现在流行的单细胞转录组测序是10X的,通常一个样本就可以达到好几千的细胞,所以一次10个样本的实验,拿到上万个细胞非常正常。
很容易通过 monocle, seurat, scater 等一站式单细胞转录组处理工具来进行降维聚类分群,如下:
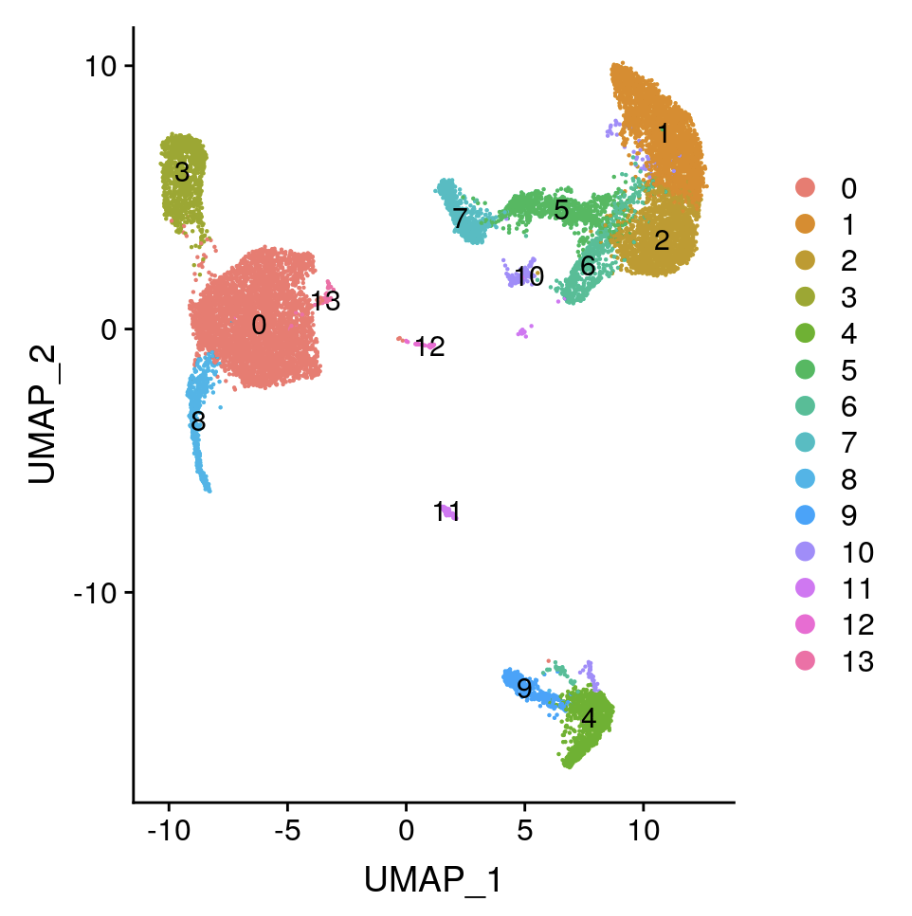
这样的算法上的不同细胞群体,肯定是需要找到其对应的生物学意义。
通常是依赖Marker gene来定义每一个类群,可以是GO/KEGG数据库功能富集,虽然这样会比较粗糙,适用于类群不多,而且差异非常大的情形。但是上面例子的细胞类群太多,需要其它方法,通常是根据已经有人整理好的数据库,做如下映射。
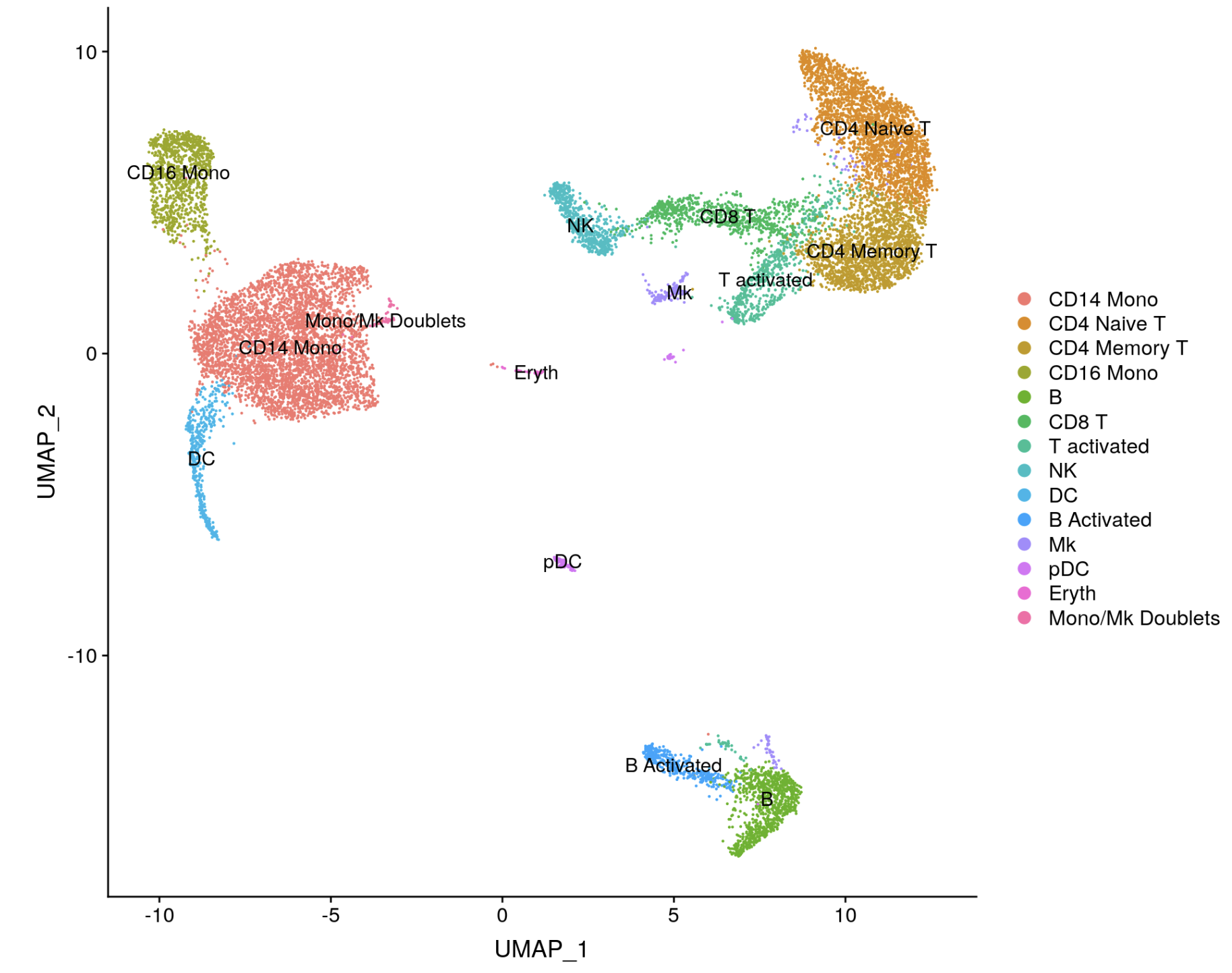
这里推荐两个:
CellMarker数据库
这里值得推荐的是哈尔滨医科大学 Yun Xiao老师等在2019年1月份发表于核酸研究 (Nucleic Acids Research)数据库专刊的工作,访问地址: http://biocc.hrbmu.edu.cn/CellMarker
该团队通过梳理100,000+发表的文献,梳理出人的158个组织 (亚组织)的467个细胞类型的13,605个Marker基因,和鼠的81个组织 (亚组织)的389个细胞类型的9, 148个Marker基因。
signatureDB
来源于文章:Genetics and Pathogenesis of Diffuse Large B-Cell Lymphoma. 发表2018新英格兰杂志。
https://www.ncbi.nlm.nih.gov/pubmed/29641966
数据可以直接下载 ,Signature Database: