前面我们分享了在单细胞转录组降维聚类分群的第一层次降维聚类分群后的,每个单细胞亚群细分的时候,是有 单细胞亚群的生物学命名的4个规则,如下所示 :
- 第一个规则:已知的生物学亚群
- 第二个规则:顺序编号加上特异性高表达量基因
- 第三个规则:生物学功能注释
- 第四个规则:转录因子等基因集特异性亚群(更多的生物学功能数据库)
然后在一个2023年底的nature文章:《IL-1β macrophages fuel pathogenic inflammation in pancreatic cancer 》,对应的数据集是GSE217845,它里面是10个胰腺癌的10x技术单细胞转录组数据,在第一层次降维聚类分群里面提前髓系免疫细胞后,继续细分降维聚类拿到里面的巨噬细胞,然后继续细分巨噬细胞的时候发现了里面其实是有热激蛋白的亚群,细胞增殖亚群,干扰素亚群,金属离子酶亚群,线粒体或者核糖体亚群偏好性亚群,或者低质量亚群。如下所示:
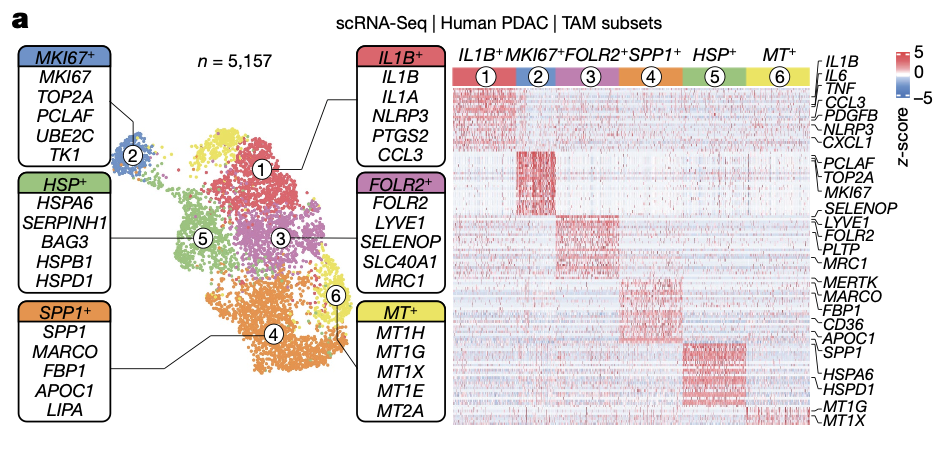
这个现象其实并没有什么问题,前面介绍过 CNS图表复现08—肿瘤单细胞数据第一次分群通用规则,这3大单细胞亚群构成了肿瘤免疫微环境的复杂。绝大部分文章都是抓住免疫细胞亚群进行细分,包括淋巴系(T,B,NK细胞)和髓系(单核,树突,巨噬,粒细胞)的两大类作为第二次细分亚群。但是也有不少文章是抓住stromal 里面的 fibro 和endo进行细分,并且编造生物学故事的。
前面我们已经介绍了心肝脾肺肾等多个器官的上皮细胞的细分亚群, 以及免疫细胞里面的髓系和B细胞细分亚群: - B细胞细分亚群
- 髓系免疫细胞细分亚群
比如t细胞和b细胞其实就都有naive的亚群,既然是按照功能划分亚群,那么不同来源单细胞亚群都可以细分到同样的亚群就比较容易理解了。但是如果做泛癌也分成了这样的亚群,是否有更好的解释呢,比如我刚刚看到了 复旦大小连发两个单细胞泛癌数据分析CNS正刊研究文章,其中里面的b细胞细分亚群就是如此:
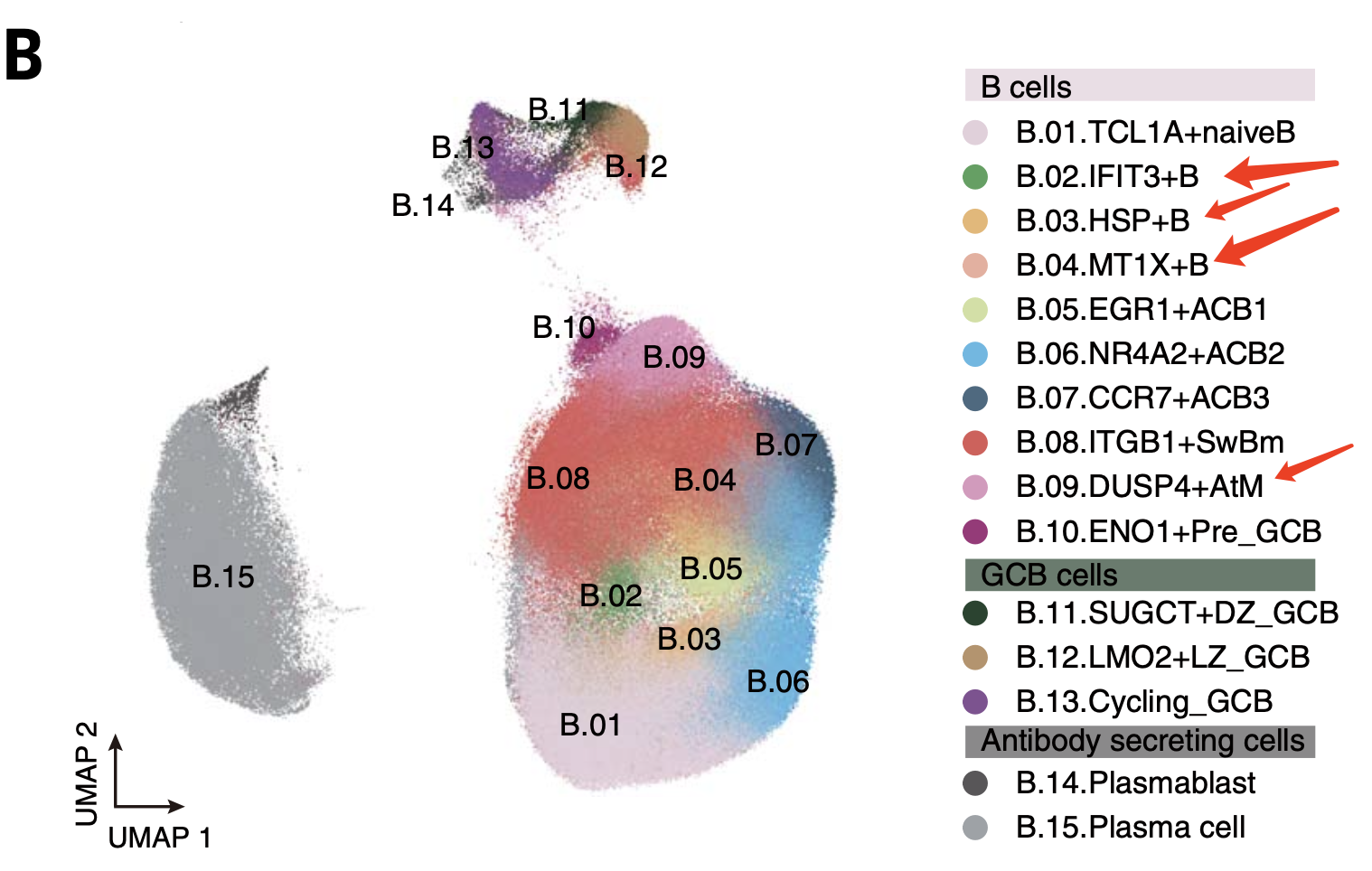
对初学者来说,确实是难以解释细分亚群出现的有热激蛋白的亚群,细胞增殖亚群,干扰素亚群,金属离子酶亚群,线粒体或者核糖体亚群偏好性亚群,或者低质量亚群。这就是生物信息学数据分析的魅力,很难有一以贯之的流程,分析过程的很多环节其实都需要数据分析人员认真的调参以及对结果的取舍!