本人做肺纤维化研究,近期在Science Advance 上连续发了两篇单细胞文章,所以计划根据单细胞天地胶质瘤的单细胞CNS复现系列推文,复现一下。
本文使用的是题目为Senescence of Alveolar Type 2 Cells Drives Progressive Pulmonary Fibrosis.发表在Am J Respir Crit Care Med (IF17.4)2020 Sep 29. PMID: 32991815的文章,对应的GEO数据GSE146981(17个对照和11个肺纤维化样本)
发现并不是常规的一个样本由barcode, genes ,matrix 三个文件构成的数据形式,因为通常读取10x数据需要三个文件:barcodes.tsv, genes.tsv, matrix.mtx,而这个文章的数据是一个样本被整合成了一个H5文件。如下所示:
GSM4411701_ca02_filtered_gene_bc_matrices_h5.h5 10.7 Mb
GSM4411702_ca07_filtered_gene_bc_matrices_h5.h5 5.6 Mb
GSM4411703_ca12nep_filtered_gene_bc_matrices_h5.h5 1.4 Mb
GSM4411704_ca16nep_filtered_gene_bc_matrices_h5.h5 11.3 Mb
GSM4411705_cc04dep17_filtered_gene_bc_matrices_h5.h5 8.9 Mb
GSM4411706_cc04pep17_filtered_gene_bc_matrices_h5.h5 8.8 Mb
GSM4411707_cc04tep17_filtered_gene_bc_matrices_h5.h5 6.9 Mb
GSM4411708_dd09dep18_filtered_gene_bc_matrices_h5.h5 5.5 Mb
GSM4411709_dd09pep18_filtered_gene_bc_matrices_h5.h5 6.5 Mb
GSM4411710_dd10dep18_filtered_gene_bc_matrices_h5.h5 11.3 Mb
起初看到一脸懵逼额,因为前面的例子:人人都能学会的单细胞聚类分群注释 读入的是csv文件,如果我文件都无法读入,后面的普通的质控降维聚类分群和细胞亚群的生物学注释这样的分析都无法完成。
只好求助jimmy老师了,在Jimmy的指导下,参阅了下面的教程完成了单个H5文件读入和转化为Seurat对象合并然后作图的方法:
确实很简单,我马上就可以开始做起来了。
先写一个脚本测试h5文件的读取
本来呢,我是一个个h5文件读取,代码发给jimmy老师检查被骂了一顿,重新写的。
rm(list=ls())
options(stringsAsFactors = F)
library(Seurat)
# H5文件读入和转化为Seurat对象
# https://nbisweden.github.io/workshop-scRNAseq/labs/compiled/seurat/seurat_01_qc.html
setwd('GSE146981_RAW/')
fs=list.files(pattern = '.h5')
fs
lapply(fs, function(x){
x=fs[1]
print(x)
a=Read10X_h5( x )
a[1:4,1:4]
library(stringr)
(p=str_split(x,'_',simplify = T)[,2])
sce <- CreateSeuratObject( a ,project = p )
sce
})
setwd('../')
然后走质控降维聚类分群和细胞亚群的生物学注释这样的标准流程
参考前面的例子:人人都能学会的单细胞聚类分群注释 ,我的代码如下:
rm(list=ls())
options(stringsAsFactors = F)
library(Seurat)
# H5文件读入和转化为Seurat对象
# https://nbisweden.github.io/workshop-scRNAseq/labs/compiled/seurat/seurat_01_qc.html
setwd('GSE146981_RAW/')
fs=list.files(pattern = '.h5')
fs
sceList = lapply(fs, function(x){
# x=fs[1]
print(x)
a=Read10X_h5( x )
a[1:4,1:4]
library(stringr)
(p=str_split(x,'_',simplify = T)[,2])
sce <- CreateSeuratObject( a ,project = p )
sce
})
setwd('../')
pro='integrated'
# 如果是 28个10X的单细胞转录组样品,走下面的流程会很勉强
for (i in 1:length(sceList)) {
sceList[[i]] <- NormalizeData(sceList[[i]], verbose = FALSE)
sceList[[i]] <- FindVariableFeatures(sceList[[i]], selection.method = "vst",
nfeatures = 2000, verbose = FALSE)
}
sceList
sce.anchors <- FindIntegrationAnchors(object.list = sceList, dims = 1:30)
sce.integrated <- IntegrateData(anchorset = sce.anchors, dims = 1:30)
library(ggplot2)
library(cowplot)
# switch to integrated assay. The variable features of this assay are automatically
# set during IntegrateData
DefaultAssay(sce.integrated) <- "integrated"
# Run the standard workflow for visualization and clustering
sce.integrated <- ScaleData(sce.integrated, verbose = FALSE)
sce.integrated <- RunPCA(sce.integrated, npcs = 30, verbose = FALSE)
sce.integrated <- RunUMAP(sce.integrated, reduction = "pca", dims = 1:30)
p1 <- DimPlot(sce.integrated, reduction = "umap", group.by = "orig.ident")
p2 <- DimPlot(sce.integrated, reduction = "umap", group.by = "orig.ident", label = TRUE,
repel = TRUE) + NoLegend()
plot_grid(p1, p2)
p2
ggsave(filename = paste0(pro,'_umap.pdf') )
sce=sce.integrated
DimHeatmap(sce, dims = 1:12, cells = 100, balanced = TRUE)
ElbowPlot(sce)
sce <- FindNeighbors(sce, dims = 1:15)
sce <- FindClusters(sce, resolution = 0.2)
table(sce@meta.data$integrated_snn_res.0.2)
sce <- FindClusters(sce, resolution = 0.8)
table(sce@meta.data$integrated_snn_res.0.8)
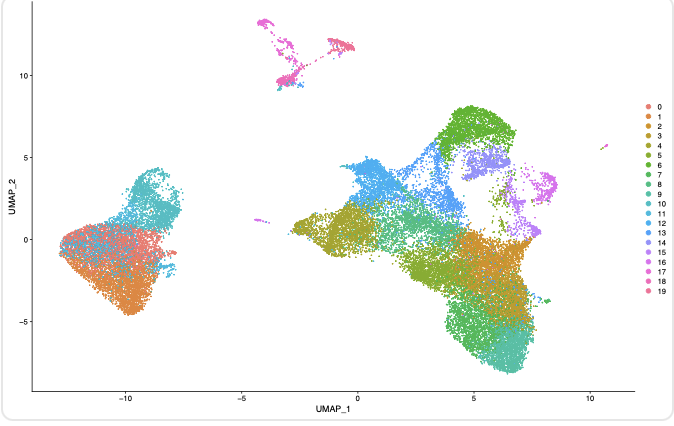
DimPlot(sce, reduction = "umap")
ggsave(filename = paste0(pro,'_umap_seurat_res.0.8.pdf') )
DimPlot(sce, reduction = "umap",split.by = 'orig.ident')
ggsave(filename = paste0(pro,'_umap_seurat_res.0.8_split.pdf') )
library(gplots)
tab.1=table(sce@meta.data$integrated_snn_res.0.8,sce@meta.data$integrated_snn_res.0.2)
tab.1
pdf(file = paste0(pro,'_different_resolution.pdf'))
balloonplot(tab.1, main ="different resolution(0.2 VS 0.8)", xlab ="", ylab="",
label = T, show.margins = F)
dev.off()
save(sce,file = 'integrated_after_seurat.Rdata')
初步得到了4张图
没有啥问题,继续加油吧,再次感谢jimmy老师的指导。