有学员提问, 为什么他看到了一个基因,如下所示,居然有两个id,看起来就非常的诡异,让他百思不得其解。
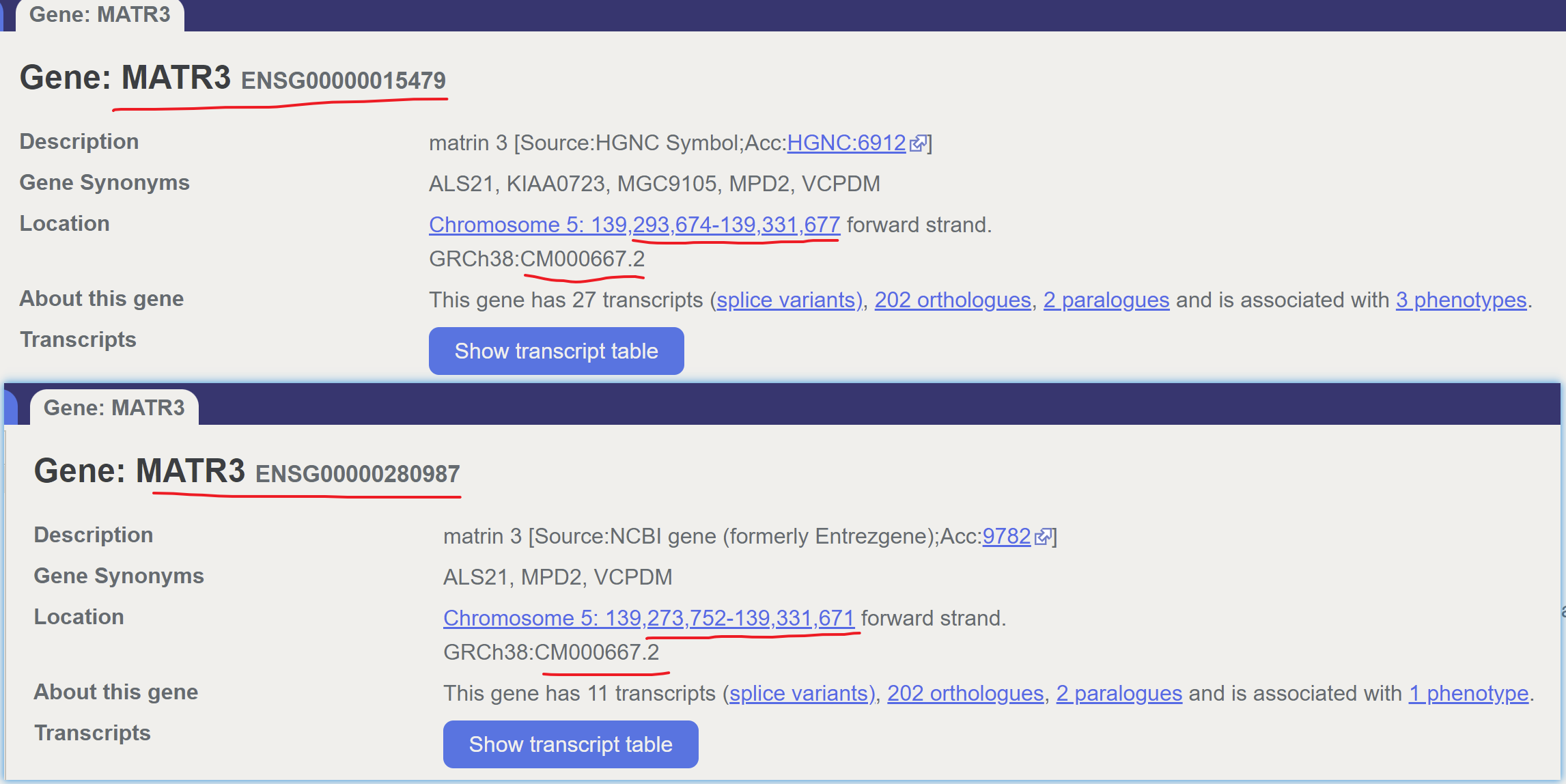
其实这个基因首先是有一个基因名字,是 MATR3 ,是人类基因命名委员会给出来的。如果你不了解人类基因命名委员会(HUGO Gene Nomenclature Committee),可以看我六年前的博客介绍:http://www.bio-info-trainee.com/653.html
它这样的名字 https://www.genecards.org/cgi-bin/carddisp.pl?gene=MATR3 对应多个ensembl数据库的基因id很正常,因为它本来就研究并不多,出现数据库的冲突是在所难免的,毕竟不同数据库要同步5万多个基因啊!
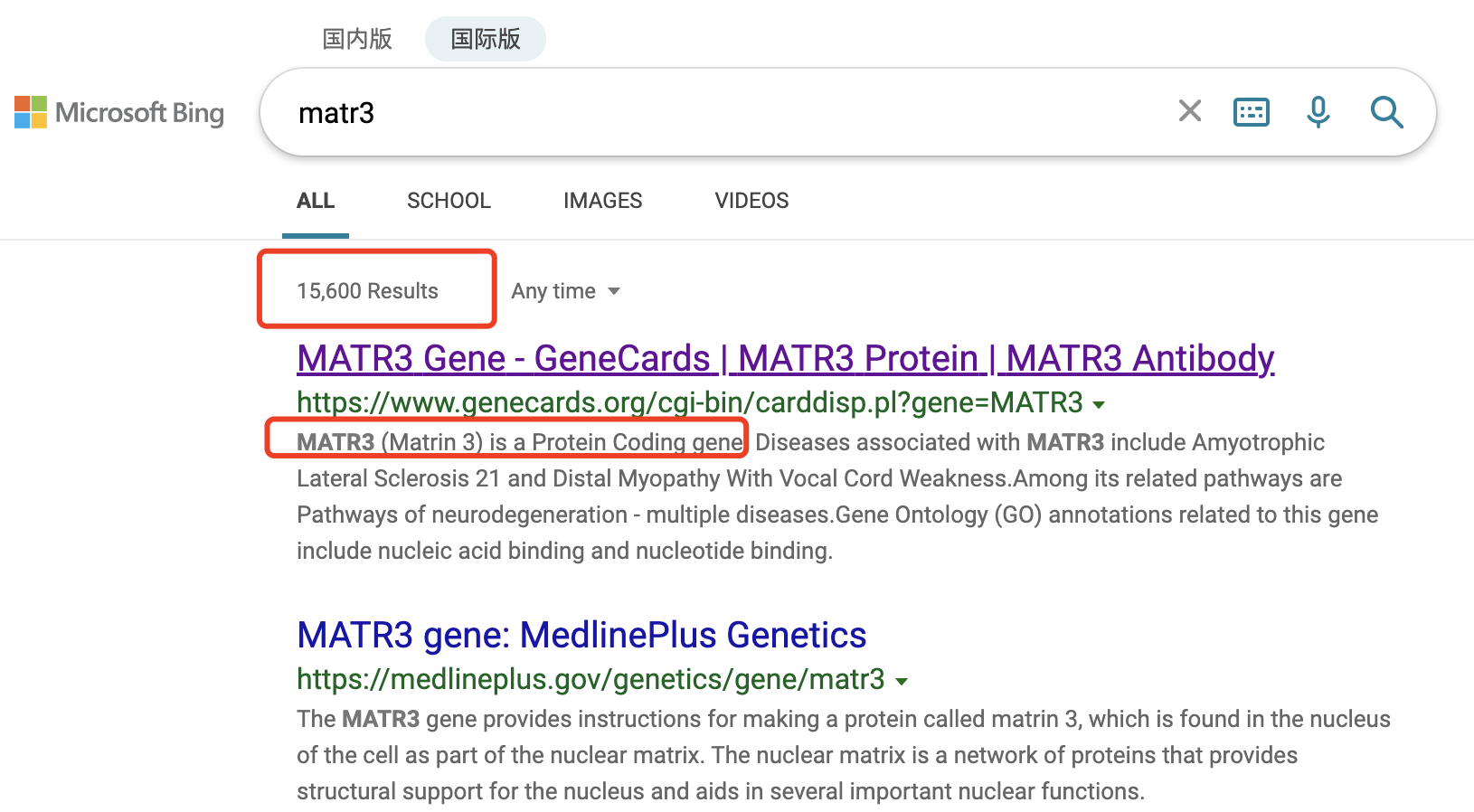
如果去搜索它,你会发现 一个基因,搜索结果就这么一点, 简直是丢脸!
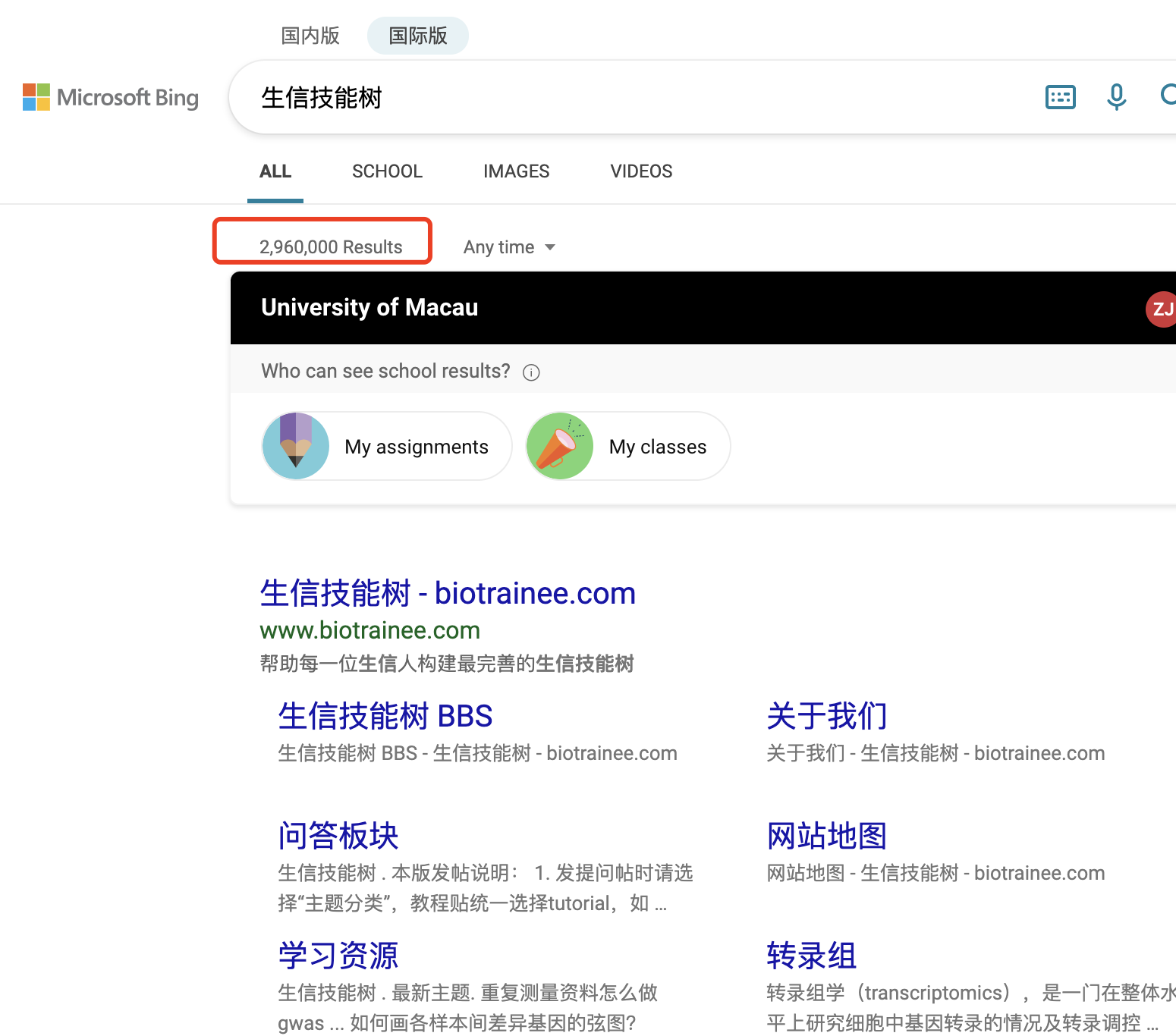
作为对比,你可以搜索咱们生信技能树看看:
假如你的表达量矩阵就是ensembl数据库的id格式,然后需要转为基因的名字,这个时候两个id都转为了同样的名字,后续处理就很尴尬。
其实这个时候你可以随意选择,比如这个基因你可以直接删除,或者两个id随意选择一个,或者选择表达量最高的那个id。
下面给出了一个示范代码:
#将ENSEMBL ID转换为SYMBOL,这里用了org.Mm.eg.db包中的ID数据和clusterProfiler包中的bitr函数
library(clusterProfiler)
library(org.Mm.eg.db)
ids=bitr(rl$V1,'ENSEMBL','SYMBOL',org.Mm.eg.db)
ids=ids[!duplicated(ids$SYMBOL),] # 我这里直接粗暴的删除出现重复的id
head(ids)
pos=match(ids$ENSEMBL,rl$V1)#match函数获取括号中左边的在右边的中的位置信息
ct <- mtx[pos,]
rownames(ct) <- ids$SYMBOL
ct[1:4,1:4]
colnames(ct)=cl$V1
假如你原来的表达量矩阵是6万个ensembl的id组成的,经过了上面的代码的转换,变成了2万个基因的矩阵。
这个时候你不要害怕,是正常的!人类就只有2万个蛋白编码基因矩阵, 4万个id缺失了就缺失了,这就是人生。如果你问我为什么,我得给你开课,讲解背景知识至少十天半个月!