为了分析不同类型、组织起源肿瘤的共性、差异以及新课题。TCGA于2012年10月26日-27日在圣克鲁兹,加州举行的会议中发起了泛癌计划。参考:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6000284/ 为此我也录制了系列视频教程在:TCGA知识图谱视频教程(B站和YouTube直达)
本文发表在一个很简单的杂志上面,PeerJ. 2016 Feb,被引用的次数也很少,才10次,题目是:A pan-cancer analysis of prognostic genes. 纳入16个不同癌症的6495个病人的RNA-seq数据,因为以前在癌症领域的生存分析大多关注单个基因,而且使用的是芯片表达数据,所以作者认为自己的研究是具有创新点的。
文献解读属于100篇泛癌研究文献系列,首发于:http://www.bio-info-trainee.com/4132.html
病人数量和癌症肿瘤
其实是非常简单的研究,很容易复现出来,而且KM或者COX这样的生存分析只是挑选重要基因的一种方法而已,更多的机器学习指标都是可以做到的。
分癌症种类的生存分析
可以看到每个癌症的生存基因都不一样,它们的前100个基因的重合情况非常少,如下图所示:
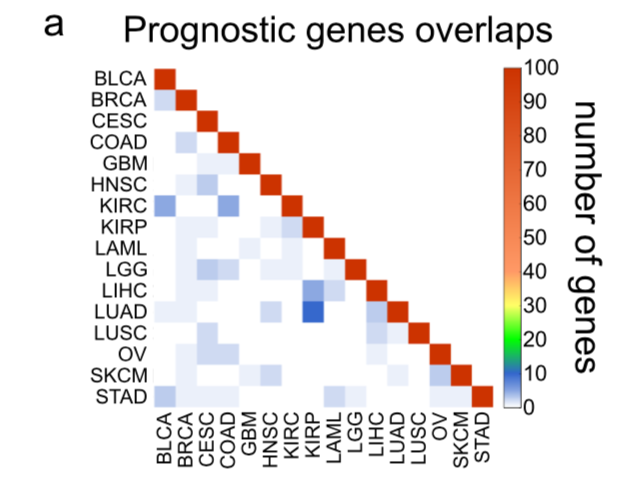
生存正相关基因和负相关基因
提取生存正相关基因和负相关基因集对应的表达矩阵进行聚类,可以看到它们的表达摸索很不一样,而且聚类后的生存分析非常显著。
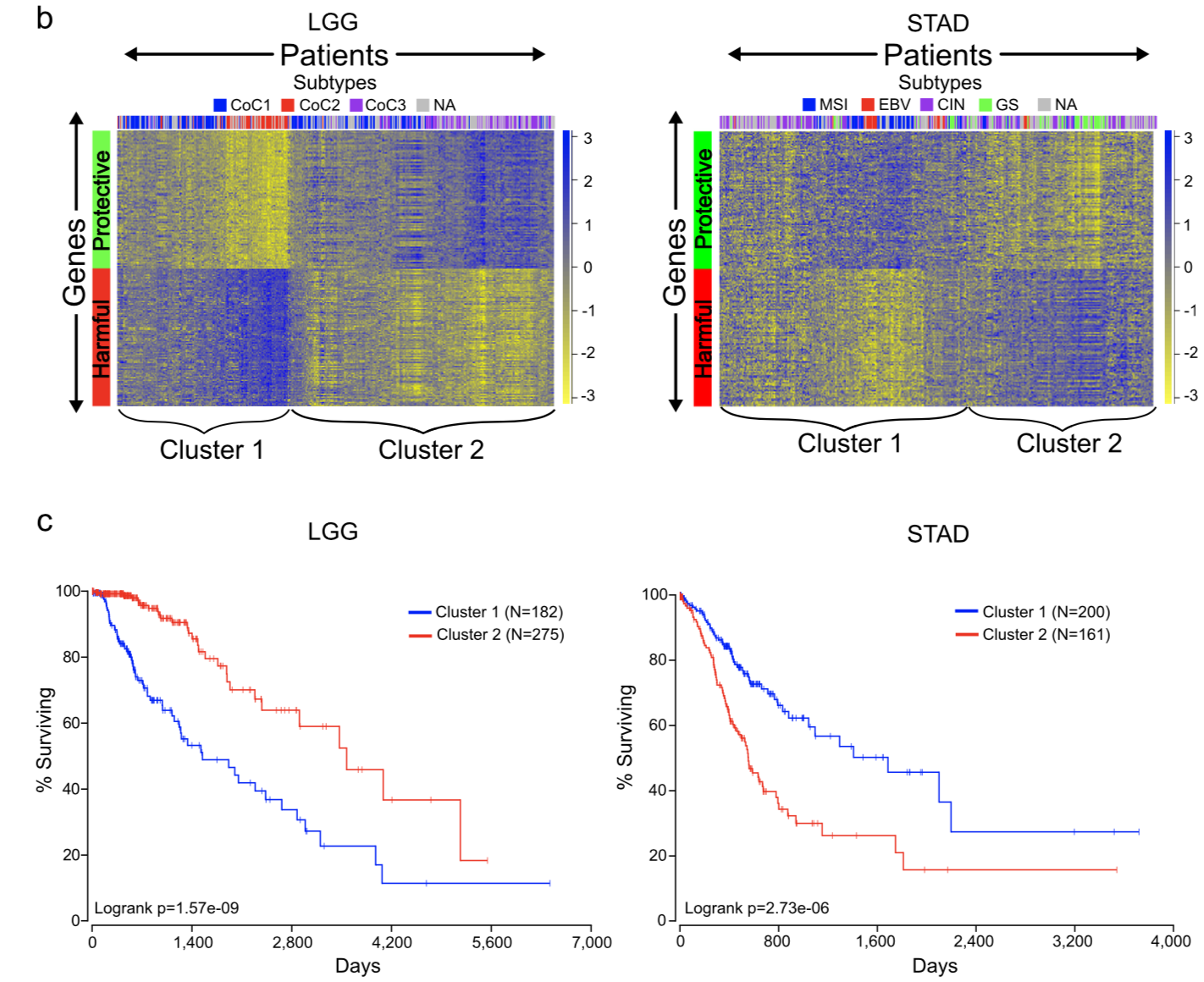
GSEA分析
全文最重要的就是对每个癌症的TOP250生存基因进行MsigDB数据库的富集分析,发现这些不同的癌症的重合情况就很好了。
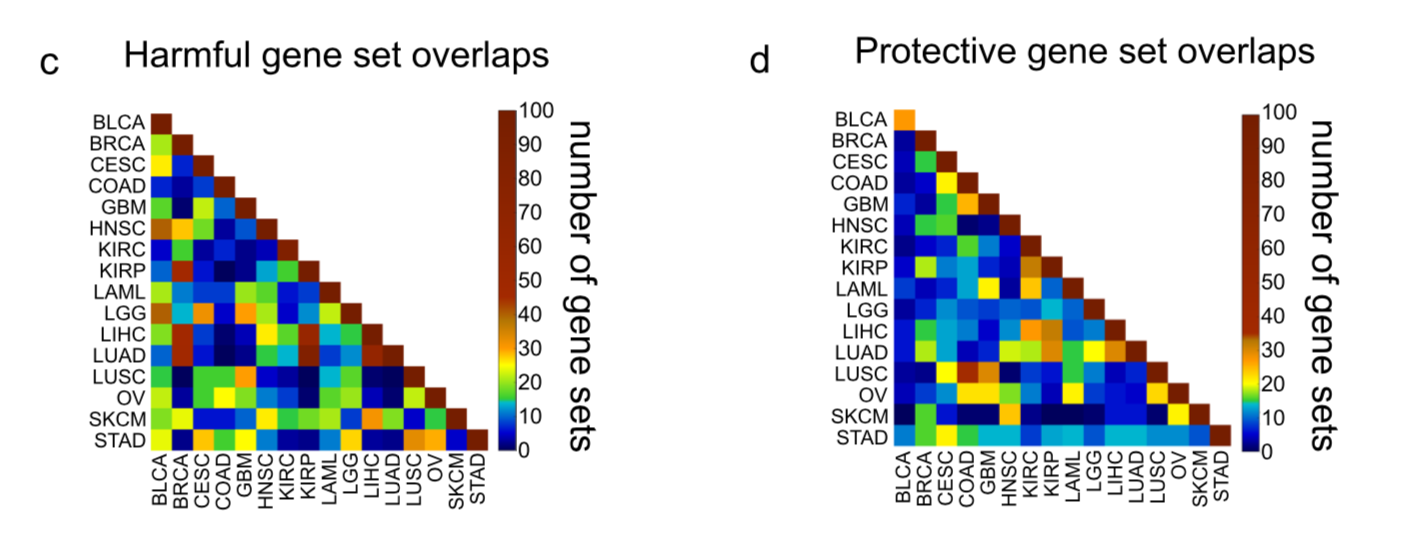
生存相关基因可以区分癌症
选取至少在4个癌症里面, 都是生存相关的基因来进行热图可视化如下:
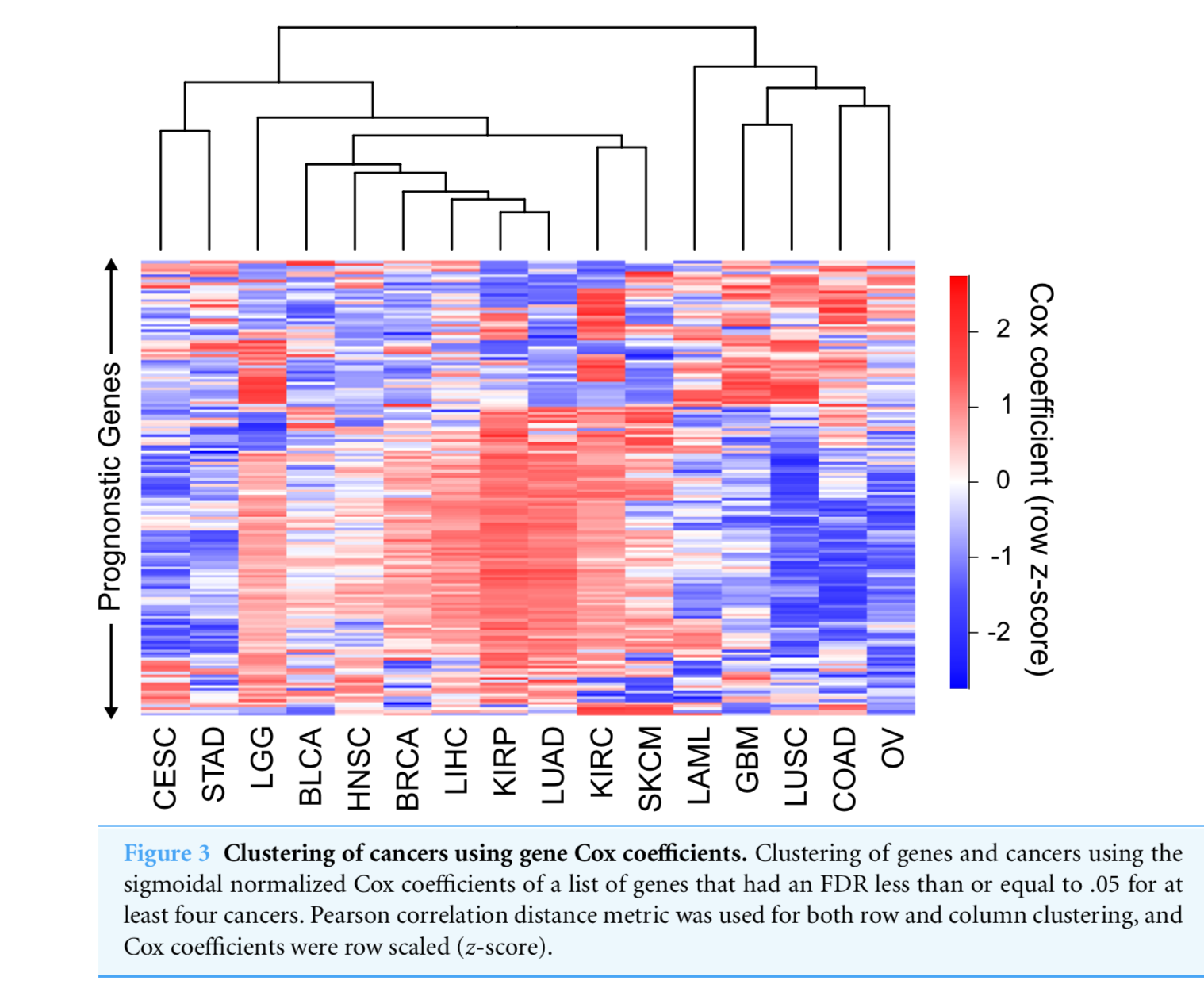
后记
可以说是非常简单了,同样的思路可以换很多其它指标,进行差不多的分析,只要是能自圆其说,可以用英文写出来,都是可以发表的!
本文献解读属于100篇泛癌研究文献系列,首发于:http://www.bio-info-trainee.com/4132.html