在单细胞交流群看到有小伙伴分享了文献:《Caloric Restriction Reprograms the Single-Cell Transcriptional Landscape of Rattus Norvegicus Aging》这个里面的单细胞研究整理了常见的大鼠这个物种的单细胞亚群的标记基因,列表如下:
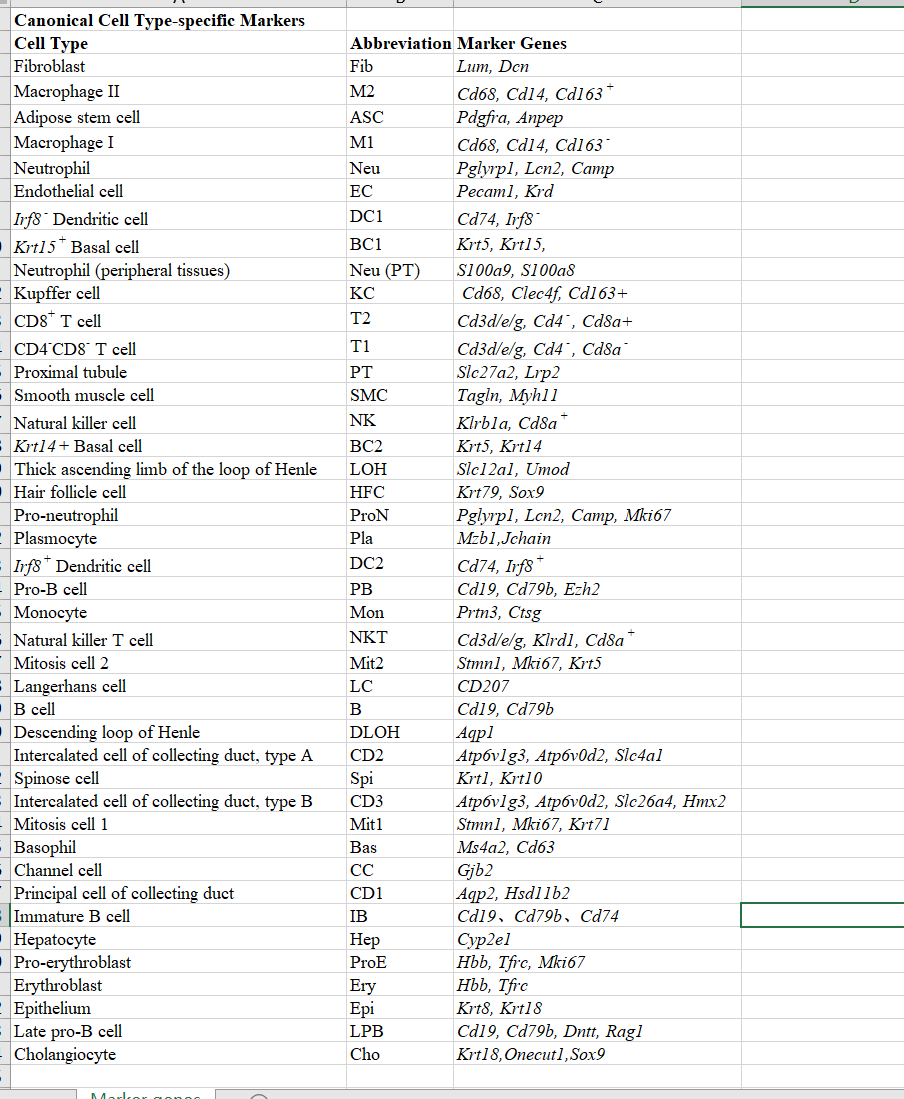
可以看到,绝大部分都是人类单细胞亚群标记基因的基因名字的小写形式而已。
给大家一个学徒作业,在pbmc3k的单细胞数据集里面,降维聚类分群后,对上面的基因进行可视化!
首先对官方 pbmc3k 例子,跑标准代码:
library(Seurat)
# https://cf.10xgenomics.com/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz
## Load the PBMC dataset
pbmc.data <- Read10X(data.dir = "filtered_gene_bc_matrices/hg19/")
## Initialize the Seurat object with the raw (non-normalized data).
pbmc <- CreateSeuratObject(counts = pbmc.data, project = "pbmc3k",
min.cells = 3, min.features = 200)
## Identification of mithocondrial genes
pbmc[["percent.mt"]] <- PercentageFeatureSet(pbmc, pattern = "^MT-")
## Filtering cells following standard QC criteria.
pbmc <- subset(pbmc, subset = nFeature_RNA > 200 & nFeature_RNA < 2500 &
percent.mt < 5)
## Normalizing the data
pbmc <- NormalizeData(pbmc, normalization.method = "LogNormalize",
scale.factor = 10000)
pbmc <- NormalizeData(pbmc)
## Identify the 2000 most highly variable genes
pbmc <- FindVariableFeatures(pbmc, selection.method = "vst", nfeatures = 2000)
## In addition we scale the data
all.genes <- rownames(pbmc)
pbmc <- ScaleData(pbmc, features = all.genes)
pbmc <- RunPCA(pbmc, features = VariableFeatures(object = pbmc),
verbose = FALSE)
pbmc <- FindNeighbors(pbmc, dims = 1:10, verbose = FALSE)
pbmc <- FindClusters(pbmc, resolution = 0.5, verbose = FALSE)
pbmc <- RunUMAP(pbmc, dims = 1:10, umap.method = "uwot", metric = "cosine")
table(pbmc$seurat_clusters)
# pbmc.markers <- FindAllMarkers(pbmc, only.pos = TRUE, min.pct = 0.25, logfc.threshold = 0.25, verbose = FALSE)
DimPlot(pbmc, reduction = "umap", group.by = 'seurat_clusters',
label = TRUE, pt.size = 0.5)
DotPlot(pbmc, features = c("MS4A1", "GNLY", "CD3E",
"CD14", "FCER1A", "FCGR3A",
"LYZ", "PPBP", "CD8A"),
group.by = 'seurat_clusters')
## Assigning cell type identity to clusters
new.cluster.ids <- c("Naive CD4 T", "CD14+ Mono", "Memory CD4 T", "B", "CD8 T",
"FCGR3A+ Mono", "NK", "DC", "Platelet")
names(new.cluster.ids) <- levels(pbmc)
pbmc <- RenameIdents(pbmc, new.cluster.ids)
DimPlot(pbmc, reduction = "umap", label = TRUE, pt.size = 0.5) + NoLegend()
pbmc$cluster_by_counts=Idents(pbmc)
table(pbmc$cluster_by_counts)
然后自己去对文献:《Caloric Restriction Reprograms the Single-Cell Transcriptional Landscape of Rattus Norvegicus Aging》附件里面的基因复制粘贴处理成为人类基因,然后可视化(dotplot方法)。
同时,也可视化人类的部分单细胞亚群标记基因,对比展示:
# T Cells (CD3D, CD3E, CD8A),
# B cells (CD19, CD79A, MS4A1 [CD20]),
# Plasma cells (IGHG1, MZB1, SDC1, CD79A),
# Monocytes and macrophages (CD68, CD163, CD14),
# NK Cells (FGFBP2, FCG3RA, CX3CR1),
# Photoreceptor cells (RCVRN),
# Fibroblasts (FGF7, MME),
# Endothelial cells (PECAM1, VWF).
# epi or tumor (EPCAM, KRT19, PROM1, ALDH1A1, CD24).
# immune (CD45+,PTPRC), epithelial/cancer (EpCAM+,EPCAM),
# stromal (CD10+,MME,fibo or CD31+,PECAM1,endo)
library(ggplot2)
genes_to_check = c('PTPRC', 'CD3D', 'CD3E', 'CD4','CD8A',
'CD19', 'CD79A', 'MS4A1' ,
'IGHG1', 'MZB1', 'SDC1',
'CD68', 'CD163', 'CD14',
'TPSAB1' , 'TPSB2', # mast cells,
'RCVRN','FPR1' , 'ITGAM' ,
'C1QA', 'C1QB', # mac
'S100A9', 'S100A8', 'MMP19',# monocyte
'LAMP3', 'IDO1','IDO2',## DC3
'CD1E','CD1C', # DC2
'KLRB1','NCR1', # NK
'FGF7','MME', 'ACTA2', ## fibo
'DCN', 'LUM', 'GSN' , ## mouse PDAC fibo
'Amy1' , 'Amy2a2', # Acinar_cells
'PECAM1', 'VWF', ## endo
'EPCAM' , 'KRT19', 'PROM1', 'ALDH1A1' )
th=theme(axis.text.x = element_text(angle = 45,
vjust = 0.5, hjust=0.5))
p_all_markers=DotPlot(sce.all, features = genes_to_check,
assay='RNA' ,group.by = 'celltype' ) + coord_flip() +th