大家看我在生信技能树发布的各个NGS组学的视频教程, 基本都是随手找到一篇文章,就去查询其原始数据,通常是在NCBI的SRA,然后使用prefetch下载sra文件,有的时候还好使用aspera进行加速。
最近要开一个肿瘤外显子实战线下课程,想起以前看到发布在 Proc Natl Acad Sci U S A. 2015 Nov的文章Extremely high genetic diversity in a single tumor points to prevalence of non-Darwinian cell evolution , 研究者对一个肿瘤 hepatocellular carcinoma (HCC) 样品测序超过300个部位,其中23个进行WES测序。但是研究者把数据上传到了GSA (Genome Sequence Archive),如下:

关于GSA
大家可以理解为NCBI的SRA数据库,通常我们看组学文章,都是找到其SRA的ID号,然后去NCBI的SRA下载的。
GSA (Genome Sequence Archive)是2015年底,中科院北京基因组研究所生命与健康大数据中心开发的原始组学数据归档库。数据模型和数据格式遵照INSDC标准,在功能上等同于NCBI的SRA,EBI的ENA和DDBJ的DRA。
感兴趣的可以自行阅读其官方说明:https://mp.weixin.qq.com/s/ma6GOcBHyYgUHBkQLOuDHQ
根据项目编号拿到
毫无疑问,把我们在文章拿到的编号输入GSA的查询窗口:

就可以定位到其项目详情;
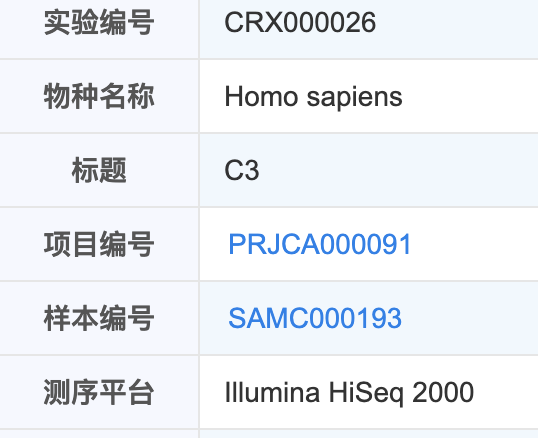
网页版 https://bigd.big.ac.cn/gsa/browse/CRA000004>
FTP版:ftp://download.big.ac.cn/gsa/CRA000004
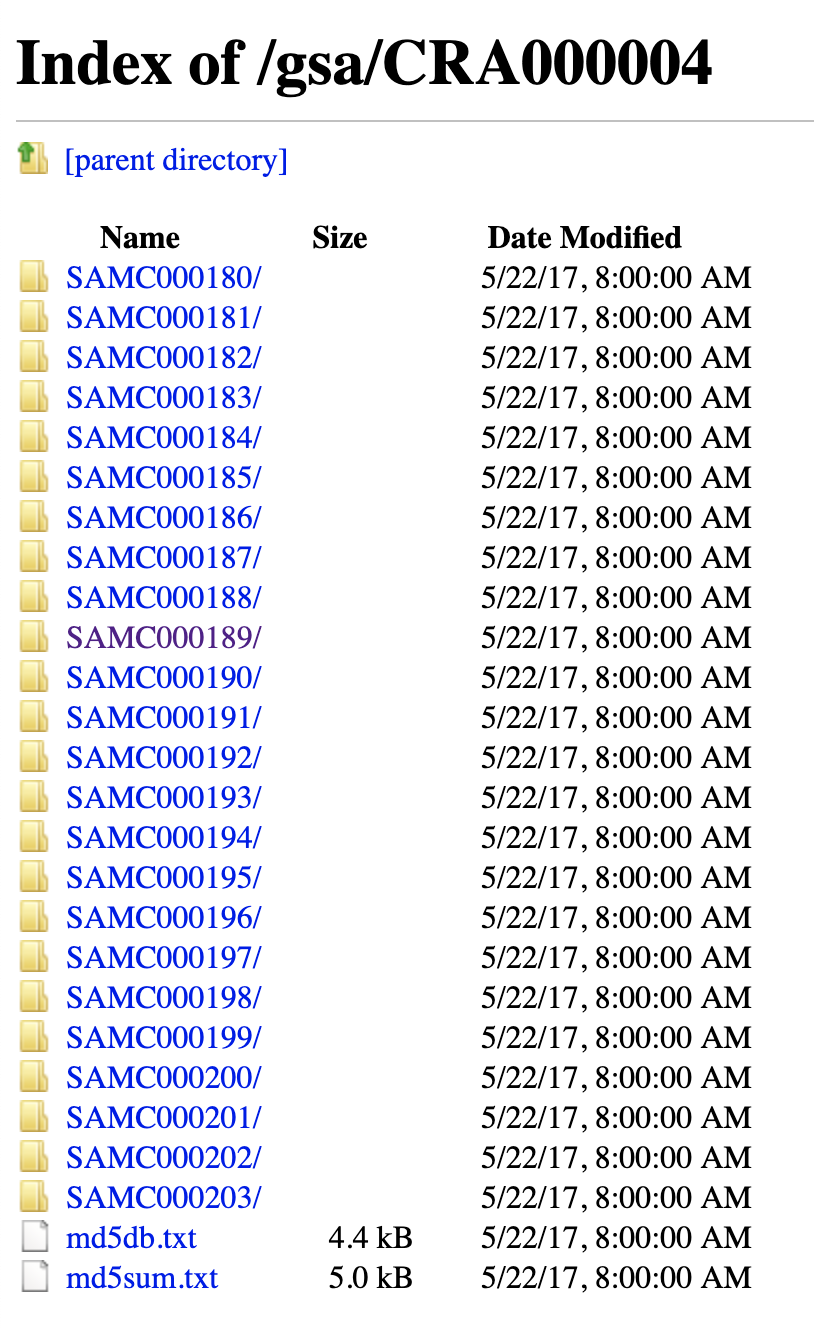
批量下载ftp数据
上面的链接要批量下载,可以参考我四年前在生信菜鸟团的教程:用wget批量下载需要认证的网页或者ftp站点里面的pdf文档
wget -c -r -np -k -L -p ftp://download.big.ac.cn/gsa/CRA000004/
参数详解如下 :
-c 断点续传
-r 递归下载,下载指定网页某一目录下(包括子目录)的所有文件
-np 递归下载时不搜索上层目录,一定要加上这个参数,不然会下载太多东西的)
-k 将绝对链接转为相对链接,下载整个站点后脱机浏览网页,最好加上这个参数
-L 递归时不进入其它主机,
或者写脚本工具文件名规律来wget分开下载。
echo ftp://download.big.ac.cn/gsa/CRA000004/SAMC000{180..203} |tr ' ' '\n' |awk '{print $0"\n"$0}' > 1
echo /CRX0000{13..36} |tr ' ' '\n'|awk '{print $0"\n"$0}' > 2
echo /CRR0000{08..31} |tr ' ' '\n' |awk '{print $0"\n"$0}' > 3
echo /CRD0000{08..55}.tar.gz |tr ' ' '\n' > 4
paste -d " " 1 2 3 4 |sed 's/ //g' > address.txt
上面代码有一个小坑,就是 08 这个字符串在MAC的shell里面会被识别为数值。
一般国内的服务器下载速度可以达到10M/s
然后,一般来说,下载命令需要使用 nohup挂在后台哦。
接下来走肿瘤外显子流程
GATK4找肿瘤点突变教程