两年前我们介绍的用米氏方程解决单细胞转录组dropout现象的文章提出的那个算法,被包装到了R包,是:M3Drop ,文章最开始 2017年发表在biorxiv的是:Modelling dropouts for feature selection in scRNASeq experiments 后来(2019)published in Bioinformatics doi: 10.1093/bioinformatics/bty1044 ,而且整个包的使用方法发生了变化,值得记录和分享一下。
首先回顾一下单细胞流程
单细胞R包如过江之卿,入门的话我推荐大家学习5个R包,分别是: scater,monocle,Seurat,scran,M3Drop 需要熟练掌握它们的对象,:一些单细胞转录组R包的对象 而且分析流程也大同小异:
- step1: 创建对象
- step2: 质量控制
- step3: 表达量的标准化和归一化
- step4: 去除干扰因素(多个样本整合)
- step5: 判断重要的基因
- step6: 多种降维算法
- step7: 可视化降维结果
- step8: 多种聚类算法
- step9: 聚类后找每个细胞亚群的标志基因
- step10: 继续分类
其中一个步骤是判断重要的基因,我分享过:比较5种scRNA鉴定HVGs方法 里面就提到了 M3Drop::BrenneckeGetVariableGenes 函数,但是如果大家看到的是我早期教程,会发现很多函数用不了了。有必要更新一下教程。
认识测试数据
library(M3Drop)
library(M3DExampleData)
counts <- Mmus_example_list$data
labels <- Mmus_example_list$labels
total_features <- colSums(counts >= 0)
counts <- counts[,total_features >= 2000]
labels <- labels[total_features >= 2000]
是5个分组,133个细胞
> table(labels)
labels
early2cell earlyblast late2cell mid2cell midblast
8 43 10 12 60
> dim(counts)
[1] 17706 133
首先,它提供3种判断重要的基因的方法
norm <- M3DropConvertData(counts, is.counts=TRUE)
# norm <- M3DropConvertData(log2(norm+1), is.log=TRUE, pseudocount=1)
###################################################
M3Drop_genes <- M3DropFeatureSelection(norm, mt_method="fdr", mt_threshold=0.01)
count_mat <- NBumiConvertData(Mmus_example_list$data, is.counts=TRUE)
DANB_fit <- NBumiFitModel(count_mat)
NBDropFS <- NBumiFeatureSelectionCombinedDrop(DANB_fit, method="fdr", qval.thres=0.01, suppress.plot=FALSE)
HVG <- BrenneckeGetVariableGenes(norm)
require(UpSetR)
input <- fromList(list(M3Drop_genes=M3Drop_genes$Gene, NBDropFS=NBDropFS$Gene,
HVG=HVG$Gene ))
upset(input)
可以看到3种方法的一致性还可以
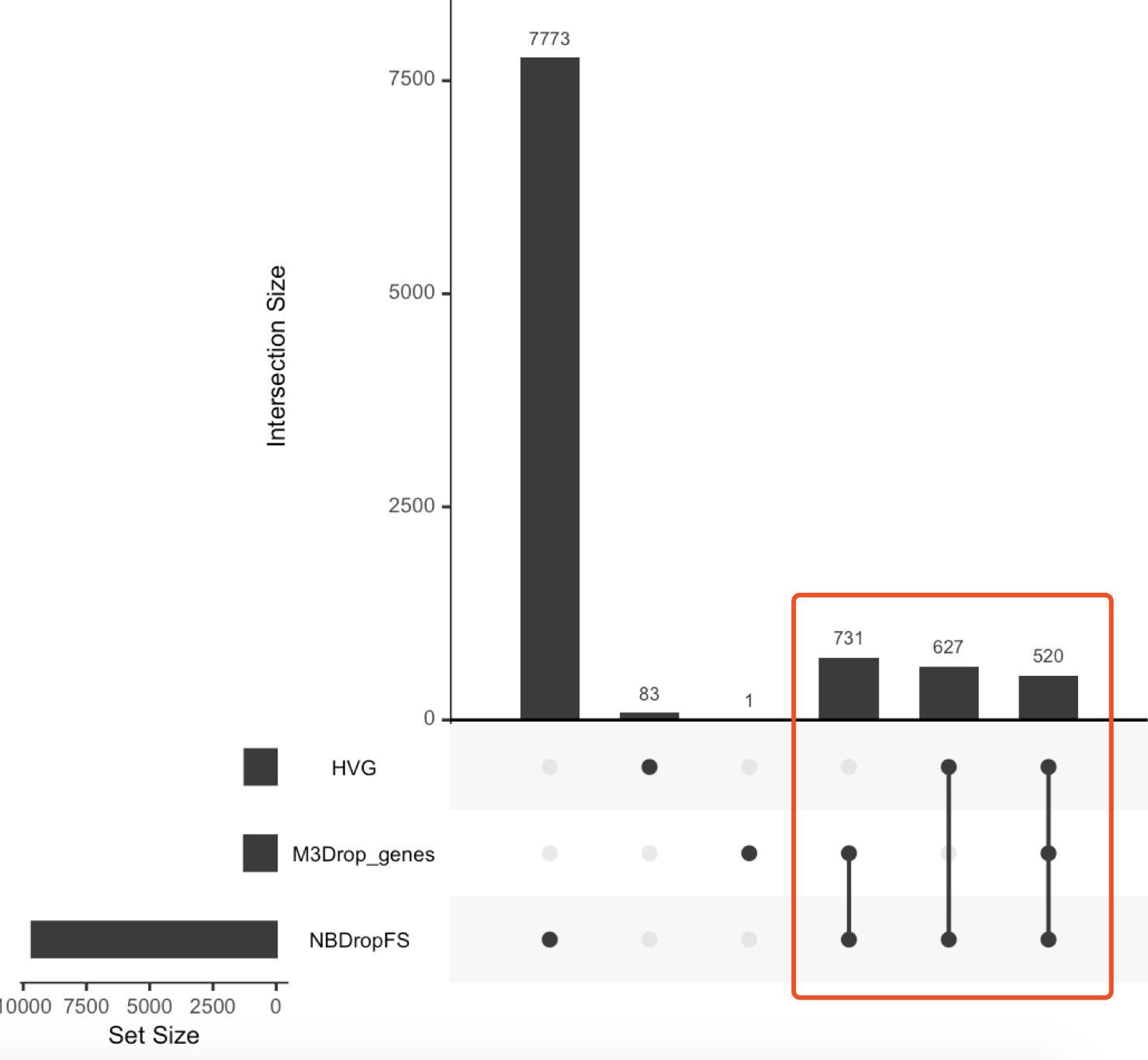
肯定是不能选择NBDropFS这个结果啦,就是来源于NBumiFeatureSelectionCombinedDrop 函数,因为基因实在是太多了,而且跟另外两个方法冲突的比较多 。
分组,找差异,可视化marker基因
标准的3个衔接起来的函数:M3DropExpressionHeatmap, M3DropGetHeatmapClusters, M3DropGetMarkers
heat_out <- M3DropExpressionHeatmap(M3Drop_genes$Gene, norm,
cell_labels = labels)
cell_populations <- M3DropGetHeatmapClusters(heat_out, k=4, type="cell")
library("ROCR")
marker_genes <- M3DropGetMarkers(norm, cell_populations)
marker_genes$Gene=rownames(marker_genes)
library(dplyr)
top20 <- marker_genes %>% group_by(Group) %>% top_n(n = -20, wt = pval)
heat_out <- M3DropExpressionHeatmap(M3Drop_genes$Gene, norm,
cell_labels = cell_populations)
轻轻松松就把细胞分类了,而且可以可视化那些排名比较靠前的marker基因。
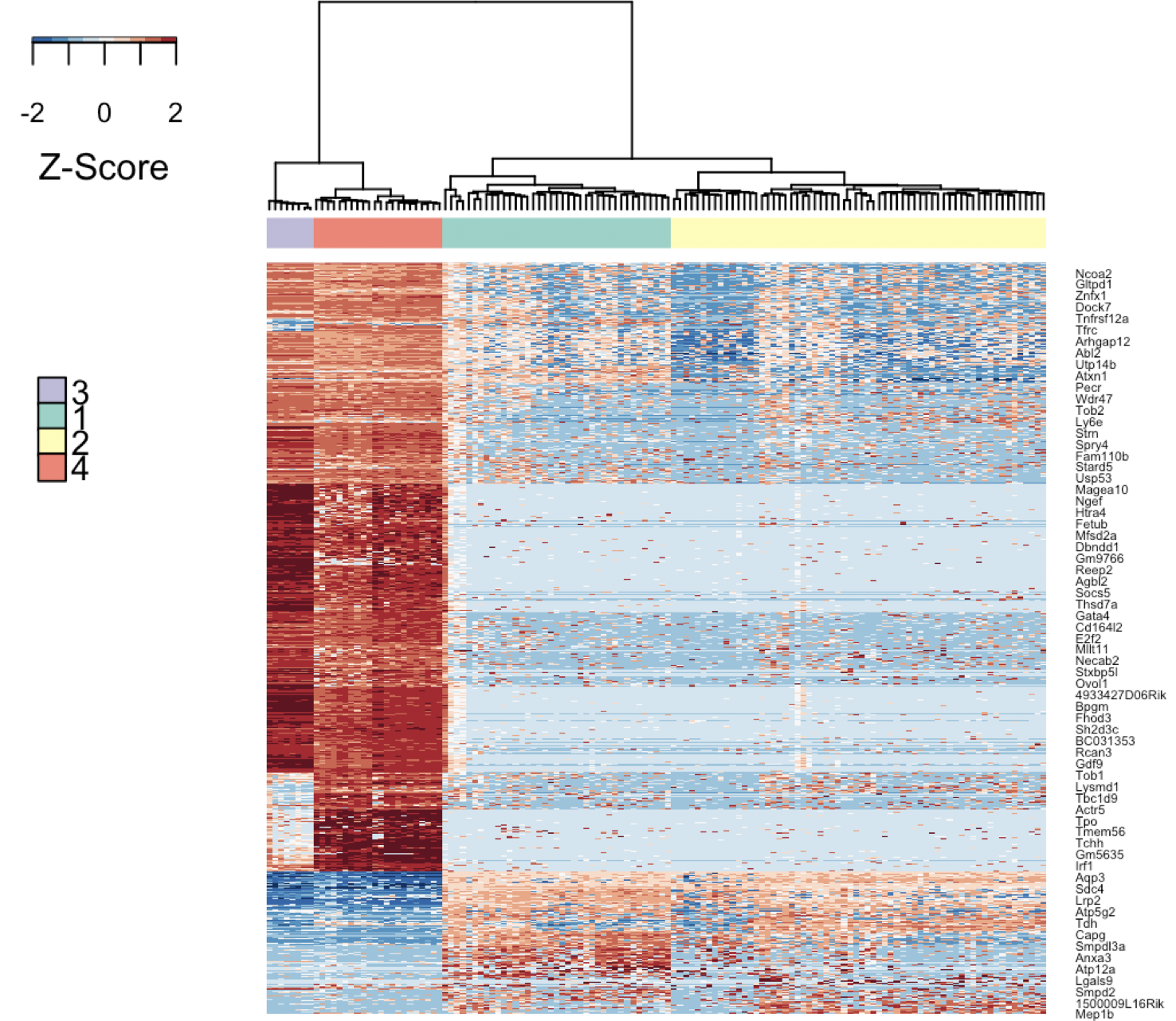
以前的用法
是 M3Drop流程,主要是分组及找差异的3个函数:
- M3DropCleanData,M3DropDropoutModels,M3DropDifferentialExpression
加上可视化的一些函数,代表是:
- M3DropExpressionHeatmap,M3DropGetHeatmapCellClusters,M3DropGetMarkers
library(M3Drop)
dim(counts);dim(meta)
Normalized_data <- M3DropCleanData(counts,
labels = meta,
is.counts=TRUE,
min_detected_genes=2000)
par(mar=c(1,1,1,1))
dev.new()
fits <- M3DropDropoutModels(Normalized_data$data)
DE_genes <- M3DropDifferentialExpression(Normalized_data$data,
mt_method="fdr", mt_threshold=0.01)
par(mar=c(1,1,1,1))
dev.new()
heat_out <- M3DropExpressionHeatmap(DE_genes$Gene, Normalized_data$data,
cell_labels = Normalized_data$labels$mouseID)
par(mar=c(1,1,1,1))
dev.new()
cell_populations <- M3DropGetHeatmapCellClusters(heat_out, k=i)
library("ROCR")
marker_genes <- M3DropGetMarkers(Normalized_data$data, cell_populations)
sigM = with(marker_genes,subset(marker_genes,AUC>0.7 & pval<0.05))
dim(counts)
dat=log2(edgeR::cpm(counts+1))