以前在《生信技能树》(才发现居然已经是 2019-08-22的事情了)我们介绍过中科院北京基因组研究所生命与健康大数据中心开发的原始组学数据归档库GSA (Genome Sequence Archive):[不止是NCBI的SRA可以下载测序数据](https://mp.weixin.qq.com/s/DqgQlBaSGt73e4SeEeTJoQ),但是最近我看文献,发现超级多单细胞研究的数据,都是上传到了华大的类似的中心(原始组学数据归档库),如下:
Single-Cell Atlas of Immune Cells in TNBC Reveals a TCR+ Macrophage Subset 来源标识: CNGB Project ( ID CNP0000286 )
数据类型: Transcriptome or Gene expression
相关领域: Medical
项目编号: CNP0000286
当然了,这个研究其实是因为本来就是华大牵头,所以存储在他们自己的数据库中心很容易理解。
尤其是最近在朋友圈刷到了发表在《Science Bulletin》,并作为封面文章的《Single-cell atlas of domestic pig cerebral cortex and hypothalamus》,其文章链接:Single-cell atlas of domestic pig cerebral cortex and hypothalamus - ScienceDirect , 数据链接: https://db.cngb.org/search/project/CNP0000686/
本来以为不是在NCBI的SRA数据库里面,下载会很麻烦。进入数据库简单看了看:
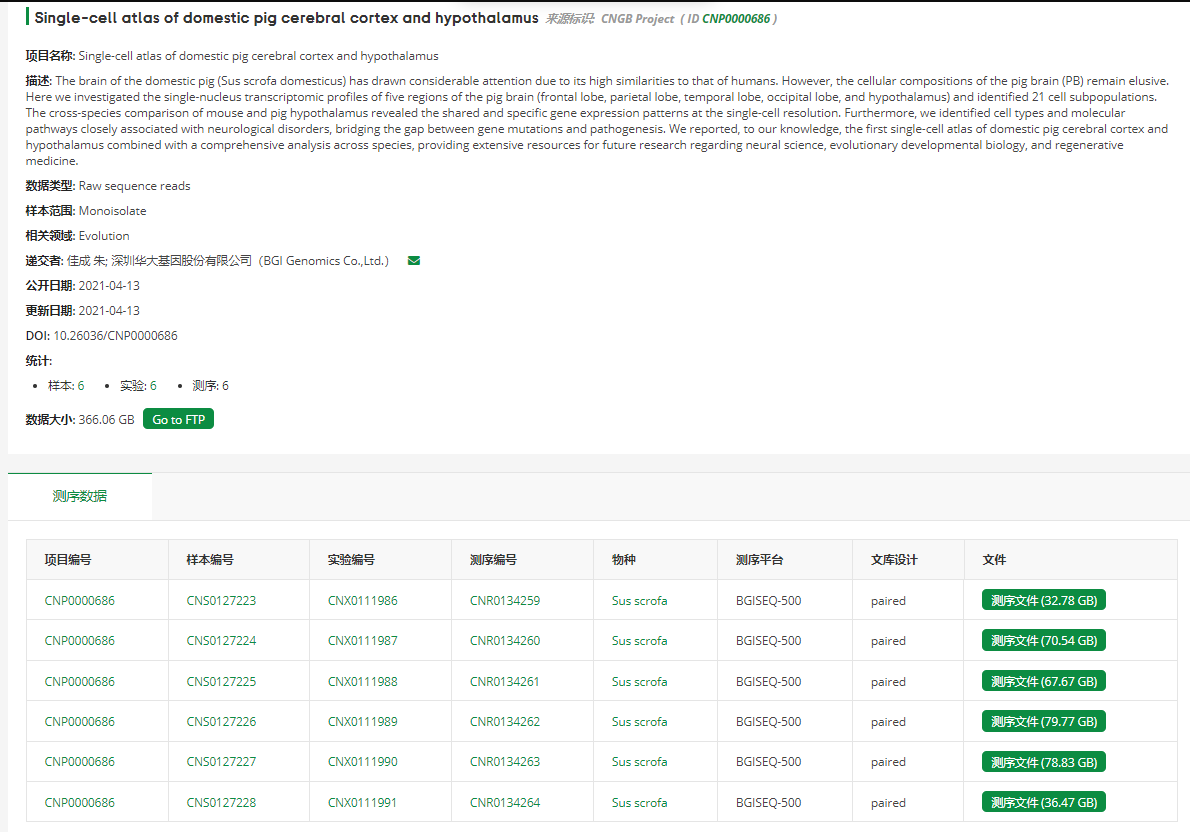
可以看到是6个样品,几百个G的数据量而已,数据库官网写了可以Aspera 高速下载, 就方便很多。
首先从数据页面复制这些链接
6个样品,是12个链接,居然得手动一个个复制粘贴,不知道有没有高级操作,有经验的小伙伴可以留言分享一下。
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127223/CNX0111986/CNR0134259/V300015611B_L02_read_1.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127223/CNX0111986/CNR0134259/V300015611B_L02_read_2.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127224/CNX0111987/CNR0134260/CL100128991_L01_read_1.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127224/CNX0111987/CNR0134260/CL100128991_L01_read_2.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127225/CNX0111988/CNR0134261/CL100128991_L02_read_1.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127225/CNX0111988/CNR0134261/CL100128991_L02_read_2.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127226/CNX0111989/CNR0134262/CL100132063_L02_read_1.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127226/CNX0111989/CNR0134262/CL100132063_L02_read_2.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127227/CNX0111990/CNR0134263/CL100132063_L01_read_1.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127227/CNX0111990/CNR0134263/CL100132063_L01_read_2.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127228/CNX0111991/CNR0134264/V300015611B_L01_read_1.fq.gz
https://ftp.cngb.org/pub/CNSA/data3/CNP0000686/CNS0127228/CNX0111991/CNR0134264/V300015611B_L01_read_2.fq.gz
根据官方的提示进行截取:
[path/to/files to download] is the path of the file to be downloaded. Please enter CNSA FTP, copy the data address on the browser you want to download, and delete "https://ftp.cngb.org". The rest of the path is the file path to be downloaded that needs to be filled in the command line. For example: if you want to download the files under this directory (https://ftp.cngb.org/pub/CNSA/data1/CNP0000007/CNS0000004/CNX0000010/CNR0048164/) on FTP, delete "https://ftp.cngb.org/" in the directory, the rest of the path is: /pub/CNSA/data1/CNP0000007/CNS0000004/CNX0000010/CNR0048164/, which is the [path/to/files to download] that you need to fill in the command line.
[path/to/store/downloaded files] is the path where the downloaded files are stored. For example: /home/[user]/download/
其实就是删除网页链接的开头部分:
cat fq.txt |cut -d'/' -f4- >new_fq.txt
pub/CNSA/data3/CNP0000686/CNS0127223/CNX0111986/CNR0134259/V300015611B_L02_read_1.fq.gz
pub/CN
这个 new_fq.txt 文件非常重要,后续批量下载就靠它了哦!
有了样品的下载链接,然后自己使用conda安装aspera,参考 :使用ebi数据库直接下载fastq测序数据 , 这个教程来直接下载fastq文件啦。首先使用conda安装aspera,命令如下所示:
conda create -n download
conda activate download
conda install -y -c hcc aspera-cli
which ascp
## 一定要搞清楚你的软件被conda安装在哪
ls -lh ~/miniconda3/etc/asperaweb_id_dsa.openssh
我们已经多次介绍过conda细节了,这里就不再赘述。
- conda管理生信软件一文就够
- 生信技能树B站软件安装视频 https://www.bilibili.com/video/av28836717
因为是下载华大的数据,所以需要一个配套的秘钥:https://db.cngb.org/dc_assets/build/dc_cnsa/handbook/aspera_download.key
接下来写一个简单的循环即可:
wget https://db.cngb.org/dc_assets/build/dc_cnsa/handbook/aspera_download.key
cat new_fq.txt |while read id;do(echo ascp -i aspera_download.key -P33001 -T -k1 -l100m aspera_download@183.239.175.39:$id ./);done > download_CNGBdb.sh
前提是你的 ascp 软件安装成功哦,然后就可以拿到如下所示的下载成功的fq文件啦:
$ ls -lh *fq.gz |cut -d" " -f 5-
16G 8月 20 20:57 CL100128991_L01_read_1.fq.gz
55G 8月 20 22:21 CL100128991_L01_read_2.fq.gz
16G 8月 20 22:44 CL100128991_L02_read_1.fq.gz
53G 8月 21 00:02 CL100128991_L02_read_2.fq.gz
17G 8月 21 00:58 CL100132063_L01_read_1.fq.gz
62G 8月 21 02:30 CL100132063_L01_read_2.fq.gz
17G 8月 21 00:27 CL100132063_L02_read_1.fq.gz
1.4G 8月 21 00:29 CL100132063_L02_read_2.fq.gz # 这个下载失败了
9.3G 8月 21 02:43 V300015611B_L01_read_1.fq.gz
28G 8月 21 03:24 V300015611B_L01_read_2.fq.gz
假如需要跑ellranger count,得先修改fq文件名
mv V300015611B_L02_read_1.fq.gz V300015611B_S1_L001_R1_001.fastq.gz
mv V300015611B_L02_read_2.fq.gz V300015611B_S1_L001_R2_001.fastq.gz
文件如下所示:
8.4G 2月 12 2020 V300015611B_S1_L001_R1_001.fastq.gz
25G 8月 20 19:47 V300015611B_S1_L001_R2_001.fastq.gz
下载到单细胞测序原始fq数据仅仅是开始
后续分析更精彩,主要是需要跑我们以前在单细胞天地分享过的上游流程, 如下:
- 单细胞实战(一)数据下载
- 单细胞实战(二) cell ranger使用前注意事项
- 单细胞实战(三) Cell Ranger使用初探
- 单细胞实战(四) Cell Ranger流程概览
- 单细胞实战(五) 理解cellranger count的结果
- 更新版本见:cellranger更新到4啦(全新使用教程)
以及拿到表达量后的降维聚类分群和各种各样的高级分析: