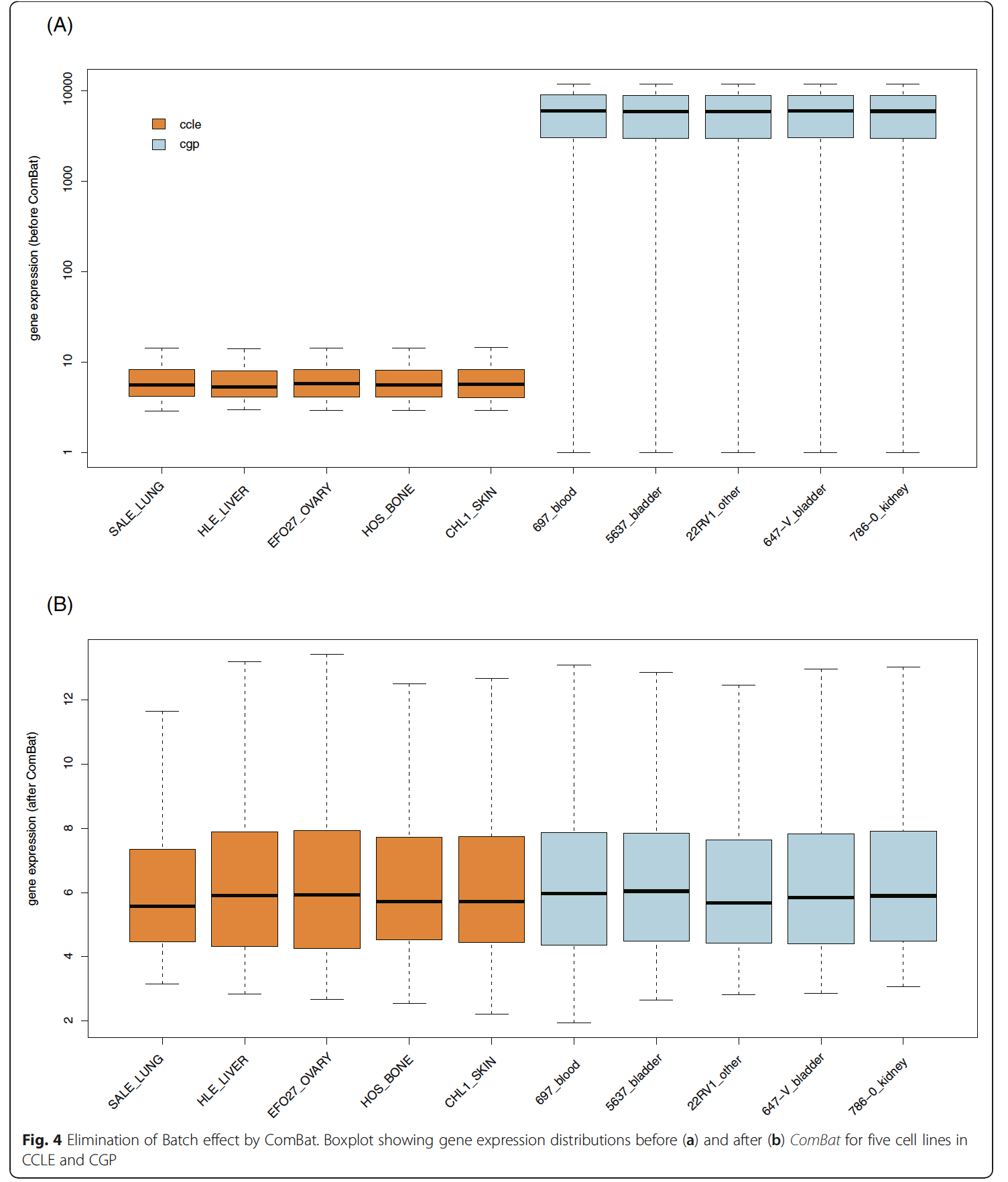
去除批次差异
对 Cancer Cell Line Encyclopedia (CCLE) 和 Cancer Genome Project (CGP) 这两个数据库的表达矩阵,使用ComBat来去除批次效应。
机器学习基本概念
混淆矩阵
- True Positive(真正,TP):将正类预测为正类数
- True Negative(真负,TN):将负类预测为负类数
- False Positive(假正,FP):将负类预测为正类数→误报 (Type I error)
- False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)
1、准确率(Accuracy)
准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。 在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。
2、错误率(Error rate)
错误率则与准确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(TP+TN+FP+FN),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
3、灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
4、特效度(specificity)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
5、精确率、精度(Precision)
表示被分为正例的示例中实际为正例的比例。
6、召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
7、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均
8、其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
参考:https://blog.csdn.net/quiet_girl/article/details/70830796每个药物都有单独的SVM模型
模型效果还不错,By 10-fold cross validation, accuracies of our model are around 80 % for most drugs in CCLE, and the highest accuracy of 91.73 % was attained for a pathway targeted compound, the topoisomerase 1 inhibitor Irinotecan.
这里作者只是统计了accuracy,其实蛮片面的,应该是考虑其它机器学习指标。
而且,上面的是在自己的数据集做验证,还应该在另外一个独立的数据集继续验证SVM模型效果。
虽然只测试了11个药物,但是效果惨不忍睹: - 3 of these 11 drugs (AZD6244, Erlotinib and PD-0325901) achieve a relatively good performance of AUC from 0.57 to 0.7
- the rest eight drugs only give the AUC values around 0.5
同时,作者也把顺序反过来分析了,在CGP数据库来构建模型,然后去CCLE数据库验证。
还有就是两个模型都会对自己的数据库的基因进行排序,比较了两次构建模型的top1500基因的重合情况,如下:
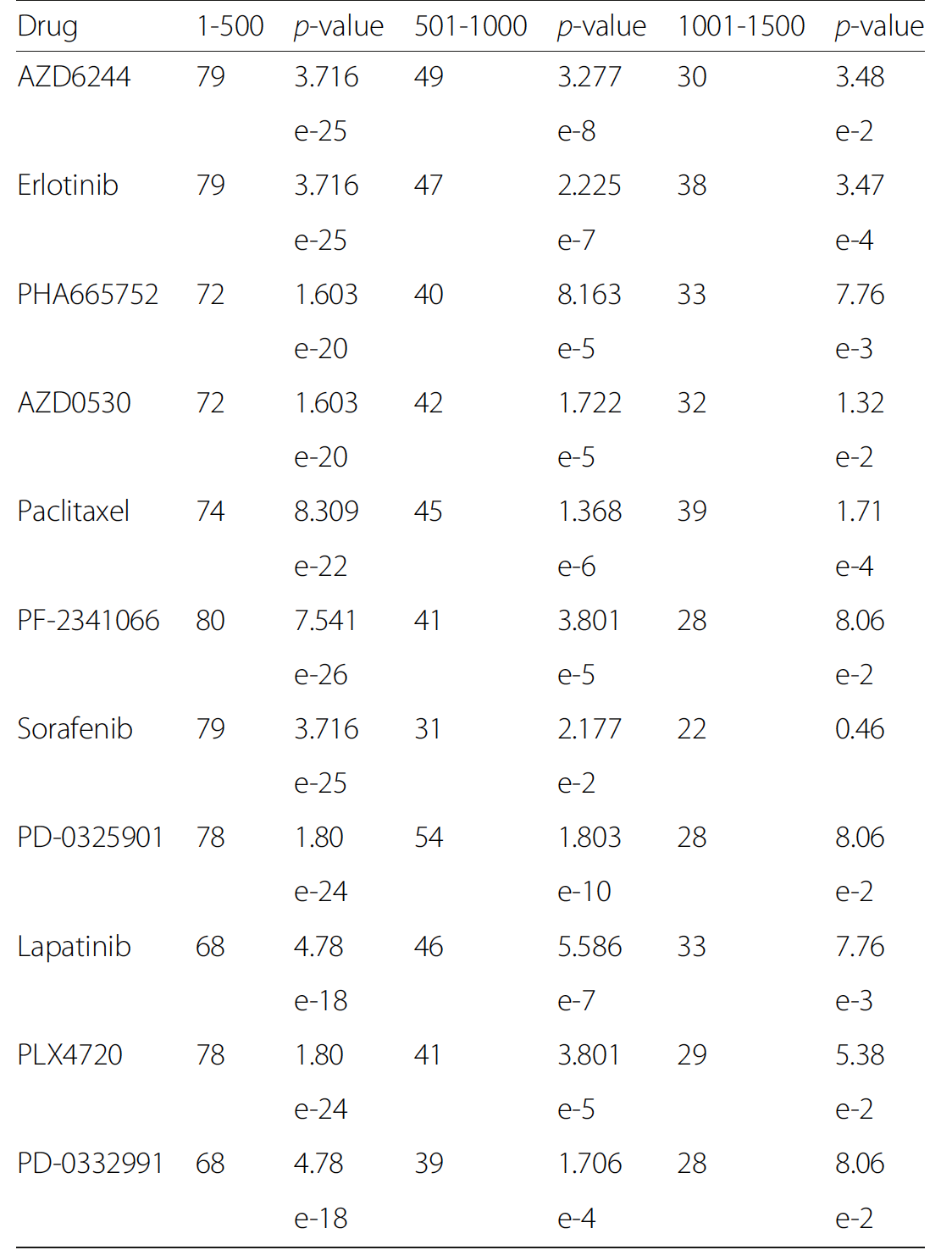
个人觉得不好。
而且,这篇文章很明显比不上 Clinical drug response can be predicted using baseline gene expression levels and in vitro drug sensitivity in cell lines ,Genome Biology 2014 https://doi.org/10.1186/gb-2014-15-3-r47