四年前我写过介绍GEO和SRA数据库的推文 ;
- 解读GEO数据存放规律及下载,一文就够
- 解读SRA数据库规律一文就够
其实就是耗费一点时间去摸索如何在这两个数据库里面查询下载自己感兴趣的文章的数据。注意4个层级结构,是:SRP(项目)—>SRS(样本)—>SRX(数据产生)—>SRR(数据本身)
同样的数据是project,层级是PRJNA —> SAMN
链接如下: - https://www.ncbi.nlm.nih.gov/sra?term=SRP078156 查看样本列表
- https://www.ncbi.nlm.nih.gov/Traces/study/?acc=SRP078156 下载样本ID表格
- https://www.ncbi.nlm.nih.gov/bioproject/PRJNA327548
- https://www.ncbi.nlm.nih.gov/sra?term=SAMN05341212
最近一个学徒完成我的随机任务,也是需要从sra数据库下载fastq文件,他并没有采取Traces/study/?acc=SRP230801 的后缀,而且采取Traces/sra/?study=SRP230801的后缀,看起来差异很小,但是进入了完全不同的数据浏览界面: - 链接是:https://trace.ncbi.nlm.nih.gov/Traces/sra/?study=SRP230801
我也查看了一下,鼠标无意中放在了fq.gz文件,发现它的下载链接居然是亚马逊云。
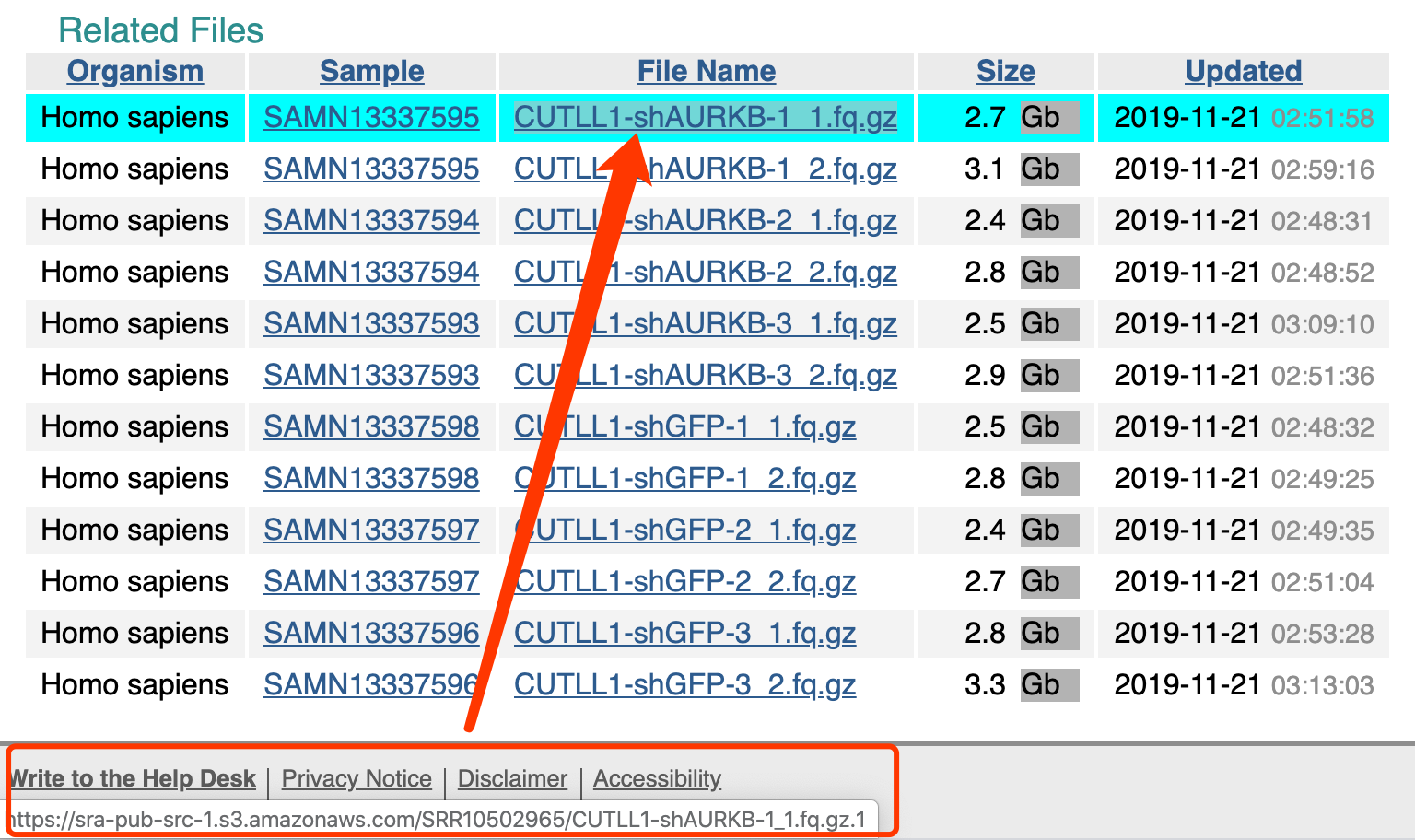
而且fq.gz文件,样本名标记的非常清楚,跟GEO界面一一对应着 - https://www.ncbi.nlm.nih.gov//geo/query/acc.cgi?acc=GSE140739
无需下载sra文件,再转为fq文件,还得注意文件名,非常方便!GSM4182954 CUTLL1-shGFP-1 GSM4182955 CUTLL1-shGFP-2 GSM4182956 CUTLL1-shGFP-3 GSM4182957 CUTLL1-shAURKB-1 GSM4182958 CUTLL1-shAURKB-2 GSM4182959 CUTLL1-shAURKB-3更重要的是,在国外,很多软件工具是直接部署在亚马逊的,意味着中间的网速基本上是无限的。
类似于大家在腾讯云阿里云华为云使用他们的内部数据: - https://www.amazonaws.cn/ec2/pricing/ec2-linux-pricing/ (亚马逊中国,aws)
- https://buy.cloud.tencent.com/price/cvm#tab0-list1 (腾讯云服务器)
- https://www.huaweicloud.com/pricing.html#/ecs (华为云服务器)
- https://cn.aliyun.com/price/product#/ecs/detail (阿里云服务器)
- https://cloud.google.com/compute/pricing?hl=zh-CN (谷歌云服务器)
- 其它,美团云,百度云等等就不一一展示
海外使用云服务器做生物信息学分析应该是非常方便了
需要学习一下生信菜鸟团的关于生物信息学环境搭建的讨论
- 可重复的生信分析系列一:Docker的介绍
- 可重复的生信分析系列二:Conda的介绍
如果你有自己的经验,欢迎留言分享哦!文末友情宣传
强烈建议你推荐给身边的博士后以及年轻生物学PI,多一点数据认知,让他们的科研上一个台阶:
- 底裤价转录组产品线(还送数据分析培训)(八九百一个样品)
- 三维基因组学分析实战培训班,线上直播课,2天仅需399(生信技能树粉丝特权价格)
- 生信技能树的2019年终总结 ,你的生物信息学成长宝藏
- 2020学习主旋律,B站74小时免费教学视频为你领路