这两个月单细胞市场上最劲爆的消息应该就是我们《生信技能树》和《单细胞天地》等公众号都推出来的 10X单细胞转录组钜惠套餐,详见:2个分组的单细胞项目标准分析,原价15~20万的6个10x单细胞转录组套餐,现价10万。添加微信咨询的人太多了,三个团队连轴转都还没有处理完毕,主要是每个前来咨询的小伙伴我们都会提供个性化点评,避免大家花10万块钱的冤枉钱,做了测序却不知道如何分析如何写作。
做了活动才知道,原来大家的科研思维都好原始,研究肿瘤的无非就是转移与否,耐药与否,复发等等,基本上常见的几十种癌症其实早就有文章发表了。更别提最简单的图谱研究了。基本上每个癌症都有一个大于20人的队列,并且是公开表达量矩阵的,比如《Dissecting esophageal squamous-cell carcinoma ecosystem by single-cell transcriptomic analysis》这个前不久刚刚发布的食管癌单细胞队列,每个病人的临床特性清清楚楚 :
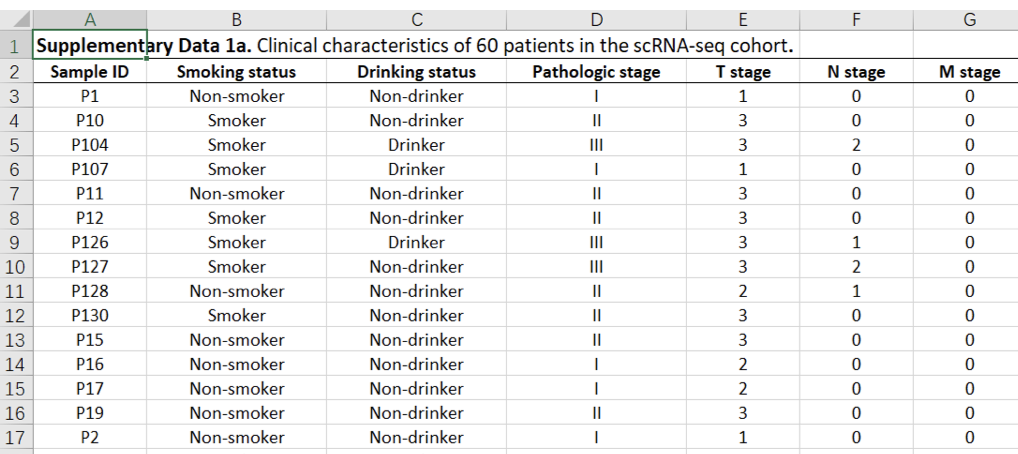
你下载了表达量矩阵,就可以自己去设计课题啦,比如抽烟与否的食管癌病人的单细胞水平差异,不同病理分级分期病人(比如早期和晚期)食管癌患者单细胞水平差异等等!
头颈癌,结直肠癌,胃癌,乳腺癌也是如此!肺癌就更多了,非小细胞肺癌里面的肺鳞癌和肺腺癌,以及小细胞肺癌。
通通没有毕业自己测序了!
而且不仅仅是纯粹的数据挖掘文章在开始复用已经发表了的单细胞,哪怕是CNS及其子刊也开始使用公共单细胞数据集啦。比如,结直肠癌的单细胞队列,于Nat Genet . 2020 Jun;发表的文章:《Lineage-dependent gene expression programs influence the immune landscape of colorectal cancer》,就有 91,103 unsorted single cells from 23 Korean and 6 Belgian patients. 而且是公开可以下载的。
就有一个 2021年4月发表在NC的文章:《Epigenomic landscape of human colorectal cancer unveils an aberrant core of pan-cancer enhancers orchestrated by YAP/TAZ》的figure6就是利用了这个单细胞数据去验证他们发现的 cancer regulatory blueprint (CRB score) ,这个打分很明显在恶性的肿瘤细胞里面远高于正常水平细胞。
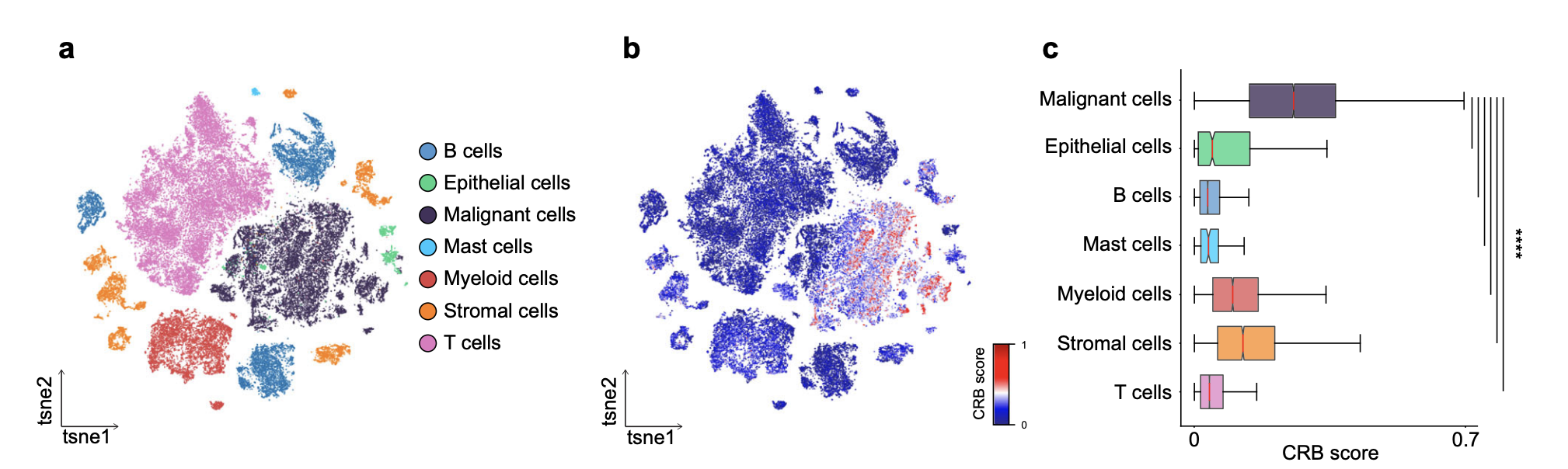
很简单的分析,作者首先对全部的单细胞数据进行降维聚类分群,得到:
- (B cells n = 9146;
- Mast cells n = 187;
- Myeloid cells n = 6769;
- Stromal cells n = 5933;
- T cells n = 23,115).
以及上皮细胞,但是上皮细胞区分了恶性上皮和正常水平细胞:
- malignant (gray; n = 17,469)
- non-malignant epithelial clusters (green; n = 1070),
作者定义的正常水平细胞数量有点少啊,
然后作者把 全部的上皮细胞(18,539 epithelial cells)进行重新降维聚类分群,再去映射他们自己的cancer regulatory blueprint (CRB score) ,以及目前比较流行的stemness,发现并不是一回事。
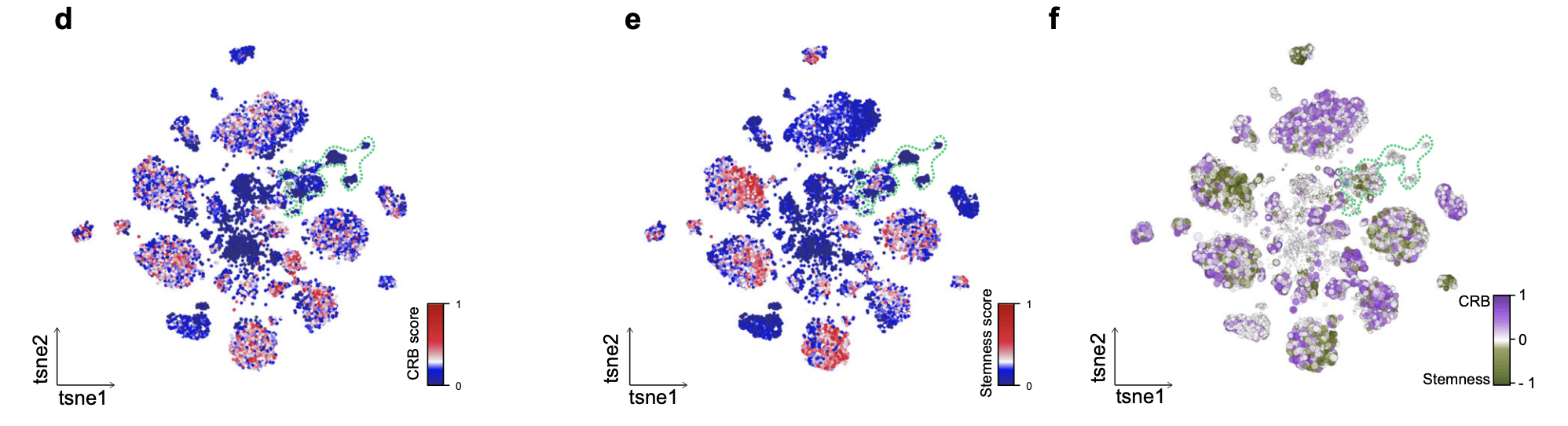
发现 malignant cells with an active CRB do not necessarily display stem-like properties
单细胞数据复用时代来袭,你准备好了吗?
简单的复用,就是前面演示的降维聚类分群啦,小伙伴们跟着我们的单细胞数据分析流程,基本上都掌握了: 单细胞聚类分群注释 ,尤其是我们重点演示了的第一层次的分群。b站免费视频课程 地址:https://www.bilibili.com/video/BV19Q4y1R7cu
如果你对单细胞数据分析还没有基础认知,可以看基础10讲:
- 01. 上游分析流程
- 02.课题多少个样品,测序数据量如何
- 03. 过滤不合格细胞和基因(数据质控很重要)
- 04. 过滤线粒体核糖体基因
- 05. 去除细胞效应和基因效应
- 06.单细胞转录组数据的降维聚类分群
- 07.单细胞转录组数据处理之细胞亚群注释
- 08.把拿到的亚群进行更细致的分群
- 09.单细胞转录组数据处理之细胞亚群比例比较
高级的复用,就需要自己熟练的掌握算机基础知识 ,我把它粗略的分成基于R语言的统计可视化,以及基于Linux的NGS数据处理:
把R的知识点路线图搞定,如下:
- 了解常量和变量概念
- 加减乘除等运算(计算器)
- 多种数据类型(数值,字符,逻辑,因子)
- 多种数据结构(向量,矩阵,数组,数据框,列表)
- 文件读取和写出
- 简单统计可视化
- 无限量函数学习
Linux的6个阶段也跨越过去 ,一般来说,每个阶段都需要至少一天以上的学习:
- 第1阶段:把linux系统玩得跟Windows或者MacOS那样的桌面操作系统一样顺畅,主要目的就是去可视化,熟悉黑白命令行界面,可以仅仅以键盘交互模式完成常规文件夹及文件管理工作。
- 第2阶段:做到文本文件的表格化处理,类似于以键盘交互模式完成Excel表格的排序、计数、筛选、去冗余、查找、切割、替换、合并、补齐,熟练掌握awk、sed、grep这文本处理的三驾马车。
- 第3阶段:元字符,通配符及shell中的各种扩展,从此linux操作不再神秘!
- 第4阶段:高级目录管理:软硬链接,绝对路径和相对路径,环境变量。
- 第5阶段:任务提交及批处理,脚本编写解放你的双手。
- 第6阶段:软件安装及conda管理,让linux系统实用性放飞自我。
有了这样的基础,才有可能去摸索转录因子分析和细胞通讯等高级分析了,主要是对这些分析基本上都是在Linux服务器上面完成,而且计算机资源消耗会比较大,我也多次分享过细节教程: