早期的单细胞转录组课题只需要做到图谱解释程度即可,就是第一层次降维聚类分群后不停地细分亚群。甚至不需要有精细的课题设计,反正拿到了单细胞转录组表达量矩阵就可以跑代码,无所谓样品是否有分组。
后期单细胞领域卷起来了,纯粹的图谱肯定是没有新意啦,或者说海量的公共的单细胞转录组数据已经可以无限制任何人免费获取,这样的话大家要想分析出不一样的地方,就需要想办法给没有课题设计的项目找到分组信息!
比如之前是可能是多个同类型癌症病人的单细胞,但是癌症病人是有分子分型或者临床分期或者病理区分的,或者有预后信息,抽烟喝酒与否的生活习惯差异,就有了后续分析的可能性。如果完全都没有,其实还可以通过数据本身的特征给它分组,比如单细胞水平的肿瘤异质性就是其中一个很好的点。
胃癌
文章:《Single-cell profiling reveals tumour cell heterogeneity accompanying a pre-malignant and immunosuppressive microenvironment in gastric adenocarcinoma. Clin Transl Med. 2023 Dec》
如下所示:
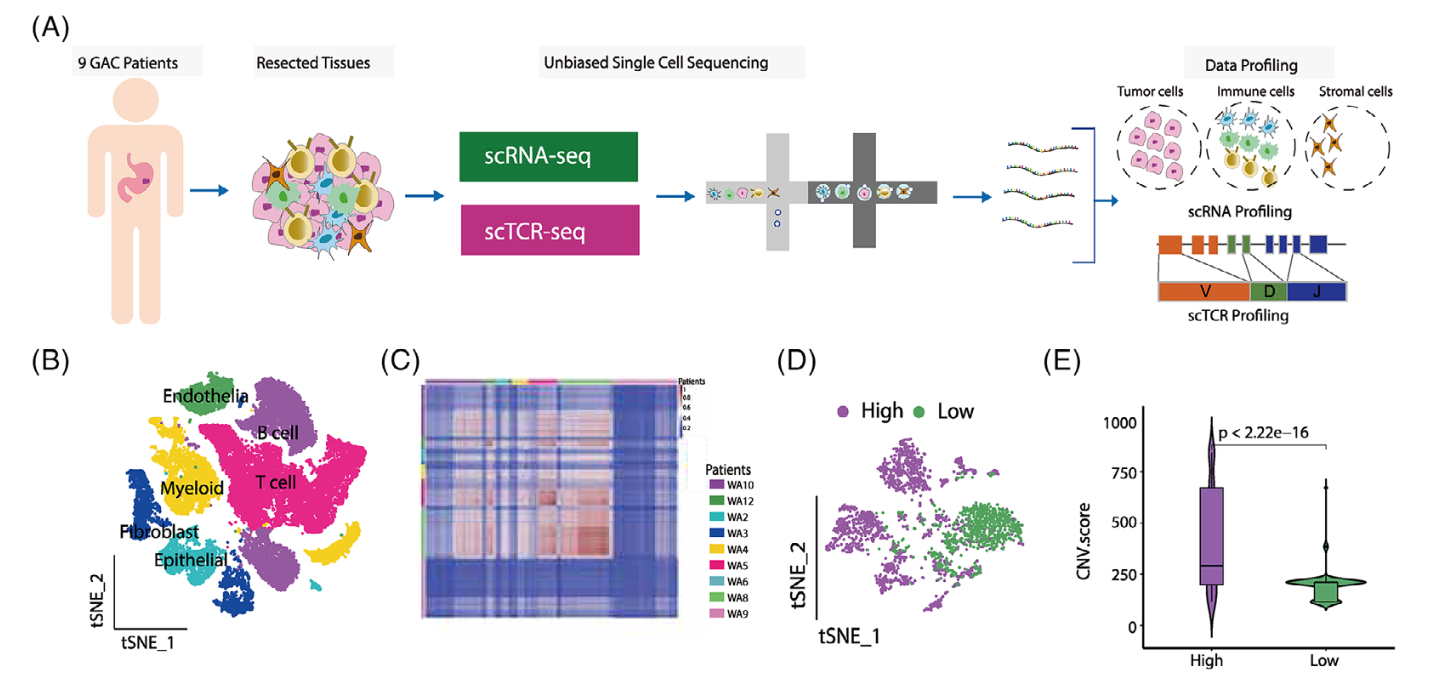
重点是 (D) t-SNE plot of cancer cells that are colour-coded according to its ITH level: purple: ITH-high; green: ITH-low.
通常我们拿到了肿瘤相关的单细胞转录组的表达量矩阵后的第一层次降维聚类分群通常是:
- immune (CD45+,PTPRC),
- epithelial/cancer (EpCAM+,EPCAM),
- stromal (CD10+,MME,fibro or CD31+,PECAM1,endo)
参考我前面介绍过 CNS图表复现08—肿瘤单细胞数据第一次分群通用规则,这3大单细胞亚群构成了肿瘤免疫微环境的复杂。绝大部分文章都是抓住免疫细胞亚群进行细分,包括淋巴系(T,B,NK细胞)和髓系(单核,树突,巨噬,粒细胞)的两大类作为第二次细分亚群。但是也有不少文章是抓住stromal 里面的 fibro 和endo进行细分,并且编造生物学故事的。上面的胃癌单细胞文章也是如此,第一层次降维聚类分群得到了6个经典亚群,分别是:epithelial cells, endothelial cells, fibroblasts, B cells, T cells, and myeloid cells
因为是肿瘤单细胞转录组,所以常规鉴定上皮细胞里面的恶性细胞是必不可少的操作,Malignant epithelial cells were identified using infer- CNV
这个时候,作者在 (Figure 1C) 展示了一个相关性热图:Evaluation of pair-wise similarity of cancer cell transcriptomics revealed distinct levels of intra- tumour heterogeneity (ITH) across patients
根据上面的 ITH score 就可以把病人区分成为了 purple: ITH-high; green: ITH-low.
在查询这个 单细胞水平的肿瘤的 ITH score 我发现其实早在2019的肝癌文章就出现了。肝癌(数据集:GSE125449)
2019的文章:《Tumor Cell Biodiversity Drives Microenvironmental Reprogramming in Liver Cancer》,当时数据集公开了,是GSE125449,而且可以看到公式都是类似的,在每个个体内部鉴定到了恶性单细胞之后做两两之间的相关性分析,然后看看相关性是否有多样性即可:
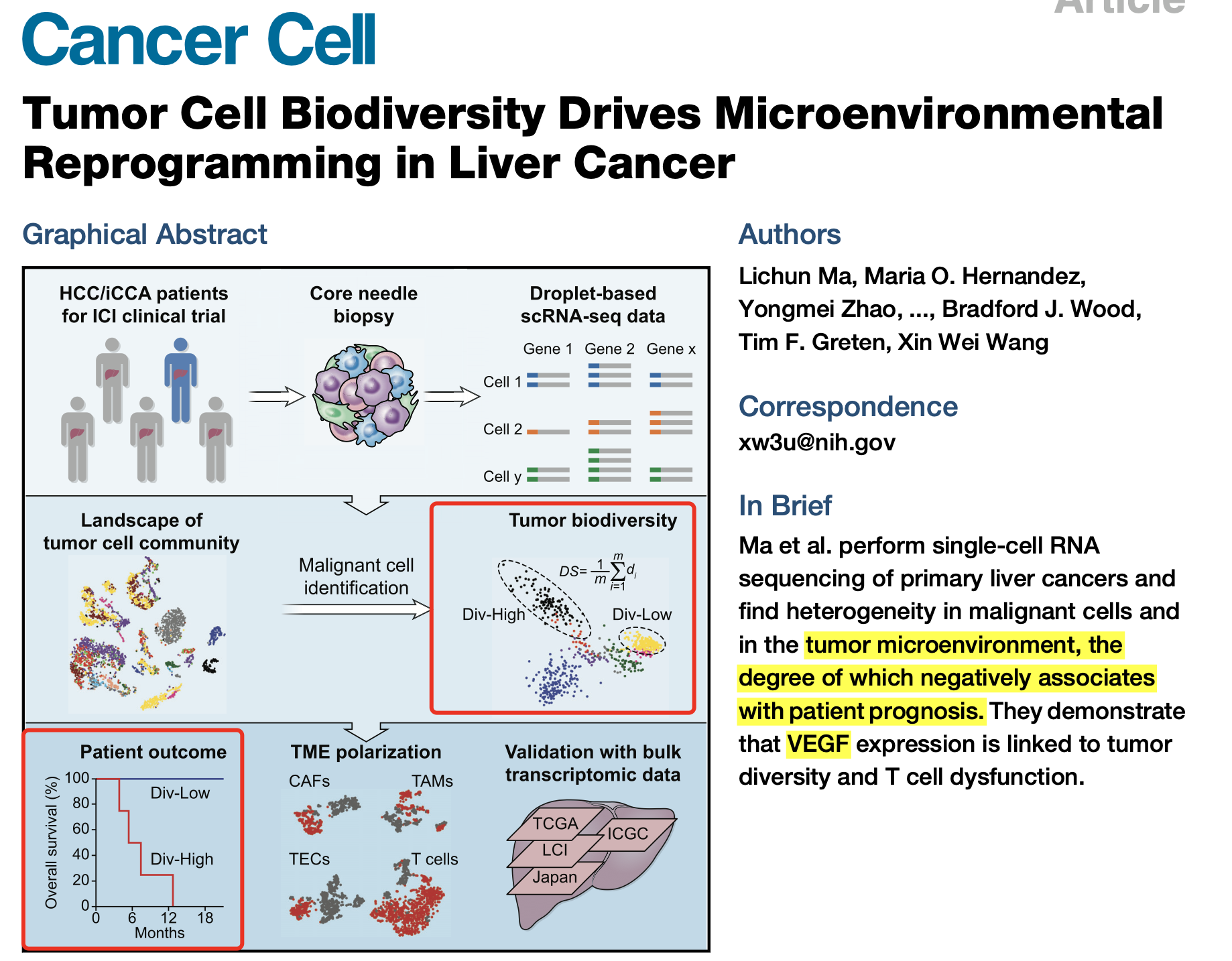
这个数据集比较奇特,因为GSE125449里面其实就两个10x技术的单细胞转录组样品,但是有19个病人的信息:
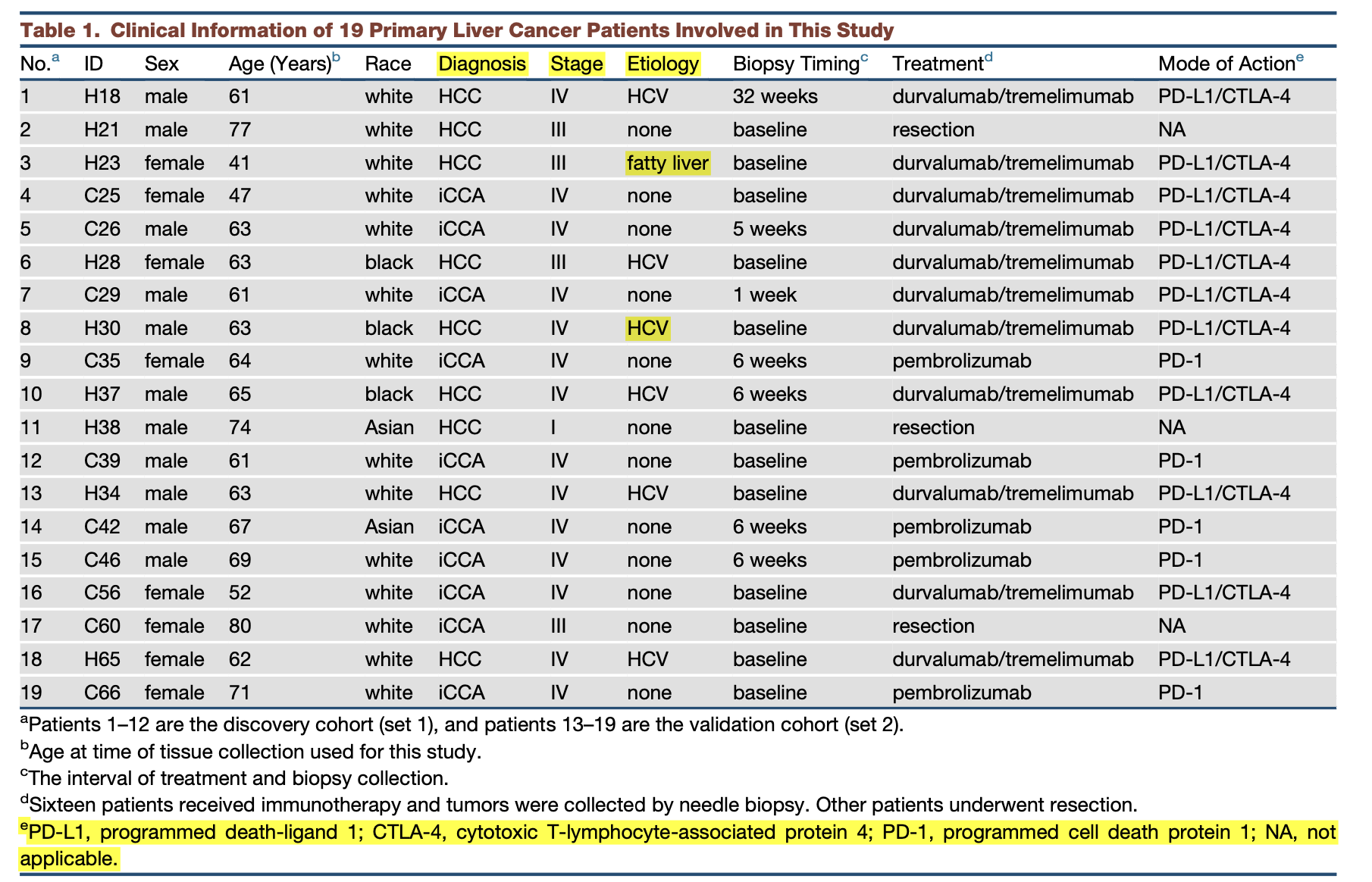
其就相当于是混合样品了,虽然可以拆分开来,但是就导致本来呢每个10x技术单细胞转录组应该是5000左右细胞数量但是拆分到每个病人就只剩下了三五百的细胞数量,这三五百的细胞还是包含了肿瘤免疫微环境的各种epithelial cells, endothelial cells, fibroblasts, B cells, T cells, and myeloid cells,所以其实哪怕是有大于20个恶性癌细胞的病人都只有其中的8个:
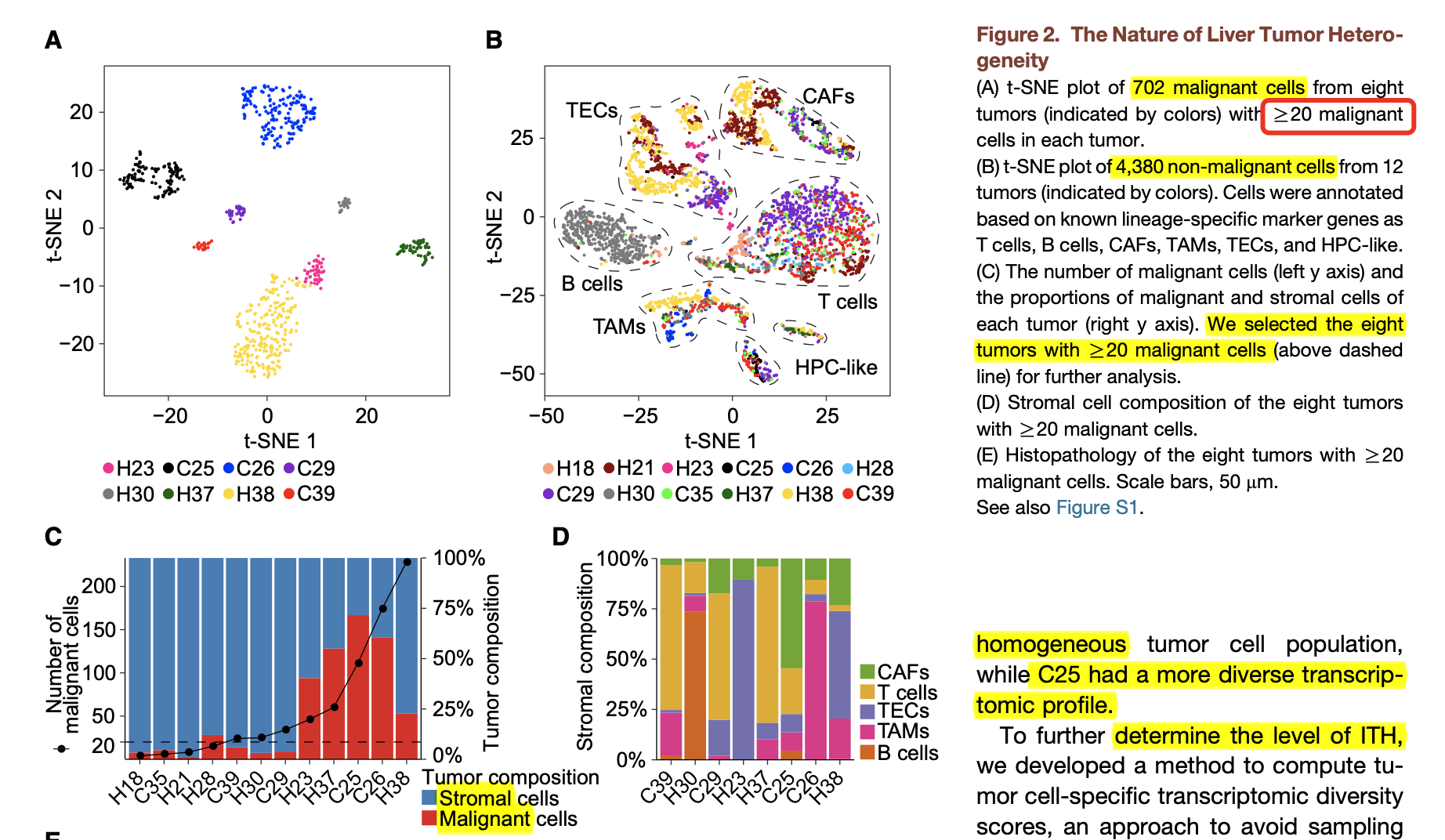
就是针对这8个病人去在每个个体内部鉴定到了恶性单细胞之后做两两之间的相关性分析,然后看看相关性是否有多样性,根据这个 ITH score 就可以把病人区分成为了 purple: ITH-high; green: ITH-low. 实际上,大家可以看到这个缺点是很明显的,因为是2019的文章所以那个时候的病人数量和单细胞数量都是严重不足的, 虽然说8个病人区分成为两组后有明显的生存分析统计学显著性。
然后这个数据集在2022有一个数据挖掘文章:《Single cell transcriptional diversity and intercellular crosstalk of human liver cancer》 - T cells (CD4, CD3E, CD3D, CD3G, CD8A, CD8B)
- B cells (CD79A, SLAMF7, BLNK, FCRL5)
- TECs (PECAM1, VWF, ENG, CDH5)
- CAFs (COL1A2, FAP, ACTA1, COL3A1, COL6A1)
- TAMs (CD14, CD163, CD68, CSF1R)
- HPC- like (EPCAM, KRT19, PROM1, ALDH1A1, CD24).
它实际上是重新分析了: ScRNA-seq data of tumor samples (n = 15; consistent with the original article, the sample would be taken into account only if it contains more than 20 tumor cells) (GEO: GSE125449), 然后算法也是类似的:

口腔癌
我看了一个2023的9月份的文章:《Single-cell transcriptomic analysis of gingivo-buccal oral cancer reveals two dominant cellular programs》,数据集是 GSE215403
它取样的时候是 12个病人,Oral squamous cell carcinoma of the gingivo-buccal region (OSCC-GB) ,但是呢,其中的3个病人是有 precancerous lesion (oral submucous fibrosis [OSMF]).的混入,第一层次降维聚类分群也是很清晰,然后区分成为了恶性肿瘤细胞和非恶性细胞的两个展示:
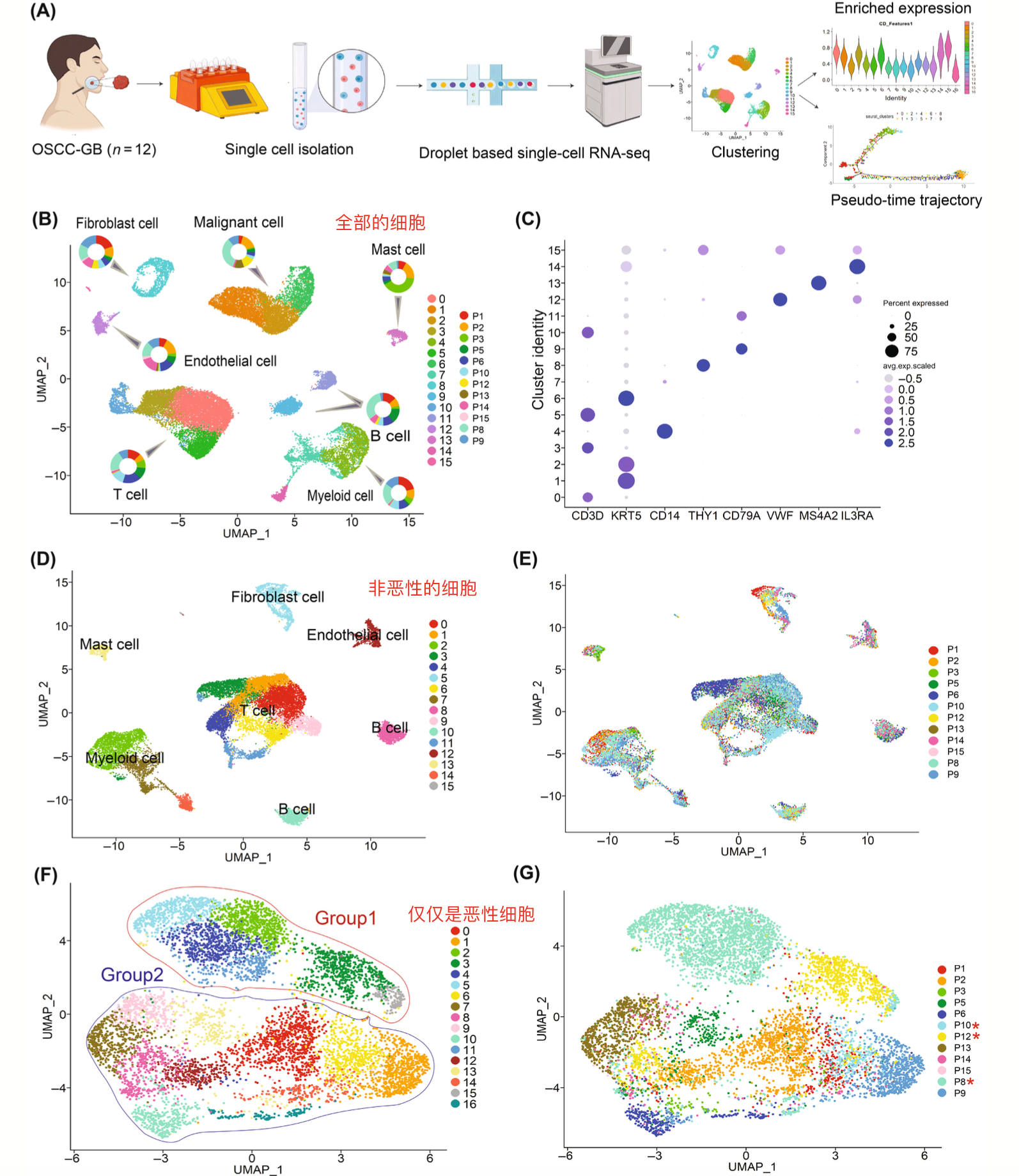
但是这里面的恶性细胞的分组是恰好group1就是前面提到的3个有precancerous lesion (oral submucous fibrosis [OSMF]).的混入的病人的,剩余的就是group2。
它并不是针对group2里面的病人的每个个体内部鉴定到了恶性单细胞之后做两两之间的相关性分析,然后看看相关性是否有多样性,根据这个 ITH score 就可以把病人区分成为了 purple: ITH-high; green: ITH-low.其它癌症
继续罗列下去没意思啦,我相信感兴趣的小伙伴一定会把这个关键词去谷歌学术或者PubMed去搜索看看的,单细胞+肿瘤+异质性。
希望这个整理对大家有帮助哦!