文章概述
文章标题:《The single-cell transcriptomic landscape of early human diabetic nephropathy 》
发表日期和杂志:2019年发表在PNAS
在线阅读链接:https://www.pnas.org/cgi/doi/10.1073/pnas.1908706116
单细胞实验设计
对冷冻保存的人类糖尿病肾脏样本进行了无偏单细胞RNA测序(snRNA-seq),从3个对照组和3个早期糖尿病肾病样本中生成了23,980个单细胞核转录组。
单细胞转录组数据情况
数据链接是:https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE131882
可以看到是6个样品:
GSM3823939 Control Sample 1 (snRNAseq)
GSM3823940 Control Sample 2 (snRNAseq)
GSM3823941 Control Sample 3 (snRNAseq)
GSM3823942 Diabetes Sample 1 (snRNAseq)
GSM3823943 Diabetes Sample 2 (snRNAseq)
GSM3823944 Diabetes Sample 3 (snRNAseq)
作者给出来的数据是每个样品一个压缩包格式的rds.gz:
GSM3823939_control.s1.dgecounts.rds.gz 343.8 Mb
GSM3823940_control.s2.dgecounts.rds.gz 176.0 Mb
GSM3823941_control.s3.dgecounts.rds.gz 290.1 Mb
GSM3823942_diabetes.s1.dgecounts.rds.gz 272.5 Mb
GSM3823943_diabetes.s2.dgecounts.rds.gz 178.4 Mb
GSM3823944_diabetes.s3.dgecounts.rds.gz 157.5 M
可以很简单的循环读取它们:
library(data.table)
dir='GSE131882_RAW/'
samples=list.files( dir,pattern = 'rds',full.names = T,recursive = T )
samples
library(data.table)
sceList = lapply(samples,function(pro){
# pro=samples[1]
print(pro)
sce=readRDS(pro)
ct = sce$umicount$exon$all
ct[1:4,1:4]
ct
library(AnnoProbe)
ids = annoGene(rownames(ct),'ENSEMBL','human')
head(ids)
table(duplicated(ids$SYMBOL))
ids=ids[!duplicated(ids$SYMBOL),]
pos = match(ids$ENSEMBL,rownames(ct))
ct = ct[pos,]
rownames(ct) =ids$SYMBOL
sce=CreateSeuratObject( ct ,
project = strsplit(gsub('.dgecounts.rds','', basename(pro) ),'_')[[1]][2] ,
min.cells = 5,
min.features = 300 )
return(sce)
})
names(sceList)
samples
library(stringr)
samples = str_split(gsub('.dgecounts.rds','', basename( samples) ),'_',simplify = T)[,2]
sce.all=merge(x=sceList[[1]],
y=sceList[ -1 ],
add.cell.ids = samples )
as.data.frame(sce.all@assays$RNA@counts[1:10, 1:2])
head(sce.all@meta.data, 10)
table(sce.all$orig.ident)
后面就是标准分析啦。
第一层次降维聚类分群
可以看到, 前面的从3个对照组和3个早期糖尿病肾病样本中生成了23,980个单细胞核转录组降维聚类分群后,绝大部分细胞都是上皮细胞,我们通过chatGPT查询到:人类肾脏组织的上皮细胞包括多个亚群,其中一些主要的亚群包括:
- 远曲小管细胞(Distal Convoluted Tubule Cells):远曲小管细胞位于肾小管系统的远曲小管部分,参与尿液的浓缩和酸碱平衡调节。
- 近曲小管细胞(Proximal Convoluted Tubule Cells):近曲小管细胞位于肾小管系统的近曲小管部分,参与尿液的重吸收和分泌。
- 集合管细胞(Collecting Duct Cells):集合管细胞位于肾小管系统的集合管部分,参与尿液的浓缩和酸碱平衡调节。
- 肾小管间质细胞(Renal Interstitial Cells):肾小管间质细胞位于肾小管系统的间质区域,提供支持和调节肾小管功能。
- 肾小球上皮细胞(Glomerular Epithelial Cells):肾小球上皮细胞位于肾小球的内层,参与尿液的初步过滤和选择性重吸收。
这些上皮细胞亚群在肾脏的功能中起着重要的作用,各自具有特定的形态和功能特征。
但是这个文章给出来的分群是:
-
PCT, proximal convoluted tubule
-
CFH, complement factorH
- LOH, loop of Henle
- DCT, distal convoluted tubule
- CT, connecting tubule
- CD, collecting duct
- PC, principal cell
- IC, intercalated cell
- PODO, podocyte
- ENDO, endothelium
- MES, mesangial cell
- LEUK, leukocyte
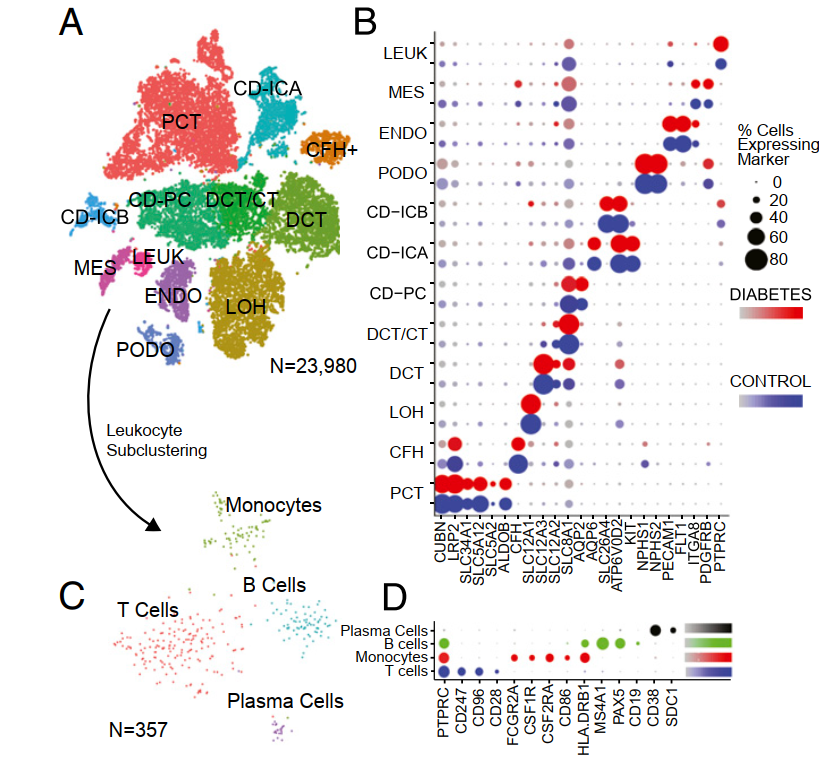
可以看到里面的淋巴细胞非常少,LEUK, leukocyte,而且作者也对淋巴细胞进行了细分。
其它加分项
因为这个实验设计是有分组的,这里是疾病和对照,所以每个单细胞亚群都是可以在两个分组做差异分析,差异分析就可以有火山图。
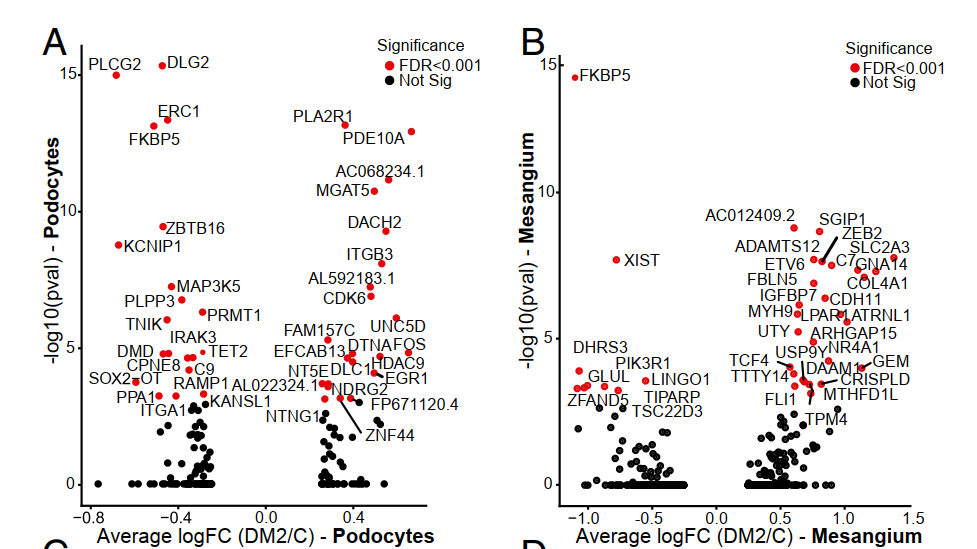
可以参考前些天才发布的练习题:多个单细胞亚群各自差异分析后如何汇总可视化