前些天在我们生信技能树视频号直播一个文章的单细胞转录组数据(GSE208706)处理,文章是:《Amphiregulin from regulatory T cells promotes liver fibrosis and insulin resistance in non-alcoholic steatohepatitis》,因为我习惯了最开始采用比较低的分辨率的分群结果,如下所示的看分辨率是0.1的时候,可以看到9个亚群,它非常的狭长,而且呢,上面的有上皮细胞和成纤维两种截然不同的细胞亚群的基因高表达,很容易仍然联想到双细胞啦:
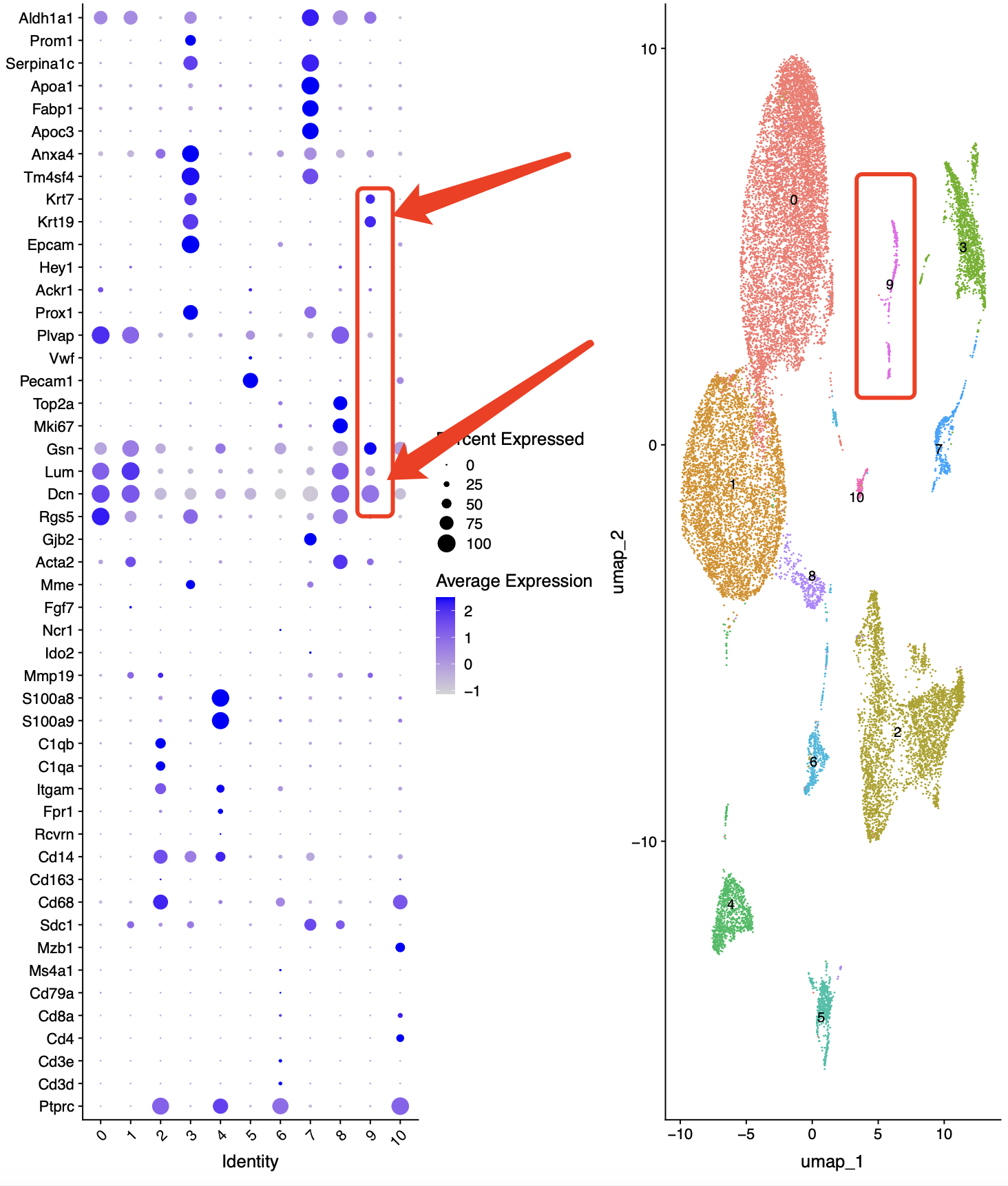
因为我在我们生信技能树视频号直播时候就是简单的分了大类,这个也是我常规的操作。代码在:(链接: https://pan.baidu.com/s/1pKEnPmWXi-pTab0WZUWzgg?pwd=a7s1) ,这样的话大家会很困惑,认为我的操作不可接受,总不能说就把这个编号为9的亚群命名为双细胞吧。其实不然,我们一般来说,会看质量控制图表来第一次尝试确认编号为9的亚群是否是双细胞,主要是看每个亚群的单个细胞的总的RNA数量啦:
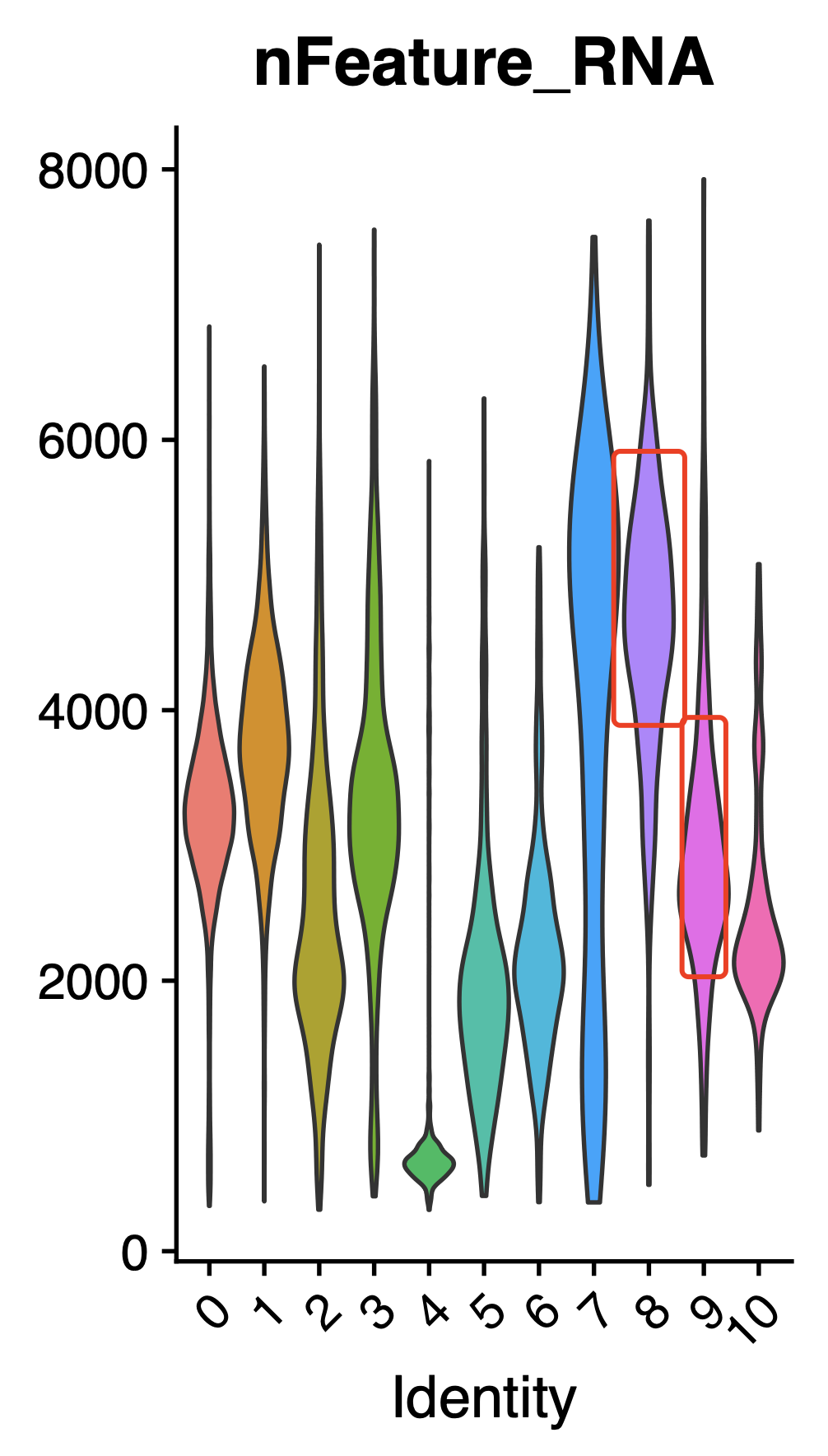 可以看到,编号为8的亚群反而是单个细胞里面的RNA数量太多了,看起来是双细胞,不过你自己仔细看它的基因就会发现有top2a和mki67这样的细胞增殖基因,所以它处于细胞增殖时期,单个细胞里面的RNA数量也就是合理的了。
可以看到,编号为8的亚群反而是单个细胞里面的RNA数量太多了,看起来是双细胞,不过你自己仔细看它的基因就会发现有top2a和mki67这样的细胞增殖基因,所以它处于细胞增殖时期,单个细胞里面的RNA数量也就是合理的了。
而且,初步看起来,编号为9的亚群它并不是双细胞,因为单个细胞里面的RNA数量并不是很突出。那么就开始第二个推断,是不是因为分辨率不够呢,如果提高分辨率,其实是可以看到前面的编号为9的亚群可以继续细分成为两个单细胞亚群:
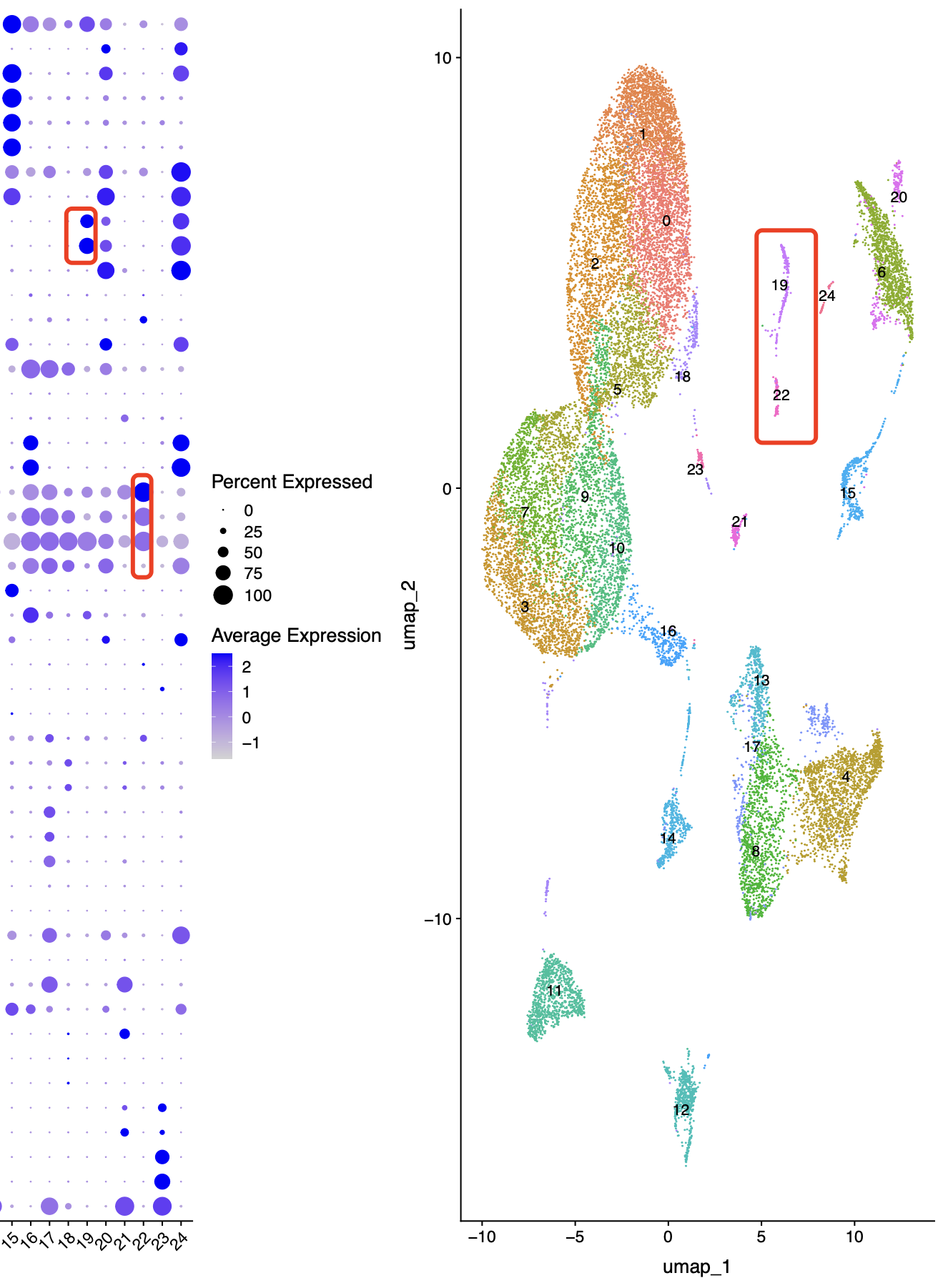
而且细分之后的19是上皮细胞,22是成纤维,这就是为什么之前它们两个组合成为了编号为9的亚群看起来是一个双细胞了。
那么,是否意味着我们的第一层次降维聚类分群的时候应该是尽可能的选择较大的分辨率呢,让细胞亚群数量尽可能的多一点。这个确实是应该的,而且我早就解释过了,详见:【第一层次降维聚类分群最好是分辨率调大一点 】,但是数据分析很多环节都是 trade-off 的艺术(大概是权衡、取舍、折中、折衷的意思),凡事过犹不及。
为什么不直接跑双细胞相关算法呢
目前,主流的单细胞转录组数据都是来源于10x技术,如果细胞数量是在5000到1万,其实双细胞的数量很少很少,并不会影响下游分析。如果是细胞数量太夸张,通常是并不是你跑双细胞相关算法能解决问题的,因为其它问题更麻烦。