通常我们拿到了肿瘤相关的单细胞转录组的表达量矩阵后的第一层次降维聚类分群通常是:
- immune (CD45+,PTPRC),
- epithelial/cancer (EpCAM+,EPCAM),
- stromal (CD10+,MME,fibro or CD31+,PECAM1,endo)
参考我前面介绍过 CNS图表复现08—肿瘤单细胞数据第一次分群通用规则,这3大单细胞亚群构成了肿瘤免疫微环境的复杂。绝大部分文章都是抓住免疫细胞亚群进行细分,包括淋巴系(T,B,NK细胞)和髓系(单核,树突,巨噬,粒细胞)的两大类作为第二次细分亚群。但是也有不少文章是抓住stromal 里面的 fibro 和endo进行细分,并且编造生物学故事的。第一个规则:已知的生物学亚群
一般来说,第一层次降维聚类分群后的各个单细胞亚群的生物学命名问题不大,比较麻烦的地方就是细分亚群啦。前面我们已经介绍了心肝脾肺肾等多个器官的上皮细胞的细分亚群, 以及免疫细胞里面的髓系和B细胞细分亚群:
- B细胞细分亚群
- 髓系免疫细胞细分亚群
可以看到,这个时候需要对每个亚群的生物学背景了如指掌,才有可能合理的命名。需要背诵尽可能的的基因和细胞亚群对应关系:# T Cells (CD3D, CD3E, CD8A), # B cells (CD19, CD79A, MS4A1 [CD20]), # Plasma cells (IGHG1, MZB1, SDC1, CD79A), # Monocytes and macrophages (CD68, CD163, CD14), # NK Cells (FGFBP2, FCG3RA, CX3CR1), # Photoreceptor cells (RCVRN), # Fibroblasts (FGF7, MME), # Endothelial cells (PECAM1, VWF). # epi or tumor (EPCAM, KRT19, PROM1, ALDH1A1, CD24). # immune (CD45+,PTPRC), epithelial/cancer (EpCAM+,EPCAM), # stromal (CD10+,MME,fibo or CD31+,PECAM1,endo)而且很多时候,细分亚群并不一定能找到全部的生物学亚群,而且我们这样的降维聚类分群通常是无监督的,也容易出现分群和生物学意义出图的情况,尤其是在t细胞亚群,我就基本上没有成功过,基本上每个文章都有自己的t细胞亚群命名方式。因为历史遗留原因,T细胞主要是区分成为CD8+ T cell 和 CD4+ T cell 两个大类,也可以是按照功能进行划分,naive, memory ,effector,cytotoxic,Exhaustion,如下所示:
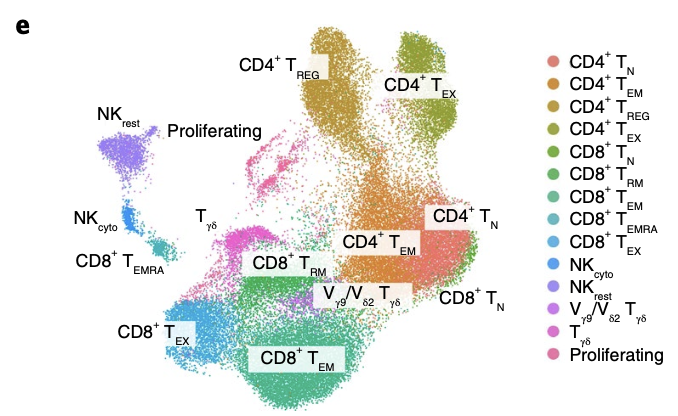
但是这个前提是你的单细胞转录组数据集里面的t细胞足够多,保证每个亚群都覆盖到,比如文章《Contribution of resident and circulating precursors to tumor-infiltrating CD8+ T cell populations in lung cancer》 ,就是 UMAP of 28,936 single CD3+ tumor-infiltrating T cells from 11 patients with NSCLC, 如下所示::
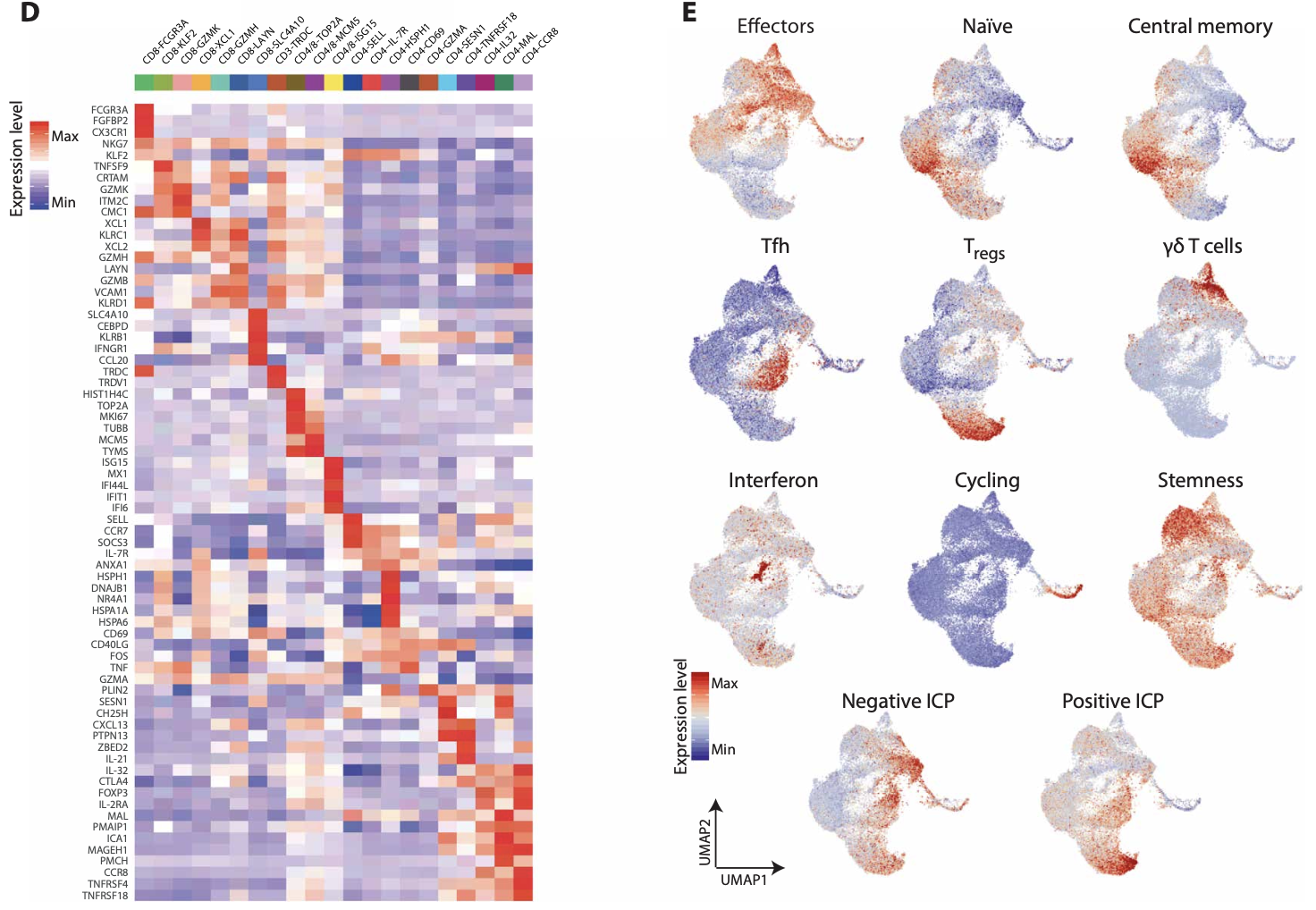
可以很明显看到,也是首先区分成为CD8+ T cell 和 CD4+ T cell 两个大类,然后是是按照功能进行划分,naive, memory ,effector,cytotoxic,Exhaustion:7 for CD8+ cells, 11 for CD4+ cells, 1 for T cells highly expressing IFN-related genes, and 2 for cycling T cells.
第二个规则:顺序编号加上特异性高表达量基因
因为细分亚群的时候如果足够细致,就有可能是没有生物学背景了,或者说人类的生物学知识还没有发展到达成共识,比如在巨噬细胞亚群里面,很早之前我们就总结过虽然虽然M1和M2的分类深入人心,但是在单细胞水平里面正确的做法可能是放弃M1和M2,详见:M1和M2的巨噬细胞差异就在CD86和CD163吗,很多单细胞文章都表明了巨噬细胞的M1和M2极化相关基因在单细胞水平是正相关。所以单细胞水平的细分亚群,我们不再是对巨噬细胞进行M1和M2的分类,如下所示的就仅仅是一个编号 :
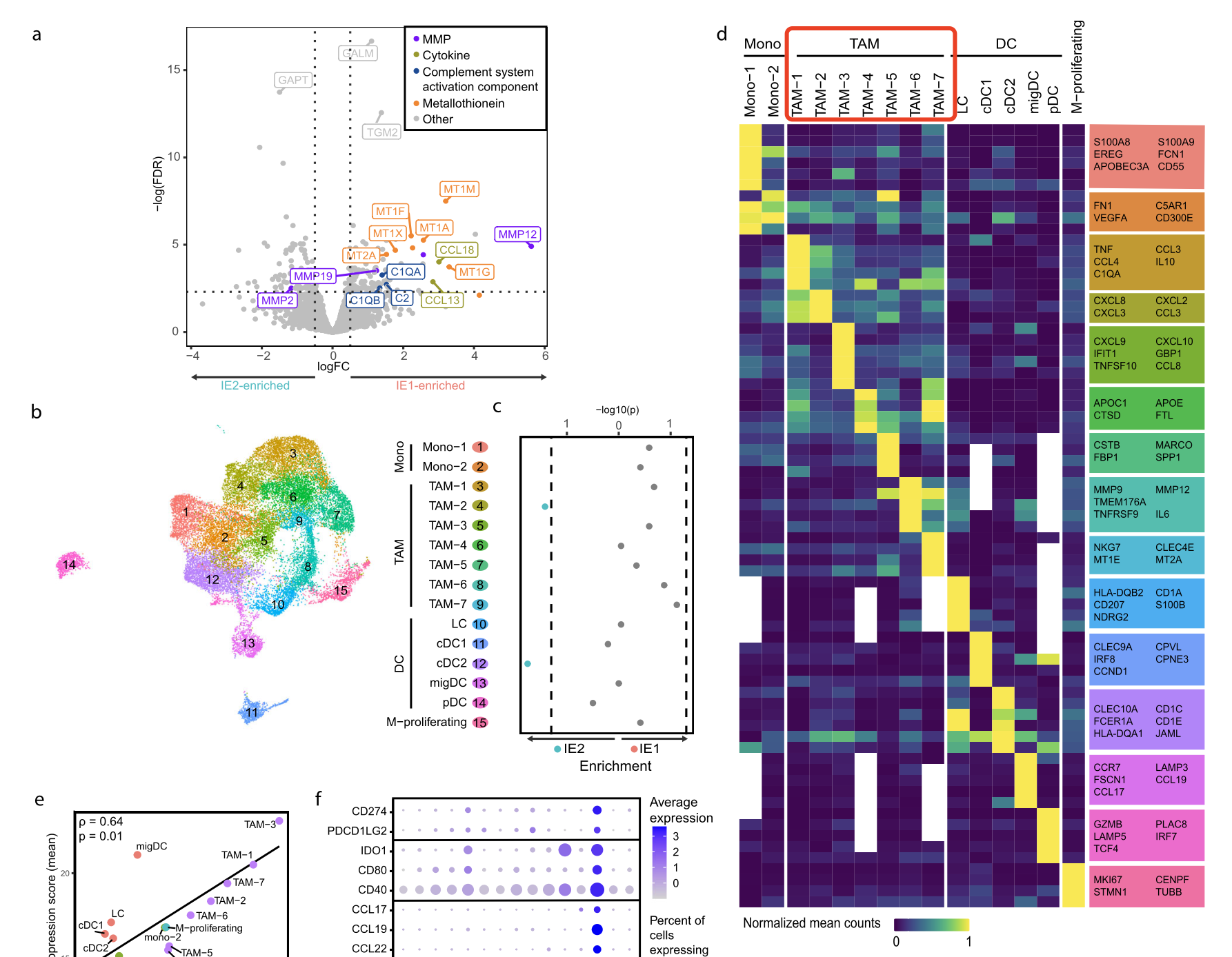
纯粹的编号不方便交流,不同文章的编号肯定是完全不一样的,所以通常是会在编号后面加上特异性高表达量基因。但是每个亚群的特异性高表达量基因有十几个甚至上百个,不同文章也有可能是选择了不一样的基因,这样的话也很难交流,比如下面的两个文章:

虽然说两个文章的巨噬细胞,都是6个亚群,但是很明显大家是不一样的,所以才会有特异性高表达量基因在旁边辅助大家认清楚它们!
上面的两个热图来源于两个不同的文章: - 《Single cell profiling of primary and paired metastatic lymph node tumors in breast cancer patients》
- 《IL-1β+ macrophages fuel pathogenic inflammation in pancreatic cancer》
而且几乎是可以确定的是如何使用特异性高表达量基因对细分的单细胞亚群进行命名,不同数据集肯定是产出不一样的结果,很难交叉对比,比如文章:《Pan-Cancer Single-Cell and Spatial-Resolved Profiling Reveals the Immunosuppressive Role of APOE**+ Macrophages in Immune Checkpoint Inhibitor Therapy**》但是大概率都会有 热激蛋白的亚群,细胞增殖亚群,干扰素亚群,金属离子酶亚群,线粒体或者核糖体亚群,或者低质量亚群。。。
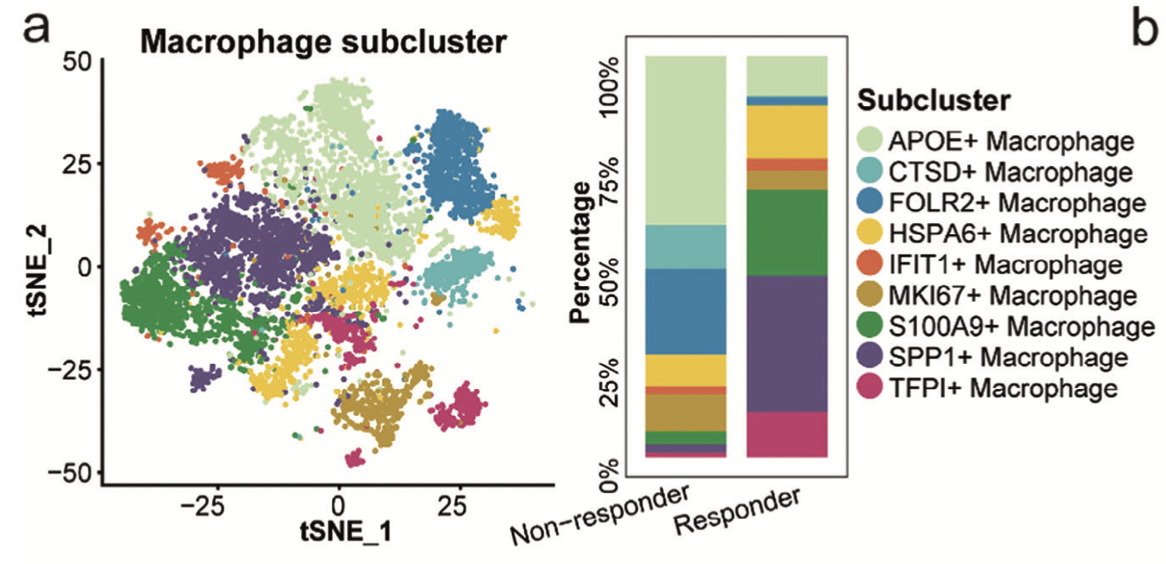
第三个规则:生物学功能注释
最经典的就是癌症相关成纤维细胞啦,比如文章:《Cancer-associated fibroblast classification in single-cell and spatial proteomics data》里面就有:
- Matrix CAFs (mCAFs):因为高表达量基因 encoding matrix proteins,
- Inflammatory CAFs (iCAFs): 因为高表达量基因参与 complement pathway (e.g., CFD and C3) 的生物学功能
- Vascular CAFs (vCAFs): 因为高表达量基因参与 angiogenesis
- Tumour-like CAFs (tCAFs): 因为高表达量基因 proliferation-, migration- and metastasis-associated genes (e.g., PDPN, MME, TMEM158 and NDRG1)
- heat-shock protein-high tCAFs (hsp_tCAFs) : 因为高表达量基因主要是那些 encoding heat-shock proteins including HSPH1 and HSP90AA1
- Interferon-response CAFs (ifnCAFs): 因为高表达量基因参与 response to interferons
- Antigen-presenting CAFs (apCAFs): 因为高表达量基因是 genes involved in MHC-II-associated antigen presentation,
- Dividing CAFs (dCAFs): 高表达细胞增殖相关基因,cell division (e.g., TUBA1B and MKI67

其实如果你留意这个生物学功能亚群命名的规则,和前面的特异性高表达量基因命名方式,你会发现一个很有意思的地方,就是不同单细胞转录组数据集的降维聚类分群其实都会有 热激蛋白的亚群,细胞增殖亚群,干扰素亚群,金属离子酶亚群,线粒体或者核糖体亚群,或者低质量亚群。。。第四个规则:转录因子等基因集特异性亚群(更多的生物学功能数据库)
有些时候,细分亚群后的各个子集的特异性基因不明显,或者注释到的生物学功能(GO或者KEGG数据库资源)不好解释,我们会求助于更多的生物学功能数据库,甚至转录因子分析!
关键问题:如何合理的命名
- 如果是第一层次降维聚类分群,那么通常是可以有具体的生物学名字,毕竟是上皮细胞和内皮细胞肯定是泾渭分明
- 如果是第二层次,还是可以看到具体的生物学名字,血管内皮和淋巴内皮,髓系里面的树突细胞和巨噬细胞等等都还是可以泾渭分明的
- 如果是第三层次,通常是看生物学功能了,因为大概不同亚群很难有清晰界限,比如t细胞亚群,巨噬细胞亚群,成纤维细胞亚群
- 如果是单细胞亚群功能失常,只能说看具体生物学功能或者转录因子等基因集特异性了,比如癌细胞的细分亚群