我在生信技能树公众号发的《生信分析人员如何系统入门R(2019更新版)》给初学者的六步系统入门R语言,知识点路线图如下:
- 了解常量和变量概念
- 加减乘除等运算(计算器)
- 多种数据类型(数值,字符,逻辑,因子)
- 多种数据结构(向量,矩阵,数组,数据框,列表)
- 文件读取和写出
- 简单统计可视化
- 无限量函数学习
考虑到有几个细节知识点大家自学会有一点困难,我们生信技能树团队恰好有时间,就做几次公益授课,带领大家一起学习哈。
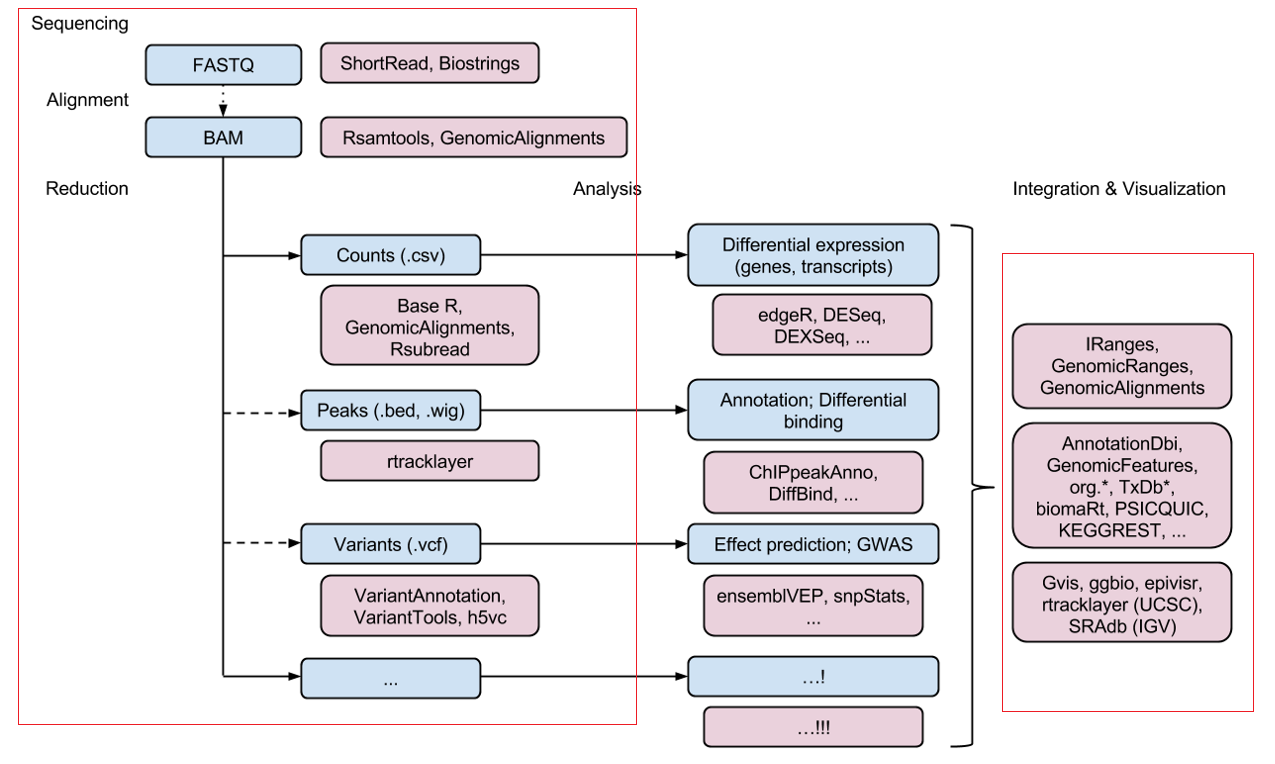
今天带来的是R包集合Bioconductor及高通量数据处理中数据呈现、输入输出以及大家比较关注的注释的代表性R包介绍。
Bioconductor用于分析和理解高通量基因组数据,其在统计上有严谨的方法对设计的实验进行微阵列预处理和分析,并且对生物信息学处理有综合和可重复的方法而获得了很高的可信度。
Bioconductor现含749+R包,包用于表达和其他微阵列、序列分析、流式细胞术、成像和其他领域。
课程需要的基础知识
需要自行看配套书籍《R语言之书》,理解下面的4个知识点单元:
- 了解常量和变量概念
- 加减乘除等运算(计算器)
- 多种数据类型(数值,字符,逻辑,因子)
- 多种数据结构(向量,矩阵,数组,数据框,列表)
课程主要的内容
1.高通量测序工作流程简介
概述
产生的数据
研究的问题
2.高通量测序数据的呈现形式
S3和S4类用来表示更复杂的数据结构
1)表示S3和S4对象
2)如何创建S3和S4对象?
## S3对象
x <- rnorm(1000, sd=1)
y <- x + rnorm(1000, sd=.5)
fit <- lm(y ~ x) # 线性回归方程
fit #S3对象
anova(fit)
sqrt(var(resid(fit)))
class(fit)
序列数据呈现的R包
1)安装R包
2)使用实例 GenomicRanges
数据输入和输出的R包
常见数据格式简介及处理的R包 rtracklayer
3.基因和基因组注释
1)以基因为中心的R包 Org.*
2)以基因组为中心的R包 GenomicFeatures
3)以网络为基础的R包 biomaRt
## Org.*的不同物种注释的包
org.Hs.eg.db
org.Mm.eg.db
org.Rn.eg.db
org.Sc.sgd.db
org.Dm.eg.db
org.At.tair.db
org.Dr.eg.db
org.Ce.eg.db
org.Bt.eg.db
org.Gg.eg.db
org.Cf.eg.db
org.Ss.eg.db
## biomaRt进行ID转换
affyids=c("202763_at","209310_s_at","207500_at")
getBM(attributes = c('affy_hg_u133_plus_2', 'hgnc_symbol', 'chromosome_name',
'start_position', 'end_position', 'band'),
filters = 'affy_hg_u133_plus_2',
values = affyids,
mart = ensembl)
听课方式
老规矩,“R语言公益群”群的钉钉群号:32524659暂定(2020-5-14暂定,晚上八点,不见不散)