看到了《单细胞天地》公众号分享了一个中山大学孙逸仙纪念医院的新鲜出炉的单细胞文章:PDGFRα+ITGA11+成纤维细胞通过 ITGA11-SELE 相互作用促进早期癌症的淋巴血管侵袭和淋巴转移,是13个scRNA样本,包括4个癌旁,6个淋巴血管侵犯(LVI)positive,3个LVI negative。对应的数据集是:GSE222315
文章主要是关注点是淋巴管血管侵犯(Lymphovascular Invasion, LVI) 以及 肿瘤相关的成纤维细胞:
其中,淋巴管血管侵犯(Lymphovascular Invasion, LVI)是指在淋巴管或血管中发现肿瘤细胞的情况,它是评估膀胱癌预后的一个重要因素。LVI的存在与膀胱癌患者的生存率降低、复发风险增加和疾病进展风险升高密切相关。在膀胱癌的风险分层、预后评估和治疗决策中,LVI的识别和评估具有重要作用。

很容易整理这个数据集 GSE222315 页面提供的表达量矩阵文件后读取,常规的单细胞转录组降维聚类分群代码可以看 :链接: https://pan.baidu.com/s/1bIBG9RciAzDhkTKKA7hEfQ?pwd=y4eh ,基本上大家只需要读入表达量矩阵文件到r里面就可以使用Seurat包做全部的流程。在前面的笔记里面我们也测试了它的第一层次降维聚类分群:一直混入到其它单细胞亚群是为什么呢 ,以及它的各个亚群的细分。
因为文章主要关注点是成纤维细胞亚群的细分,如下所示,其实很明显的可以看到这个编号1的成纤维亚群是可以细分的,虽然说编号1的成纤维亚群确实是在LVI阳性组里面要高于阴性组的,但是如果它细分之后可能会规律不一样哦!
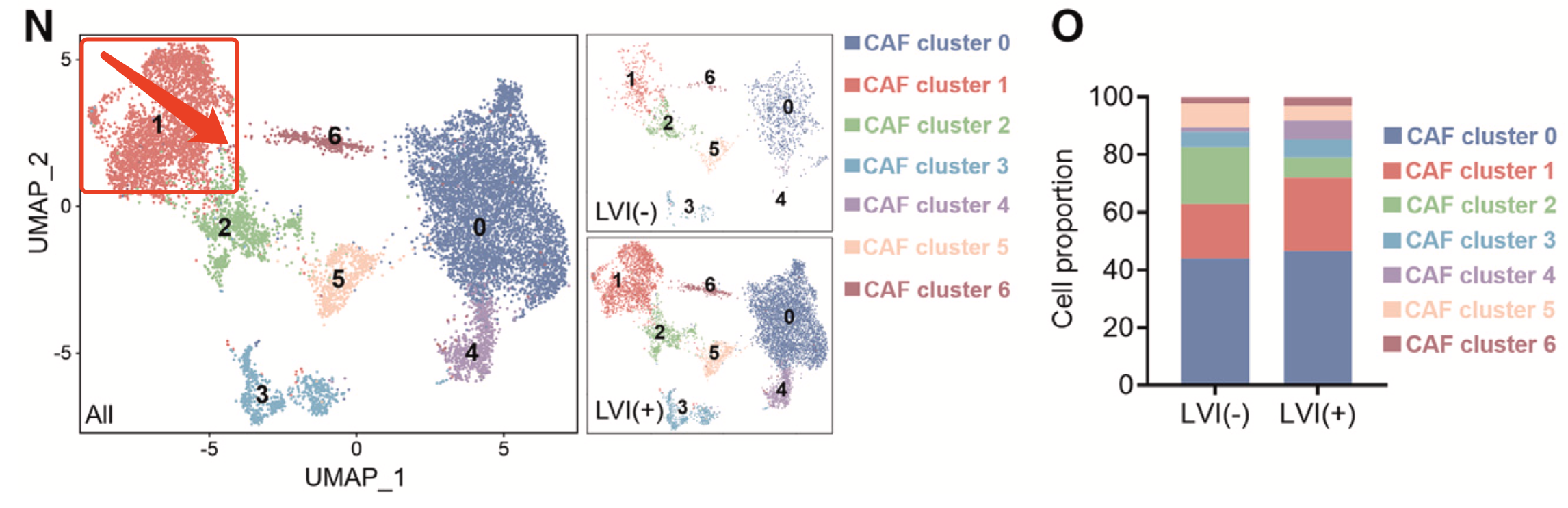
作者也确实是给这些亚群都找出来了它们自己的各自的特异性基因,但是下面的热图也可以很清晰的看到这个 编号1的成纤维亚群 的是可以细分的:

因为这个研究的单细胞队列里面其实病人数量太少了,文章附件有病人信息,是可以根据 LVI 来进行分组:
所以前面作者虽然是分组展示了编号1成纤维亚群确实是在LVI阳性组里面要高于阴性组的,但是并不会给出来 统计学指标,因为单细胞层面拿到的细胞比例很容易受样品异质性影响而达不到统计学显著要求。我们可以对作者提供的表达量矩阵,做同样的降维聚类分群,如下所示:
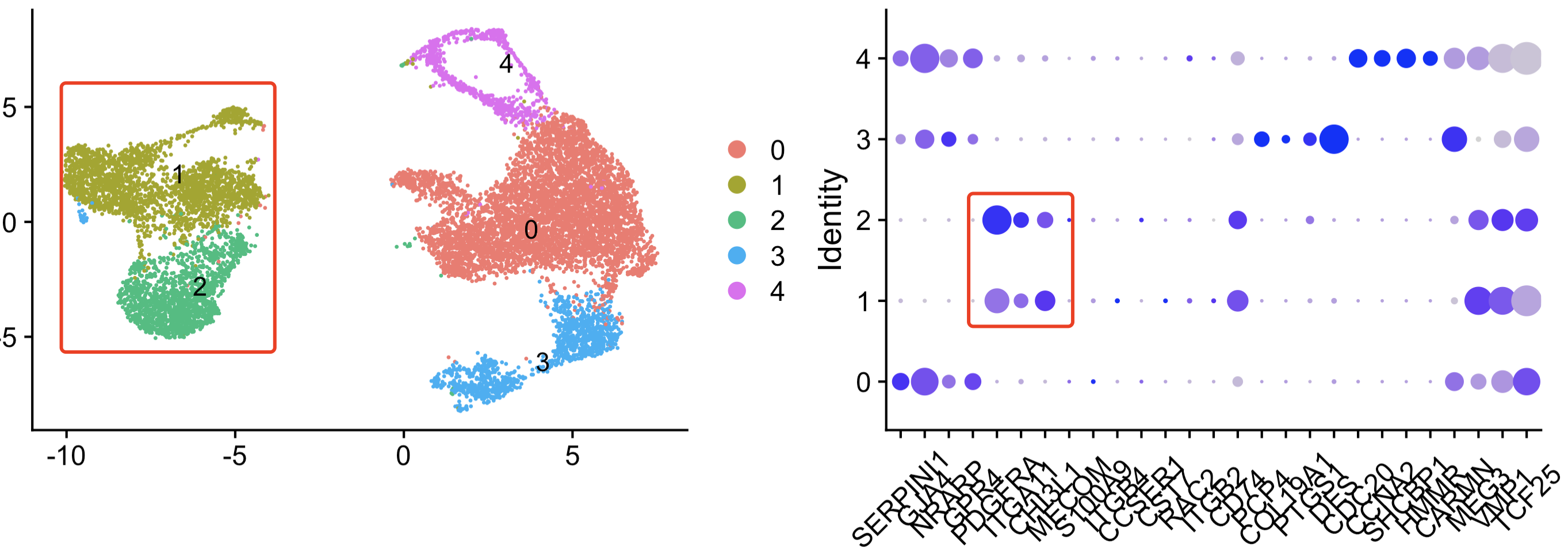
可以看到的是作者的编号1成纤维亚群被我们拆分成为了1和2两个亚群,作者的编号2和3亚群在我这里直接就消失了,同时消失的还有作者的编号为6的亚群。这个都是合理的,因为不同人做数据分析的时候大家的选择不一样哈!详见::一直混入到其它单细胞亚群是为什么呢
因为我在提取里面的成纤维细胞亚群后,重新进行降维聚类分群,可以看到里面仍然是可以区分出来 t细胞,髓系免疫细胞,内皮细胞,以及上皮细胞的。其中4是t细胞,5是髓系,7是内皮细胞,8是上皮细胞。作者的编号2和3亚群其实就是免疫细胞和上皮细胞啦,理论上是需要删除的哦。
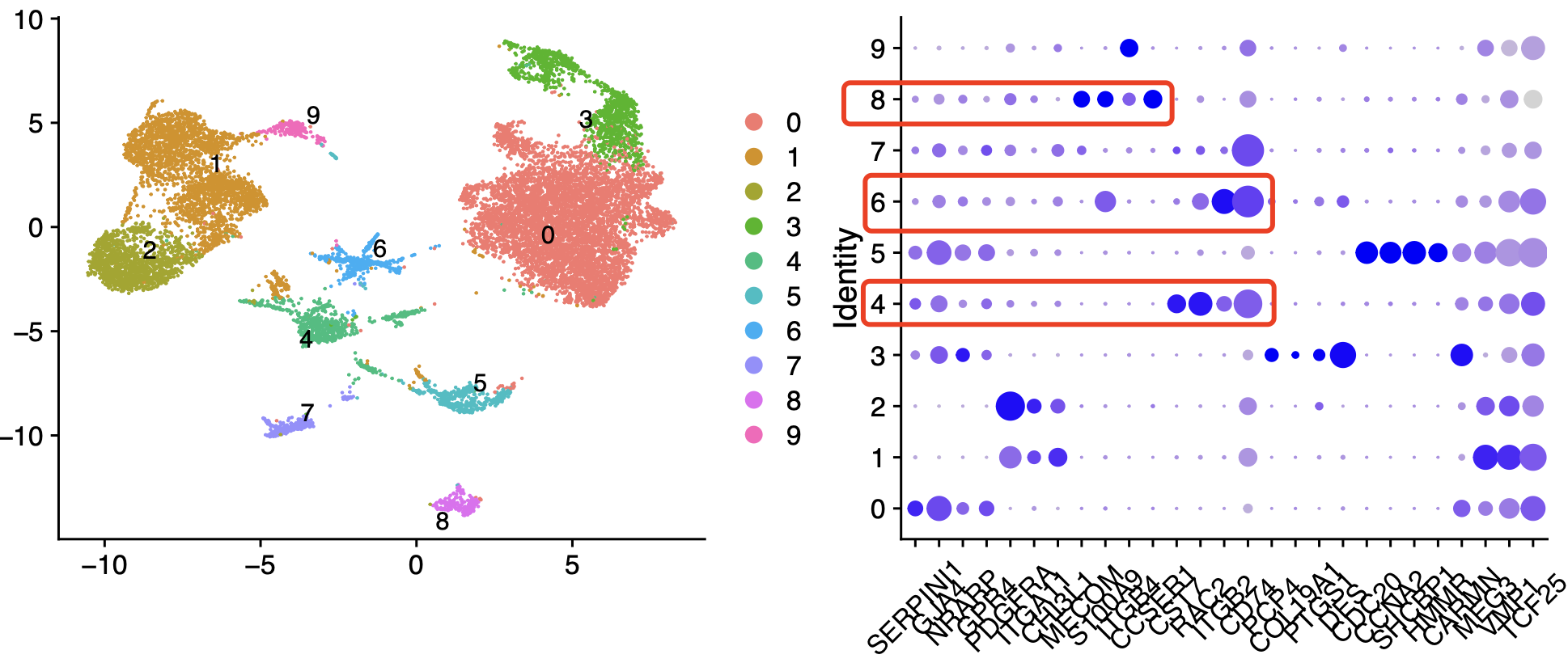
因为我删除了成纤维里面的混杂细胞亚群,所以我降维聚类分群的时候就是0到4编号的 5个亚群,它们在不同样品里面的细胞数量分布,如下所示:
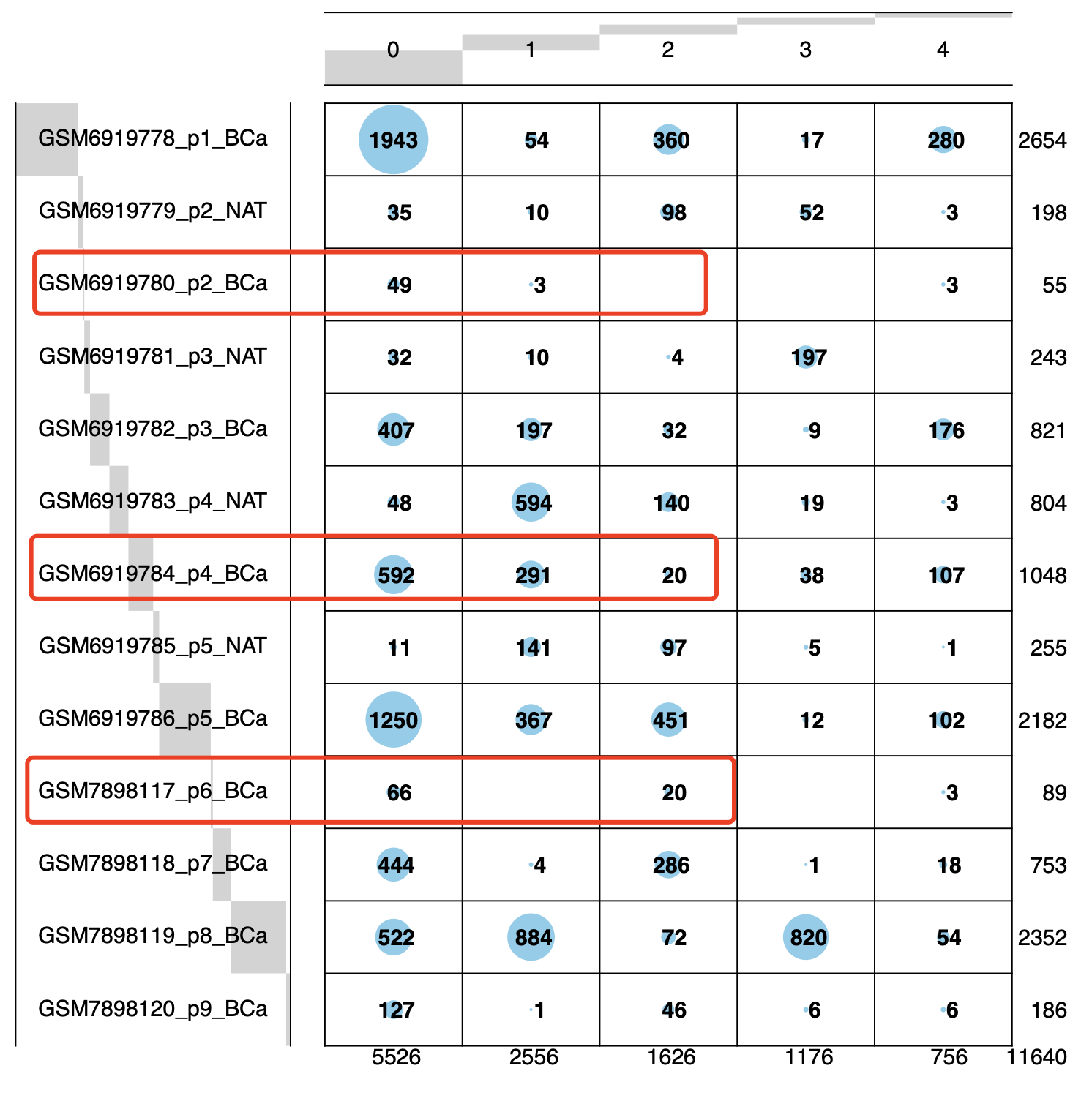
因为作者的编号1成纤维亚群被我们拆分成为了1和2两个亚群,可以看到这两个亚群在淋巴管血管侵犯(Lymphovascular Invasion, LVI)阴性的3个样品里面2个(p2和p6)都是微乎其微的,但是p4是一个例外。这样的话就很容易破坏整体的细胞比例对比的统计学显著性,所以作者机智地选择了去卷积后看这些单细胞亚群在tcga队列里面的推测的比例的差异情况:
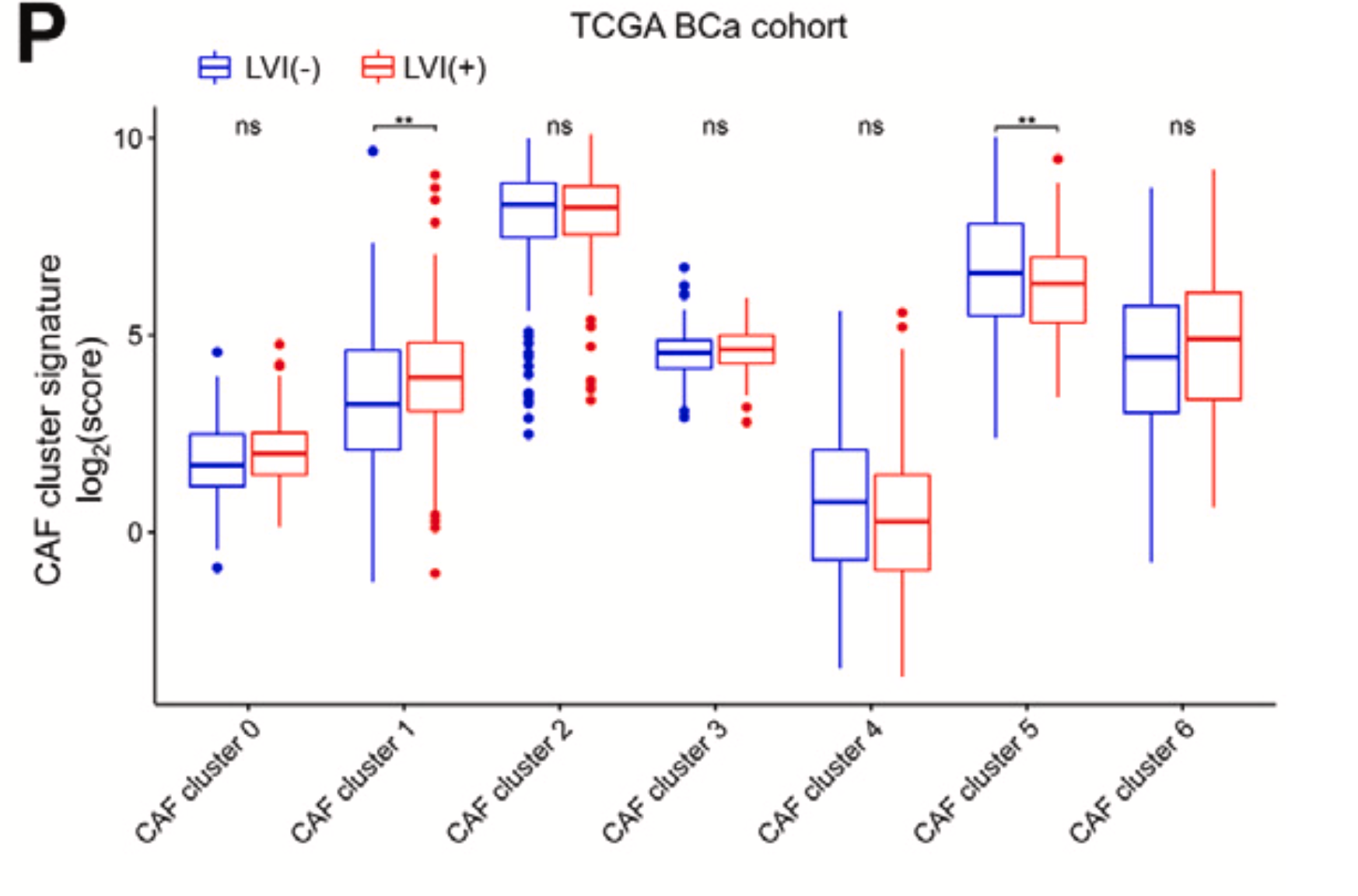
我仔细看了看图例,发现其并不是去卷积,是 (P) The relationship of CAF cluster infiltrated signature and BCa LVI from TCGA database (n = 347).
总结一下:
这个中山大学孙逸仙纪念医院的新鲜出炉的单细胞文章:PDGFRα+ITGA11+成纤维细胞通过 ITGA11-SELE 相互作用促进早期癌症的淋巴血管侵袭和淋巴转移,关注点就是 PDGFRα+ITGA11+成纤维细胞就是作者的 编号1的成纤维亚群 ,它确实是可以非常好的区分成为两个单细胞亚群,作者的编号2和3亚群其实就是免疫细胞和上皮细胞,但是因为并不是文章的重点所以这个小瑕疵就无伤大雅了。