这两天看到了各种交流群以及朋友圈小伙伴都在转发和祝贺张泽民课题组的泛癌层面NK单细胞数据挖掘文章, 我简单看了看,类似的策略的数据挖掘居然一直可以发CNS级别杂志,让人膜拜:
- 2021年2月发表在CELL的《A pan-cancer single-cell transcriptional atlas of tumor infiltrating myeloid cells》
- 2021年12月发表在science的《Pan-cancer single cell landscape of tumor-infiltrating T cells》
- 2023年9月发表在CELL的《A pan-cancer single-cell panorama of human natural killer cells》
算起来就差nature杂志啦,而且都在针对于肿瘤相关单细胞数据集的挖掘。通常我们拿到了肿瘤相关的单细胞转录组的表达量矩阵后的第一层次降维聚类分群通常是:
- immune (CD45+,PTPRC),
- epithelial/cancer (EpCAM+,EPCAM),
- stromal (CD10+,MME,fibro or CD31+,PECAM1,endo)
参考我前面介绍过 CNS图表复现08—肿瘤单细胞数据第一次分群通用规则,这3大单细胞亚群构成了肿瘤免疫微环境的复杂。绝大部分文章都是抓住免疫细胞亚群进行细分,包括淋巴系(T,B,NK细胞)和髓系(单核,树突,巨噬,粒细胞)的两大类作为第二次细分亚群。但是也有不少文章是抓住stromal 里面的 fibro 和endo进行细分,并且编造生物学故事的。
如果按照张泽民课题组数据挖掘能力,还可以再发15篇CNS文章,各种交流群以及朋友圈小伙伴都表示了实名羡慕。虽然说大家发CNS主刊文章有点悬,但是CNS子刊还是可以试试看,不需要在泛癌层面看某个具体单细胞亚群的细分,可以在每个癌症看各自的特殊性,数据量和工作量就低了一个数量级。比如各个组织器官的特色上皮细胞亚群以及其对应的标记基因列表:
能带动一波数据挖掘文章吗?
但是也有部分小伙伴表示,这个张泽民课题组的泛癌层面NK单细胞水平分群及其标记基因能带动一波数据挖掘文章,让大家赶快去使用他们的结果去做数据挖掘文章,最近单细胞数据挖掘文章如雨后春笋般冒出来了,总体来说就两个方向:
- 找到一个数据集,降维聚类分群后,拿到基因列表后,去TCGA建模
- 首先TCGA建模然后拿模型里面的基因去单细胞转录组数据集看是否有特殊的表现
这两个方向都需要掌握基础的单细胞转录组数据集的降维聚类分群,但是因为张泽民课题组的泛癌层面已经对各个单细胞亚群做完了单细胞水平分群并且得到了其标记基因,实际上它就是一个数据库资源:
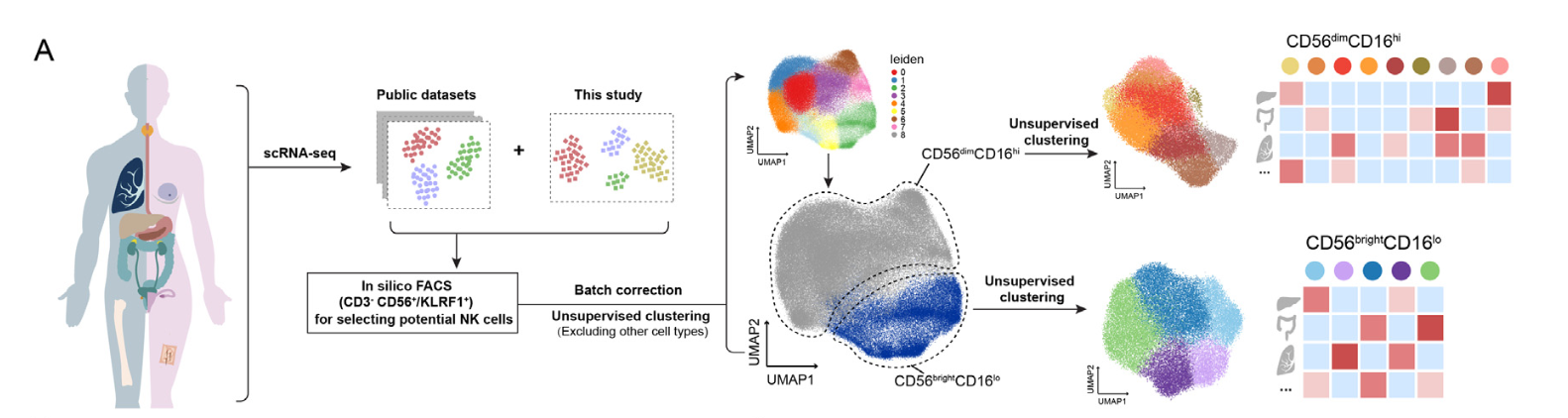
不同层级的NK细胞亚群里面的基因列表就可以无缝连接到下游的数据挖掘文章啦。
- 取交集(差异分析基因,生存分析基因,wgcna基因)
- LASSO等机器学习建模
- 验证集看模型好坏
- 模型预测的风险分组后看其它组学(突变差异,甲基化差异,药物差异,免疫浸润差异)
那么事实真的是这样的吗?
前面提到了其实泛癌层面NK之前还有t细胞和髓系,但是也没有人去基于这些结果去做数据挖掘,因为绝大部分让都是可以自己找到一个数据集,降维聚类分群后,拿到基因列表后,去TCGA建模。比如NK就有:
- Identification and Validation of a Novel Signature Based on NK Cell Marker Genes to Predict Prognosis and Immunotherapy Response in Lung Adenocarcinoma by Integrated Analysis of Single-Cell and Bulk RNA-Sequencing
- Integrated analysis of single‐cell and bulk RNA‐sequencing identifies a signature based on NK cell marker genes to predict prognosis and immunotherapy response in hepatocellular carcinoma
- The Novel-Natural-Killer-Cell-Related Gene Signature Predicts the Prognosis and Immune Status of Patients with Hepatocellular Carcinoma
这些数据挖掘文章名字都很长,但是换汤不换药,也完全不需要使用张泽民课题组的泛癌层面NK单细胞水平分群及其标记基因。比如我们拿到上面的3个文章的第一个细看;
- GSE131907, we obtained gene expression profiles of 45,149 cells from 11 primary LUAD
- 17 cell clusters were then identified , and cells in cluster 7 were defined as NK cells
- 189 genes (LUAD-related NK cell marker genes) differentially expressed between the 17 clusters
- To construct a prognostic signature based on the 189 NK cell marker genes,
- LASSO Cox regression analysis 后是
其实这些数据挖掘文章并不真正想探索什么是NK,或者说肿瘤里面的NK有什么功能或有什么特殊性,仅仅是为了凑一个故事性,希望把基因数量弄得越来越小,而且还得有故事性有合理性。