有了生物信息学数据分析,生命科学领域研究从此大不一样,不再是玄学。而且很多高质量的CNS文章,还好把配套文章的图表的数据和代码全部开源。比如前些天我们公布了唐医生推荐的《这个20G的单细胞项目数据和代码的压缩包有什么(python数据分析典范)》,很多粉丝表示从来没有想过居然需要学python,不是说好的基于R语言的统计可视化吗?
强烈要求我们推荐纯粹的R语言的文献图表复现全套代码,其实很容易检索到,2020年7月仅仅是单细胞高分(IF>9)文章就有一百多篇,全部的单细胞相关文章有六七百篇了。一般来说,公布代码,都是在GitHub,所以只需要关键词合适,搜索十几篇带有配套文章的图表的数据和代码很正常。
我从这些CNS文章里面精挑细选了一个非常值得大家花时间跟下去的,就是新鲜出炉的发表在CELL杂志的:Therapy-Induced Evolution of Human Lung Cancer Revealed by Single-Cell RNA Sequencing 。 全套代码在:https://github.com/czbiohub/scell_lung_adenocarcinoma
而且是以rmarkdown形式组织的条理清楚,目录如下:
01_Import_data_and_metadata.Rmd
02.1_Create_Seurat_object_neo_osi.Rmd
02_Create_Seurat_object.Rmd
03.1_Subset_and_general_annotations.Rmd
03_Merge_in_NeoOsi.Rmd
03_Subset_and_general_annotations.Rmd
IM01_Subset_cluster_annotate_immune_cells.Rmd
IM02_immune_cell_changes_with_response_to_treatment.Rmd
IM03_Subset_cluster_annotate_MFs-monocytes_LUNG.Rmd
IM04_Subset_cluster_annotate_T-cells_LUNG.Rmd
IM05_Immune_cells_across_pats_with_multiple_biopsies.Rmd
IM06_Combine_Immune_and_nonImmune_annotations.Rmd
NI01_General_annotation_of_nonimmune_cells.Rmd
NI02_epi_subset_and_cluster.Rmd
NI03_inferCNV.Rmd
NI04_Cancer_cells_DEgenes.Rmd
NI05_Annotation_of_Nontumor_epi.Rmd
NI06_mutation_analysis.Rmd
NI07_TH226_cancercell_analysis.Rmd
NI08_Gene_expression_plotting.Rmd
NI09_AT2_sig_compare.Rmd
NI10_TCGA_clinical_outcomes.Rmd
NI14_qpcr_analysis.Rmd
NI15_multiplex_IF_analysis.Rmd
NI16_cancercell_EGFR_ALK.Rmd
NI16_regression_analyses.Rmd
NI17_cancercell_PDsigs.Rmd
V01_various_small_plots.Rmd
每个步骤都清清楚楚,主要是是单细胞基础10讲相关内容而已:
- 01. 上游分析流程
- 02.课题多少个样品,测序数据量如何
- 03. 过滤不合格细胞和基因(数据质控很重要)
- 04. 过滤线粒体核糖体基因
- 05. 去除细胞效应和基因效应
- 06.单细胞转录组数据的降维聚类分群
- 07.单细胞转录组数据处理之细胞亚群注释
- 08.把拿到的亚群进行更细致的分群
- 09.单细胞转录组数据处理之细胞亚群比例比较
还有一些个性化汇总。文章的主线就是分群,然后继续分群。细胞数量也不多,大家的电脑基本上都可以hold住,第一次分群如下:
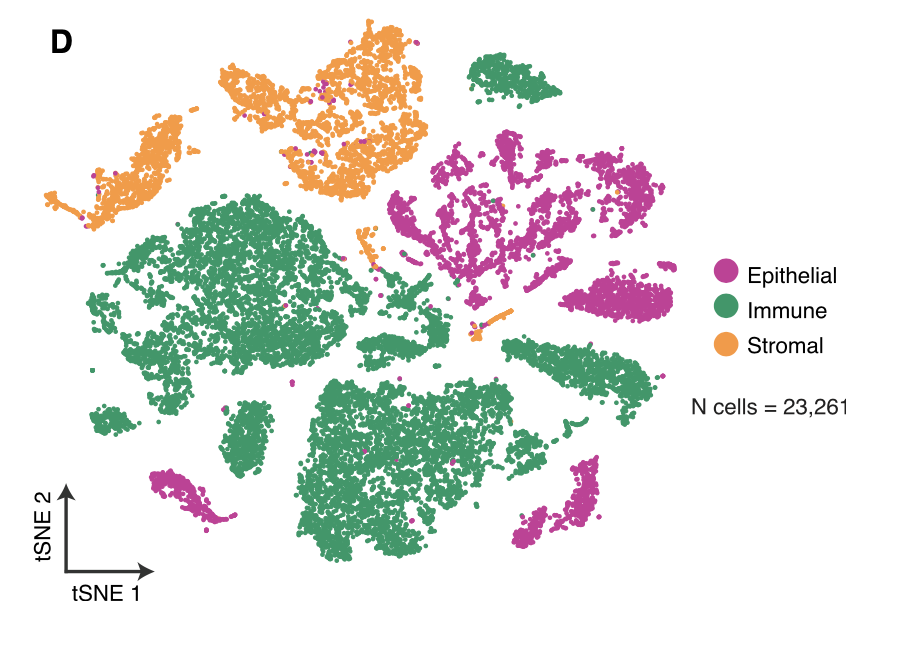
第二次分群,就是细化每一个亚群进行深入讨论,这就是这篇文章的主要图表啦,所以大家完全不用担心看不懂它。
如下你想看懂它们,毫无疑问,你的R语言需要过关。自己想办法把R的知识点路线图搞定,如下:
- 了解常量和变量概念
- 加减乘除等运算(计算器)
- 多种数据类型(数值,字符,逻辑,因子)
- 多种数据结构(向量,矩阵,数组,数据框,列表)
- 文件读取和写出
- 简单统计可视化
- 无限量函数学习
我们也可以解析每个代码
每个人写代码的习惯不一样,而且有更好的rmarkdown书写方式,大家都可以运行一遍作者提供的数据和代码,在他们的基础上面进行创作和发挥:
---
title: "关于批次效应矫正后出现负值"
author: "YuanSH"
date: "8/13/2020"
output:
html_document:
theme: cerulean
toc: true
# toc_depth: 2
toc_float:
true
---
<!-- <font color=#e8505b>**non-biological factors**</font> -->
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
加入我们 《单细胞cns文献图表复现》交流群!需要求助我们的拉群小助手啦,就需要缴纳18.8元的入群辛苦费!
文末友情推荐
要想真正入门生物信息学建议务必购买全套书籍,一点一滴攻克计算机基础知识,书单在:什么,生信入门全套书籍仅需160 。
如果大家没有时间自行慢慢摸索着学习,可以考虑我们生信技能树官方举办的学习班:
- 数据挖掘学习班第7期(线上直播3周,马拉松式陪伴,带你入门),原价4800的数据挖掘全套课程, 疫情期间半价即可抢购。
- 生信爆款入门-第9期(线上直播4周,马拉松式陪伴,带你入门),原价9600的生信入门全套课程,疫情期间3.3折即可抢购。
如果你课题涉及到转录组,欢迎添加一对一客服:详见:你还在花三五万做一个单细胞转录组吗?
号外:生信技能树知识整理实习生招募,长期招募,也可以简单参与软件测评笔记撰写,开启你的分享人生!另外,:绝大部分生信技能树粉丝都没有机会加我微信,已经多次满了5000好友,所以我开通了一个微信好友,前100名添加我,仅需150元即可,3折优惠期机会不容错过哈。我的微信小号二维码在:0元,10小时教学视频直播《跟着百度李彦宏学习肿瘤基因组测序数据分析》