前面我们提到了在我们的shiny服务器部署一个RNA-seq下游分析网页工具,虽然说因为时间关系没办法给它写一步步教程,而且的确类似的工具也太多, 写教程的时间付出并不经济。那我们再介绍一个shinyGEO吧,跟前面的Shiny-Seq名字很相似,应该是主攻芯片数据分析,一个是主动测序数据处理,都是基于表达矩阵的。
一句话描述shinyGEO功能
查看感兴趣的基因在感兴趣的数据集里面,是否有分组后的表达差异或者生存分析的统计学显著性!
所以全文只有一个配图:
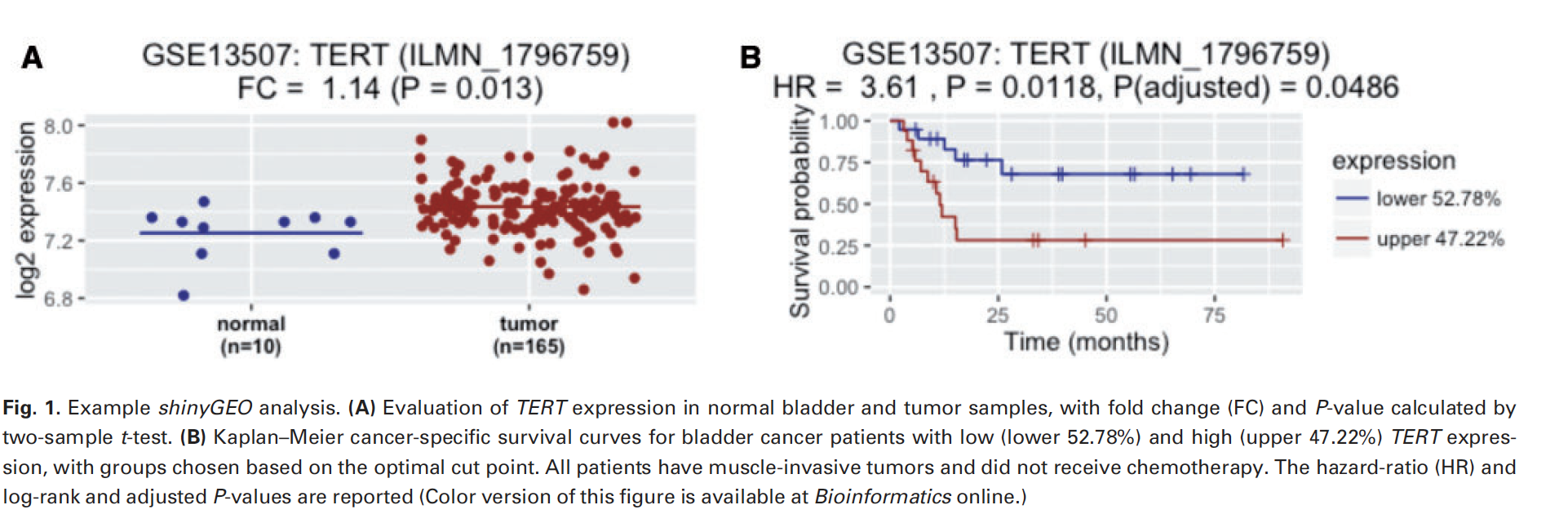
但是它并不提供芯片探针的ID注释,当然,缺陷实在是有点多,只能说是一个好的学习shiny网页工具制作的例子,并不算是完善的工具。
shinyGEO比较有趣的是,它本身被打包成为了一个R包,同时提供一个网页工具。发表在:Bioinformatics. 2016 Dec 1; 题目是:shinyGEO: a web-based application for analyzing gene expression omnibus datasets.
这两个工具名字类似:
- shinyGEO:零编程基础分析GEO表达数据
- scanGEO:整合多个GEO数据集
大家可以对比学习!我们下次再介绍scanGEO的用法。
部署shinyGEO需要安装一些R包
基本上是需要设置R包安装镜像的,参考:http://www.bio-info-trainee.com/3727.html 其中 install_github 函数需要从GitHub下载,会有其它难度,我们以前在生信技能树也分享过教程,大家可以自行搜索查看。
因为我是安装在自己的Ubuntu服务器里面,所以其实还蛮难的,各种报错,斗智斗勇的解决掉了。如果你不会shiny,就不用管它的部署问题。下载源代码,一步步安装即可,log目录是 /var/log/shiny-server 只有同属于shiny组的用户才能访问,只有在需要调试代码的时候才需要去查看默认程序存放在:/srv/shiny-server ,我们的这个网页工具也是
rm(list = ls())
options()$repos
options()$BioC_mirror
options(BioC_mirror="https://mirrors.ustc.edu.cn/bioc/")
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
options()$repos
options()$BioC_mirror
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install('affy')
library(devtools)
install_github("jasdumas/shinyGEO")
这个网页工具开发的很棒,比较容易部署,虽然说,依赖的R包也不少,使用下面的代码批量安装那些缺失的包,如下:
packagesReq <- c("DT",
"shiny",
"GEOquery",
"Biobase",
"reshape2",
"survival",
"shinyBS",
"GGally",
"ggplot2",
"shinyAce",
"knitr",
"rmarkdown",
"RCurl",
"shinyjs",
"survMisc",
"shinyAce",
"RCurl",
"shinyBS",
"shinydashboard",
"devtools")
packToInst <- setdiff(packagesReq, installed.packages())
packToInst
if(T){
lapply(packToInst, function(x){
BiocManager::install(x,ask = F,update = F)
})
}
lapply(intersect(packagesReq, installed.packages()),function(x){
suppressPackageStartupMessages(library(x,character.only = T))
})
library(rJava)
大部分,都是shiny相关的R包,非常值得学习,如果确定要走网页开发这条路。
网页工具用法
网页工具部署成功后,使用起来非常简单,输入一个自己需要处理的表达矩阵数据集即可,比如:GSE10009:
实际上就是调用GEOquery包去GEO数据库下载文件,所以这个非常慢,因为中国大陆的网络问题。我以前在生信技能树的芯片万能解决方案里面就有这个解决方案:
欢迎大家提交GEO数据库中国区镜像试用体验,也可以加入交流群:4年前的TCGA重磅资料你学了 这个工具我也准备修改源代码,让它使用我的下载链接,不过这个星期在马来西亚休假,所以不是很想动手去写代码,是时候休息几天了。
有了数据集,接下来使用的分析就中规中矩啦
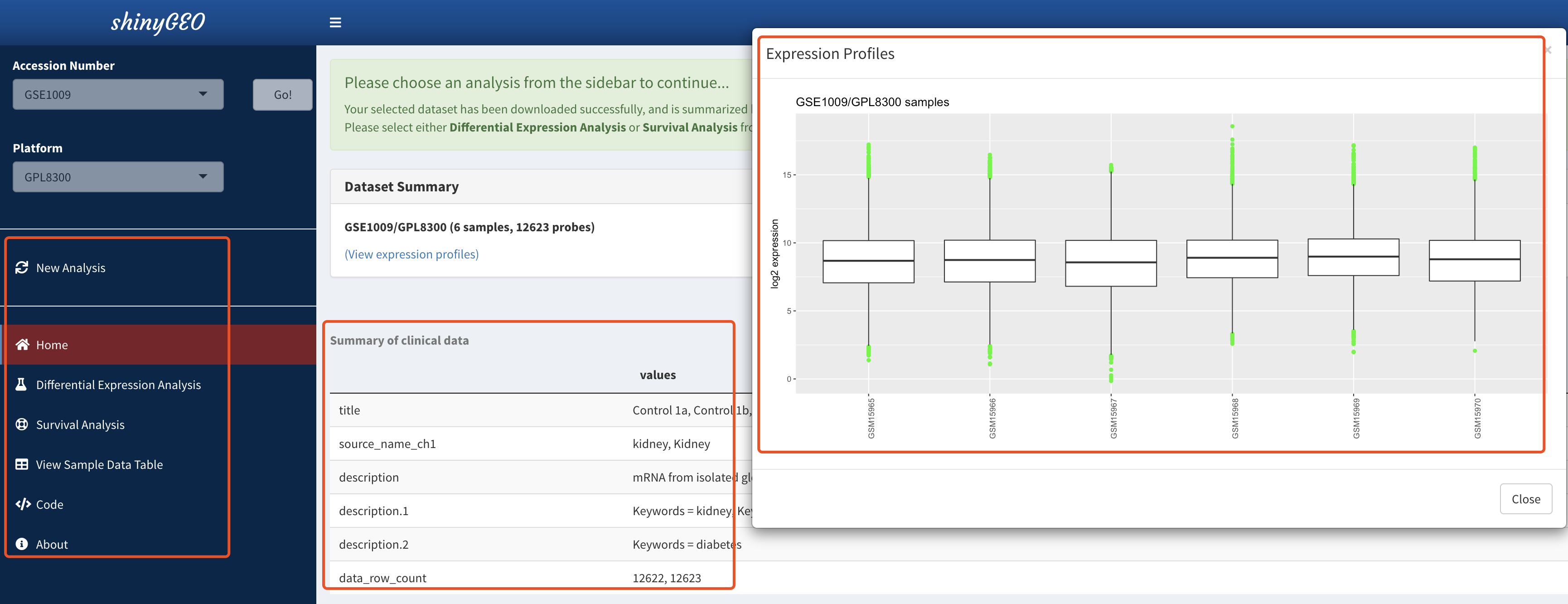
首先肯定是分组:
也许是我没有看仔细,并没有全局差异分析,只能是选择某个探针/基因进行处理分析!
而且探针并没有注释到基因,也不可能进行后续的GO/KEGG注释。
该工具的优点
首先,整体页面布局很美观,采用的主题符合我的审美,而且每个功能分步骤安放很容易理解,新的步骤衔接起来比较容易理解。
尤其那些shiny插件包用的出神入化,绝对是初学者宝藏