做单细胞数据分析,我们当然希望看到一个清晰的降维聚类分群结果,这样才方便做生物学亚群注释,比如前面的例子:[人人都能学会的单细胞聚类分群注释](https://mp.weixin.qq.com/s/1O1zuwLyM6_W0hZm5I26UA) ,第一次分群就非常漂亮!
但那个毕竟是理想情况下,实际上很多单细胞数据集分析到最后,分群其实很勉强,比如2019年11月发表的皮肤单细胞文章,标题是:《Transcriptome landscape of myeloid cells in human skin reveals diversity, rare populations and putative DC progenitors》,链接在:https://doi.org/10.1016/j.jdermsci.2019.11.012,研究者们对10个健康受试者的皮肤样品进行单细胞测序,然后鉴定了 myeloid cell populations.
我看到作者给出了一个重要的单细胞亚群图,如下所示:
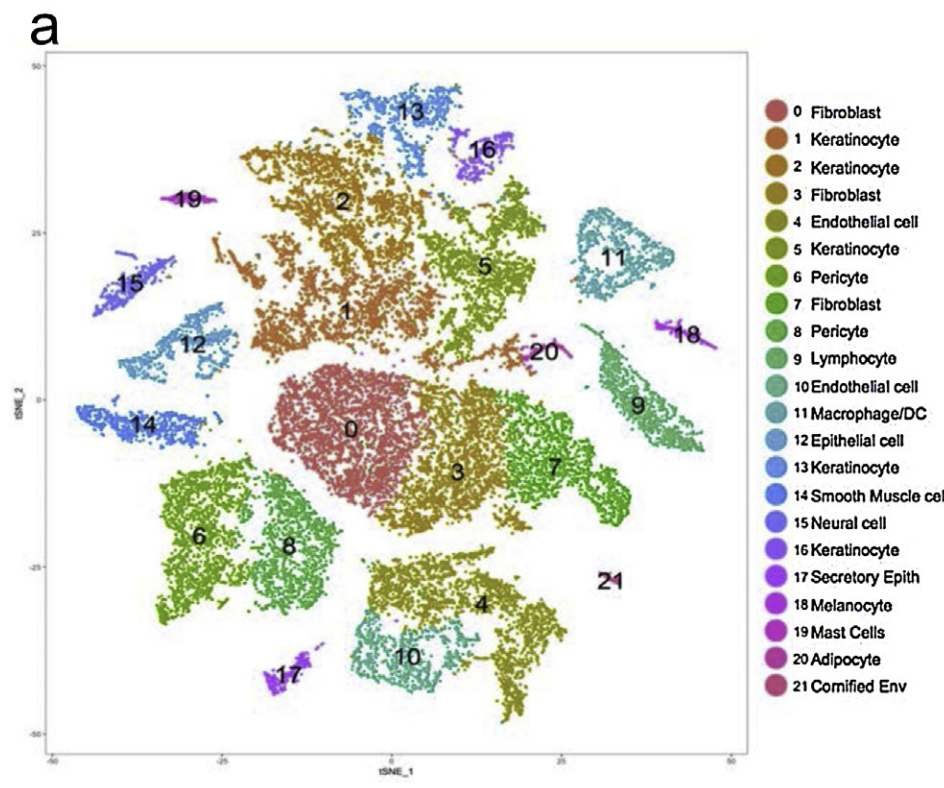
可以看到,这个就是普通的降维聚类分群,选取tSNE的坐标,最简单的seurat配色分群,就直接出图了。有很多可以改进的地方,比如umap的可视化这个时候理论上就会比原始的tSNE好很多。
但是这22个原始分群是如何被作者给出来生物学名字的,就很有意思了。如果是从标记基因角度,你很难看出来作者是如何对不同细胞亚群进行生物学注释的:
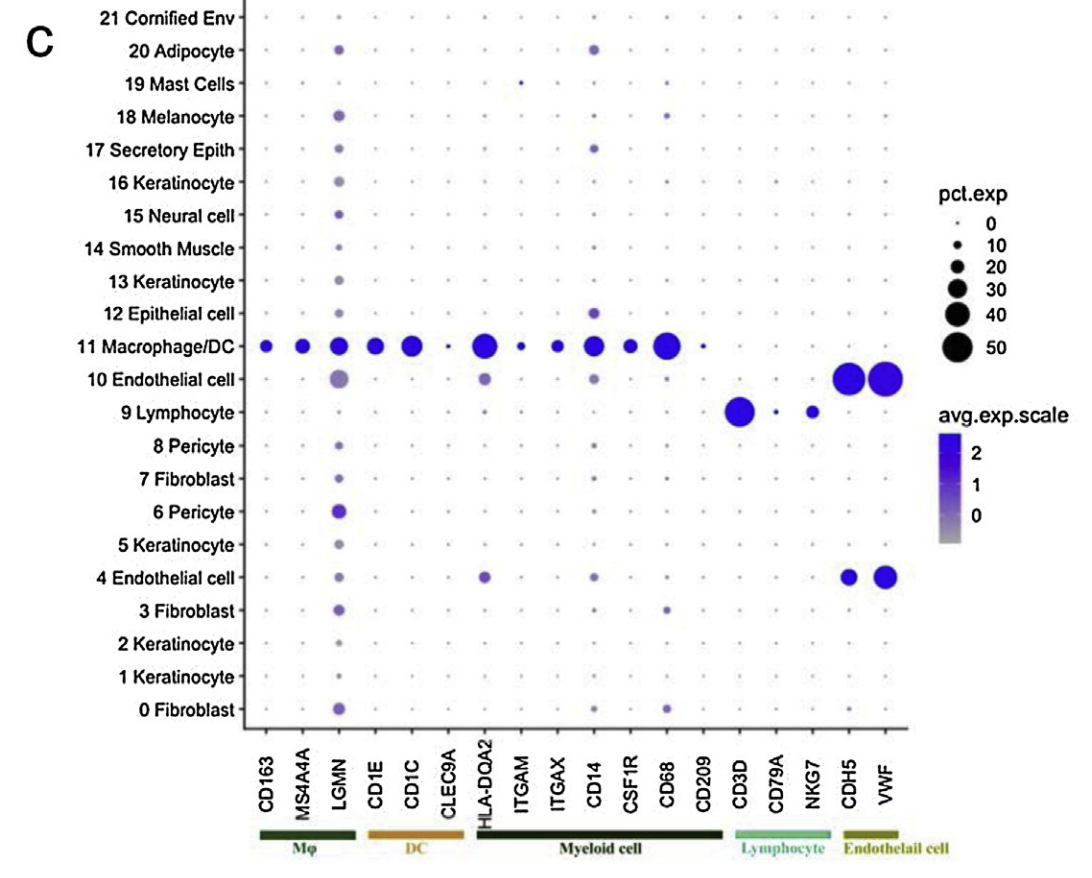
作者这里的细胞亚群及其大类的定义就很扯淡,内皮细胞可以和免疫细胞并列,其中免疫细胞可以细分为淋巴系和髓系,但是那个树突细胞和巨噬细胞理论上都是myeloid这样的髓系免疫细胞啊,而且这里面的成纤维细胞居然并不是一个大类别,而且也不显示它的通用标记基因。
细分亚群也是如此
上面我们提到了,树突细胞和巨噬细胞理论上都是myeloid这样的髓系免疫细胞,所以作者这里也把它们混起来进行细分亚群,如下所示:
Fig. 2. Re-clustering of macrophages and dendritic cells.
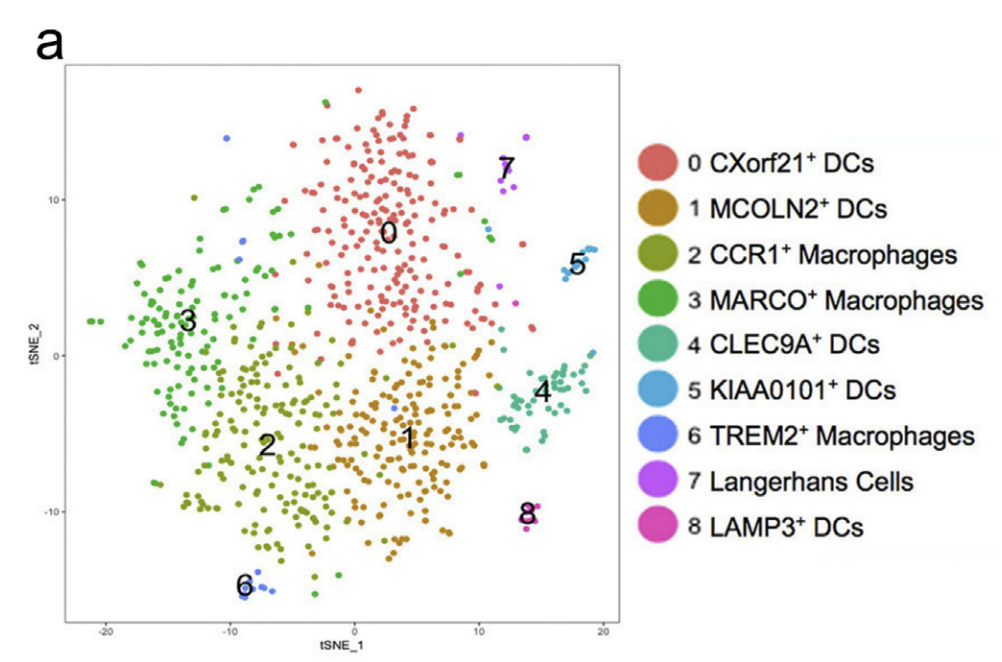
然后细分的亚群,命名呢,并不是生物学功能命名,而是以单个基因特异性进行命名。 但是后续标记基因气泡图又采取了另外的命名方式,如下所示:
- proliferating genes (sky blue bar),
- dendritic cell markers (dark blue bar),
- macrophage markers (black bar),
- cDC2 markers (orange bar),
- cDC1 markers (cyan bar),
- Mw/DC subcluster #0 markers (red bar)
- Mw/DC subcluster #1 markers (brown bar).
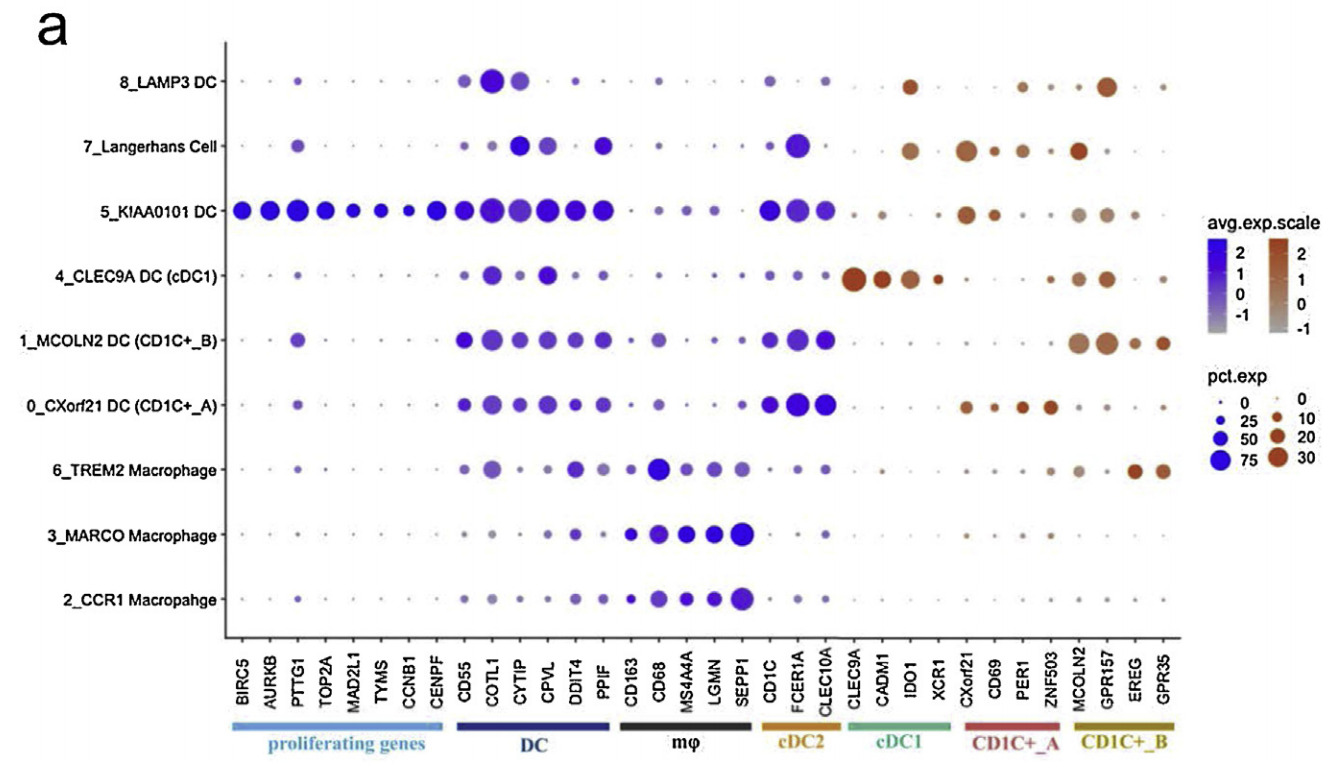
Mw/DC subcluster #5 is a cluster of proliferating DCs and appearing to represent cDC2 progenitors.
而且居然还可以进行差异分析: - fcDC2 marker gene set (comprising CD1C, CD1E, CD1A, CD11b, CD11c, FCER1A, SIRPA and CLEC10A)
- cDC1 marker gene set (comprising CLEC9A, CADM1, IDO1 and XCR1).
也是非常的勉强:
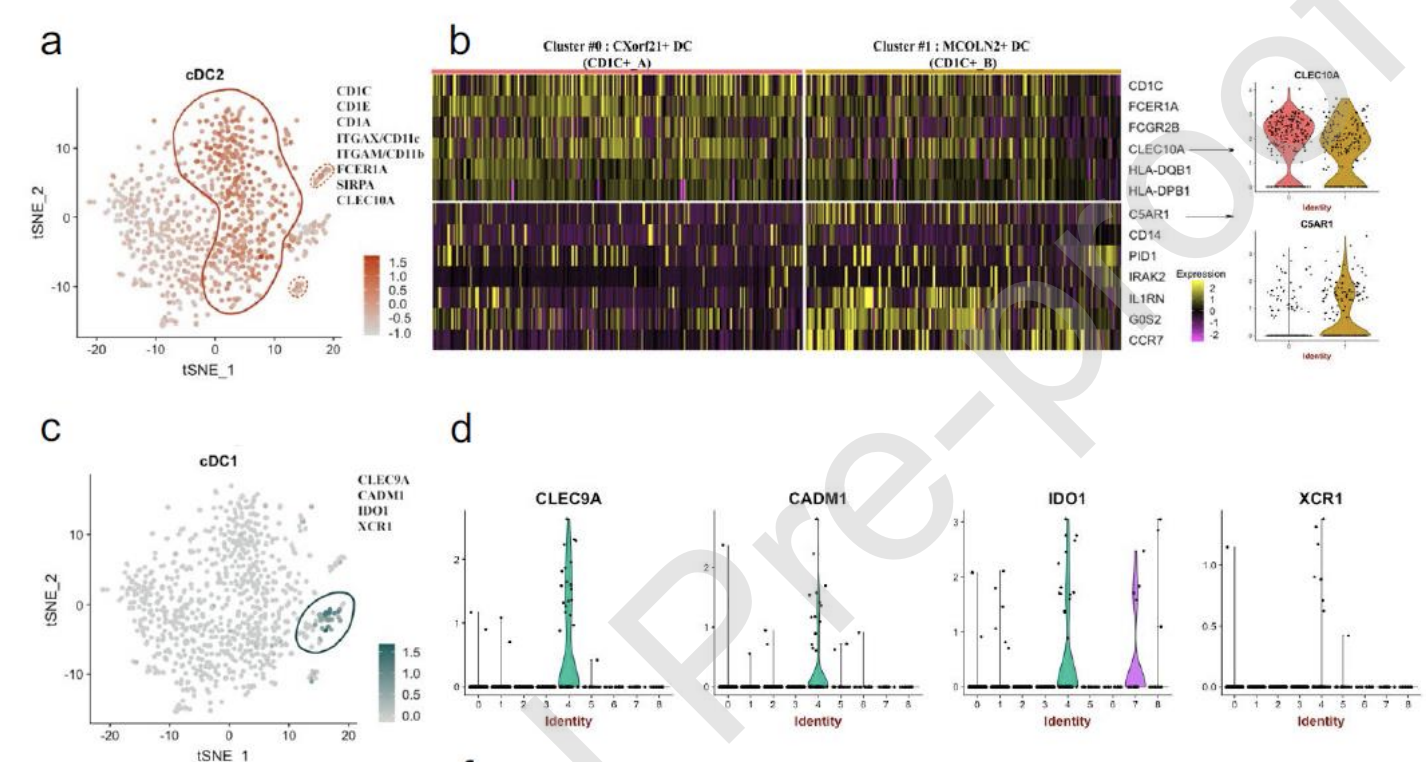
这个时候我就非常佩服作者讲故事的能力了,无论多么差的数据分析结果,只有能给一个合理的生物学解释,就足以发表了。灵活拷问
如果是你的数据遇到了如此尴尬的分群,你会怎么办?
另外,作为一个学徒作业吧,想办法拿到这个文章的单细胞转录组数据,走一下我们一直讲解的单细胞转录组数据处理流程,看看能不能拿到比作者漂亮的结果哈!