最近在系统性整理DNA甲基化相关文献,也顺便在生信技能树分享教程:
- 甲基化的一些基础知识
- 甲基化芯片的一般分析流程
有意思的是,甲基化分析其实和普通的mRNA表达矩阵分析有很多概念问题是无法迁移的,包括质量控制,WGCNA分析,哪怕是简单的差异分析都有区别。标准差异分析系列教程
虽然说拿到甲基化信号值矩阵后,仍然是可以走标准分析流程,火山图,热图,GO/KEGG数据库注释等等。这些流程的视频教程都在B站和GitHub了,目录如下:
- 第一讲:GEO,表达芯片与R
- 第二讲:从GEO下载数据得到表达量矩阵
- 第三讲:对表达量矩阵用GSEA软件做分析
- 第四讲:根据分组信息做差异分析
- 第五讲:对差异基因结果做GO/KEGG超几何分布检验富集分析
- 第六讲:指定基因分组boxplot指定基因list画热图
感兴趣可以细读表达芯片的公共数据库挖掘系列推文 ; - 解读GEO数据存放规律及下载,一文就够
- 解读SRA数据库规律一文就够
- 从GEO数据库下载得到表达矩阵 一文就够
- GSEA分析一文就够(单机版+R语言版)
- 根据分组信息做差异分析- 这个一文不够的
- 差异分析得到的结果注释一文就够
但是差异分析大家还是首先limma,而limma这个包本来是针对log后的表达矩阵设计的,这样的话,如果我们的输入是甲基化信号矩阵,实际上出来的结果是有问题的。甲基化信号值的生物学意义
首先甲基化信号值通常是贝塔值,是介于0到1之间的连续变量。
公式计算: 平均β=信号B /(信号A +信号B + 100)
通过计算甲基化(信号A)和未甲基化(信号B)等位基因之间的强度比来确定DNA甲基化水平(β值)。
具体地,β值是由甲基化(M对应于信号A)和未甲基化(U对应于信号B)等位基因的强度计算的,荧光信号的比率β= Max(M,0)/ [Max( M,0)+ Max(U,0)+ 100]。
因此,β值的范围从0(完全未甲基化)到1(完全甲基化)
一般来说,具体的β值的意义是: - 任何等于或大于0.6的β值都被认为是完全甲基化的。
- 任何等于或小于0.2的β值被认为是完全未甲基化的。
- β值在0.2和0.6之间被认为是部分甲基化的。
差异分析的问题所在
我发现发表在Mol Med Rep. 2019 Jul; 的文章doi: 10.3892/mmr.2019.10294 就提到了对甲基化信号矩阵做差异分析后,选取什么样的阈值来判定是统计学显著的高甲基化位点或者低甲基化位点,如下:

这个log2FC看得我心疼,都0.1了。
仔细看了看,其实研究者走完limma流程之后呢,其实是把全部的logFC值给画了density图,才决定使用什么样的阈值。听起来还蛮有统计学道理的!
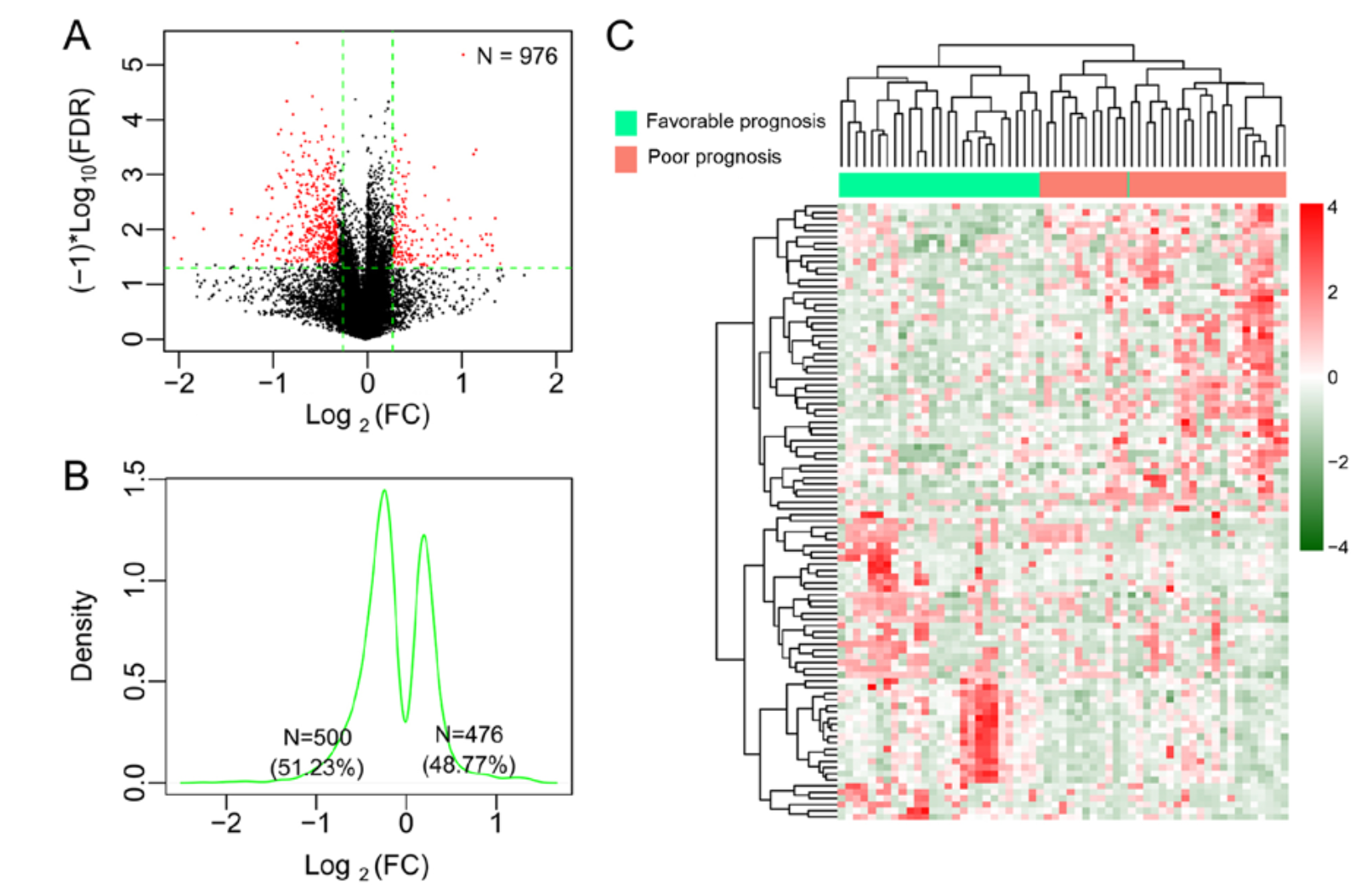
亲爱的读者,你觉得呢?甲基化信号矩阵差异分析免费做
我们推文里面提到的各种各样的数据分析环节都是我非常有经验的,比如我在lncRNA的一些基础知识 ,和lncRNA芯片的一般分析流程 介绍过的那些图表,以及下面的目录的分析内容 对我来说是举手之劳,希望可以帮助到你!
- 转录组数据分析的4个维度认识(数据分析继续免费哦) RNA-seq数据的2个分组差异分析,热图,PCA图,火山图等等
- 根据感兴趣基因看肝癌免疫微环境的T细胞亚群差异 条形图或者箱线图
- 查看感兴趣基因的甲基化水平和RNA表达水平(数据分析免费做)相关性 散点图或者箱线图
- 我不相信kmplot这个网页工具的结果(生存分析免费做)
- 单基因GSEA分析策略(数据分析免费做活动继续)
- 干扰一个基因然后分析全局基因表达其实是无法定位该基因完整功能(春节免费数据分析活动继续)
- log与否会改变rpkm形式表达矩阵top的mad基因列表 WGCNA分析免费做
同样的,本次活动我可以帮你免费做一次甲基化信号矩阵差异分析,但是呢,我也没办法保证结果咋样,有时候数据集就是这样。而且,你需要挑选一下你的阈值哦!
还是老规矩,发送数据分析要求,以及简短的项目描述到我的邮箱 jmzeng1314@163.com
邮件正文最好是加上你是啥时候认识生信技能树的哦,或者其它一些寒暄的话,自我介绍也行。主要是考虑到可能想免费分析数据的朋友很多,所以会根据你的来信,我主观判定一个优先级哦。目前我有20多个愿意长期在我的指导下进行数据探索的学徒,等我的团队扩大到200人,我们应该是可以做到数据分析全部免费,敬请期待哈! - 广州专场(全年无休)GEO数据挖掘课,带你飞(2.8-2.9)