前面我们系统性的总结了circRNA的相关背景知识:
- 首先了解一下circRNA背景知识
- circRNA芯片分析的一般流程
- circRNA-seq分析的一般流程
- ceRNA-芯片分析的一般流程
同样的策略,我们也可以应用到其它领域的知识背景快速学习,比如我们的lncRNA系列,miRNA系列,现在我们一起学习一下甲基化吧。
我们已经强调过主要是DNA的甲基化,而且前面我们介绍了一些背景知识,主要是理解什么是DNA甲基化,为什么要检测它,以及芯片和测序两个方向的DNA甲基化检测技术。具体介绍在:甲基化的一些基础知识甲基化芯片的甲基化信号值概念
提到这些甲基化芯片背景知识,不得不强推中科院毕业的生信博士
joshua,目前在英国从事博士后研究,他是ChAMP这个分析(一站式)450K甲基化芯片数据的R包作者,我们生信技能树也多次推送过相关教程。比如850K甲基化芯片数据的分析
甲基化芯片主要是450K和850K,都是采用了两种探针Infinium Ⅰ 和Infinium Ⅱ对甲基化进行测定,Infinium I采用了两种bead(甲基化M和非甲基化U),而II只有一种bead(即甲基化和非甲基化在一起),这也导致了它们在后续荧光探测的不同,450K采用了两种荧光探测信号(红光和绿光)。数量分布如下: - 350,076 (70%) Both (M,U) Design II
- 46,298 (10%) Green (M,U) Design I
- 89,203 (20%) Red (M,U) Design I
illumina甲基化芯片计算
illumina的软件(Illumina GenomeStudio软件)自动就把450k芯片的
IDAT原始文件转换成了甲基化信号文件,一般是3~8列值每个样本。 通常是直接使用Illumina的Bead Studio软件和甲基化模块v3.2计算每个CpG靶标的β值。
β值=来自甲基化珠粒类型的强度值/(来自甲基化的强度值+来自未甲基化珠粒类型的强度值+ 100)。
然后使用p值对数据进行质量过滤。
p值大于0.01的β值被认为低于最小强度,阈值显示为“NA”。
有一个2010文章介绍了使用Beta value 和 M-value进行统计分析的利弊,大家可以参考一下。Comparison of Beta-value and M-value methods for quantifying methylation levels by microarray analysis
而minfi包有getM和getBeta来分别计算M-values和Beta-values,包的作者认为 - M-values具有更好的统计特性,更适合用于进行下游的统计分析(差异分析等);
- 而Beta-values更加容易解释,更能说明生物学上的意义
minfi包计算
minfi包的一个函数
read.450k.exp也可以直接读取.IDAT文件
公式计算: 平均β=信号B /(信号A +信号B + 100)
通过计算甲基化(信号A)和未甲基化(信号B)等位基因之间的强度比来确定DNA甲基化水平(β值)。
具体地,β值是由甲基化(M对应于信号A)和未甲基化(U对应于信号B)等位基因的强度计算的,荧光信号的比率β= Max(M,0)/ [Max( M,0)+ Max(U,0)+ 100]。
因此,β值的范围从0(完全未甲基化)到1(完全甲基化)
一般来说,具体的β值的意义是: - 任何等于或大于0.6的β值都被认为是完全甲基化的。
- 任何等于或小于0.2的β值被认为是完全未甲基化的。
- β值在0.2和0.6之间被认为是部分甲基化的。
甲基化芯片分析需要厂商提供注释文件信息
甲基化分析需要对应的注释文件,主流是EPIC和450K的,我先分析450K的
Manifest,首先原有的Manifest包含了从BeadChip到最终的文件的对应号,但是有一部分信息应该要提前过滤掉:一部分是开头的Header,另一部分是结尾的Control Probe,可以直接从illumina官网下载到对应的450K注释文件,如果把Header,Control Probe和SNP全部删掉,450K数据的行数正好就是:485512。
这就是450K甲基化注释的所有Probe数量,每一个Probe对应一个CpG位点。不是说人体的全基因组上只有这些位点,而是说illumina公司决定只将这些位点设计到芯片中完成测序。设计的时候,参考了很多公共数据库:•Genomic Coordinates •UCSC RefGene Name •UCSC RefGene Accession •UCSC RefGene Group •UCSC CpG Islands Name •Relation to UCSC CpG Island (Island, Shore, Shelf) •Phantom •DMR •Enhancer •HMM Island •Regulatory Feature Name •Regulatory Feature Group而且位于基因组不同功能区域的甲基化探针信号值代表的生物学意义不一样,包括5’ UTR, first exon, gene body, 3’ UTR, CpG island, CpG shore, CpG shelf,这些注释,都是在厂商提供注释文件信息里面。
如何确定基因的启动子区域甲基化水平
450K和850K芯片的甲基化探针数量庞大,而我们人类的蛋白编码基因也就两万个,所以每个基因评价可以有几十个探针,而我们比较关心的是该基因的启动子区域的甲基化探针的信号值水平。面临两个问题:
- 首先是定义一个基因的启动子
- 然后是确定该基因 的启动子区域的多个甲基化探针信号值的统计学指标。
Using themedianof the methylation values of the CpG probes mapped atpromoter regions(e.g., 1500 nucleotides from the transcription start site TSS1500; 200 nucleotides from the transcription start site TSS200; 5’UTR; and 1st exon), a single methylation value was consolidated for each gene promoter represented in the HM450K platform.
参考文章:https://link.springer.com/article/10.1186/s41241-017-0041-9甲基化芯片信号矩阵也直接使用GEOquery包下载
关于GEOquery在GEO公共数据库挖掘的重要性我已经多次强调和介绍了,不赘述,不过它可不只是用来下载表达芯片矩阵的,也可以下载甲基化芯片信号矩阵,也就是贝塔值矩阵。
代码如下:require(GEOquery) require(Biobase) GSE80559 <- getGEO("GSE80559") beta.m <- exprs(GSE80559[[1]])值得一提的是,甲基化信号矩阵有成熟的R包来区分细胞类型。
比如8种血液细胞的亚型 (B-cells, CD4+ T-cells, CD8+ T-cells, NK-cells, Monocytes, Neutrophils, Eosinophils, and Granulocytes. 你也可以看看单细胞水平的甲基化信号值,是否可以根据传统bulk的细胞marker来进行区分。
R包是:EpiDISH甲基化芯片数据分析的一般流程
大部分情况下的甲基化芯片数据分析,与mRNA表达芯片拿到的表达矩阵下游分析并没有本质区别。甲基化芯片数据分析的输入是每个探针在每个样本的甲基化信号值矩阵,而mRNA表达芯片拿到的表达矩阵是每个探针代表的基因在每个样本的表达量矩阵。
与mRNA表达芯片拿到的表达矩阵分析思路一致的地方
如果从workflow来看,主要是:
- 甲基化数据
下载,主要是GEO和TCGA数据库 - 数据整理,探针去除,重点在于质量控制
差异甲基化,3个层次的差异- 热图,火山图,主成分分析图
- 功能基因集
注释分析 - 批量位点甲基化和表达
相关性分析 - 批量生存分析
你会发现,拿到甲基化信号值矩阵后,仍然是可以走标准分析流程,火山图,热图,GO/KEGG数据库注释等等。这些流程的视频教程都在B站和GitHub了,目录如下: - 第一讲:GEO,表达芯片与R
- 第二讲:从GEO下载数据得到表达量矩阵
- 第三讲:对表达量矩阵用GSEA软件做分析
- 第四讲:根据分组信息做差异分析
- 第五讲:对差异基因结果做GO/KEGG超几何分布检验富集分析
- 第六讲:指定基因分组boxplot指定基因list画热图
感兴趣可以细读表达芯片的公共数据库挖掘系列推文 ; - 解读GEO数据存放规律及下载,一文就够
- 解读SRA数据库规律一文就够
- 从GEO数据库下载得到表达矩阵 一文就够
- GSEA分析一文就够(单机版+R语言版)
- 根据分组信息做差异分析- 这个一文不够的
- 差异分析得到的结果注释一文就够
所以实际上,还是看大家的R语言水平啦,以及大家的文献阅读功底啦。
比如表达矩阵可以进行分子分型,那么甲基化信号值矩阵也是如此。 - 发表于:Breast Cancer Res. 2016; 通过对188个乳腺癌患者样本的450K甲基化芯片,无监督聚类可以分成7组,而且还跟TCGA计划的数据做了比较,而且是多组学层面的比较。
- 发表于December 2014, CCR 通过对124个肺癌患者样本的450K甲基化芯片数据处理,Unsupervised analysis identified five DNA methylation subgroups (epitypes).
- 其它癌症相关研究大家可以自行搜索。
比如表达量可以把病人分组做生存分析,那么甲基化信号值也是一样。这个属于TCGA数据挖掘系列文章了,大家搜索关键词, TCGA methylation signature ,会发现大量2019年附近的文章,具体原因我这里不方便细说。 - CpG methylation signature predicts prognosis in breast cancer.
- Five-CpG-based prognostic signature for predicting survival in …
- DNA methylation markers for diagnosis and prognosis of …
- Pan-Cancer Landscape of Aberrant DNA Methylation across …31542-0.pdf)
- Characterization of a prognostic four‑gene methylation …
- A DNA methylation signature to improve survival prediction of …
- A seven‐DNA methylation signature as a novel prognostic …
- Prognostic and Predictive Value of Three DNA Methylation …
比如基因型可以进行gwas研究,那么甲基化信号也可以。For example, a genome-wide DNA methylation association study in obesity that recruited 5,387 individuals, identified 278 CpGs associated with BMI (Wahl et al., 2017).甲基化芯片的甲基化信号值特有分析方法
大部分数据分析方法都是借鉴成熟的mRNA表达芯片的表达矩阵来的,并无特殊之处,需要注意的仅仅是数据质控部分,以及后续的基于甲基化这个特性的分析。
甲基化数据质控、归一化
这个步骤主要是靠多练习,数据集见得多了,就会有自己的判断力。当然了,bioconductor的几个集成好的workflow里面都是着重强调了甲基化数据质控、归一化。尤其是要多花一点时间在上面。
差异甲基化区域鉴定及可视化
甲基化信号值矩阵有3个层次的差异分析:DMP,DMR,DMB:
- DMP代表找出Differential Methylation Probe(差异化CpG位点)
- DMR代表找出Differential Methylation Region(差异化CpG区域)
- Block代表Differential Methylation Block(更大范围的差异化region区域)
简单来说,DMP是找出一个一个的差异甲基化CpG位点,DMR就是一个连续不断都比较长的差异片段,科学家们觉得,这样的连续差异片段,对于基因的影响会更加明显,只找这样的片段,可以使得计算生物学的打击精度更为准确,也可以让最终找出来的结论数据更少,便于实验人员筛选。另外一个类似的东西就是DMB,那个东西出现的原因是,有的科学家觉得,DMR这样的区域还不够显著,DNA上的甲基化出现变化,可能是绵延几千位点的!而且只会在基因以外的区域,但是这些基因以外的区域发生变化,却会导致基因的表达发生变化。你可以想象成,北京周边的河北在大炼钢铁,然后北京也跟着雾霾了,大概就是这意思。差异甲基化位点的基因功能区域分类
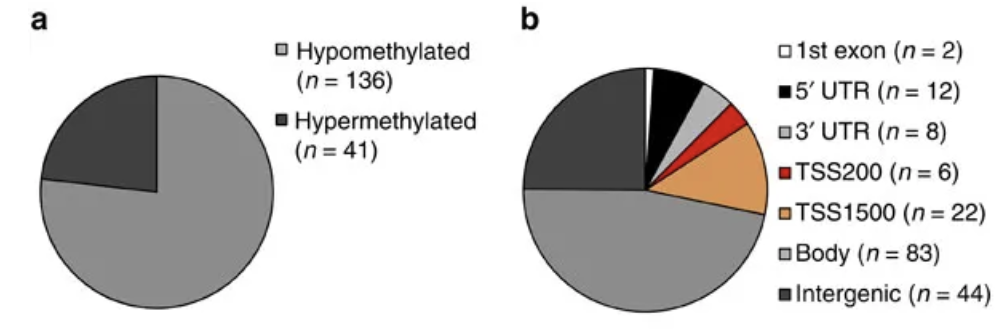
前面我们提到了位于基因组不同功能区域的甲基化探针信号值代表的生物学意义不一样,包括5’ UTR, first exon, gene body, 3’ UTR, CpG island, CpG shore, CpG shelf,这些注释,都是在厂商提供注释文件信息里面。所以差异分析拿到的高甲基化或者低甲基化位点就可以分类,比如文章: Epigenetic regulation of diacylglycerol kinase alpha promotes radiation-induced fibrosis:
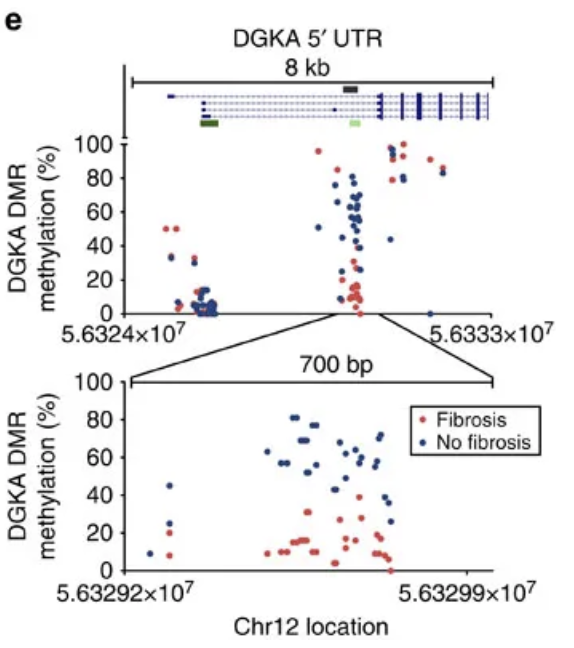
还可以更细致的展示某个基因附近的全部甲基化探针,如下:(e) Detailed interrogation of DNA methylation using EpiTYPER in two distinct patient fibroblasts (fibrosis and fibrosis-free) at the DGKA 5′ UTR (upper panel) and the differentially methylated region (lower panel).
成型的甲基化芯片数据分析流程
其实我们生信技能树前面的多个教程也系统性介绍过,比如850K甲基化芯片数据的分析 ,还有Bioconductor的DNA甲基化芯片分析流程
可以很清楚的看到,也是以差异分析为主: - 2 Differential methylation analysis
- 3 Additional analyses
- 3.1 Gene ontology testing
- 3.2 Differential variability
- 3.3 Cell type composition
辅助一下甲基化特有的分析即可。甲基化芯片数据分析示例
你可以下载GSE58651数据集,然后看看能不能重复出来同样的差异分析结果,并且绘制文章 里面的差异甲基化信号值位点热图:
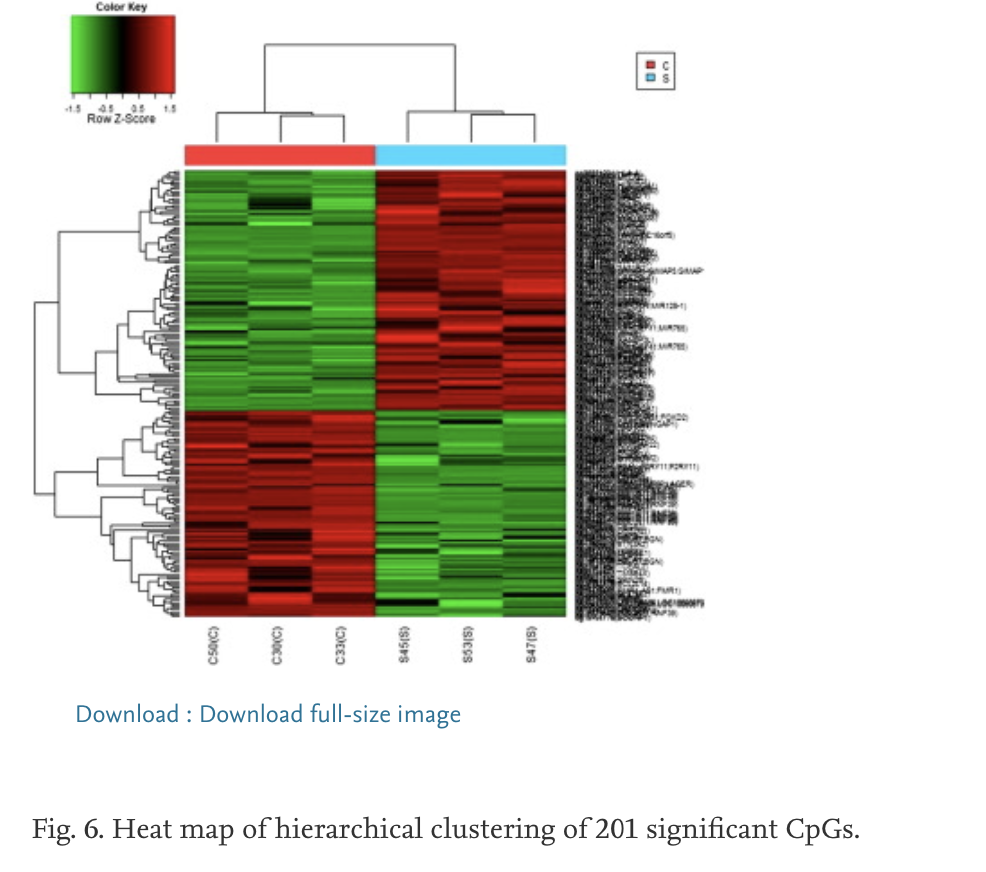
Screening of the 201 significant CpGs for gender-specific probes, SNP probes, repeats and unidentified locations, resulted in 81 CpGs (54 hypermethylated and 27 hypomethylated) located in 64 genes.
再比如发表在 January 25, 2018 的文章,Identification of methylated genes and miRNA signatures in nasopharyngeal carcinoma by bioinformatics analysis ,集中在两个 (GSE52068 and GSE62336) 甲基化数据差异分析结果的overlap上面。也是值得大家借鉴!
另外一个简单数据挖掘例子,是GSE62336,文章在:https://www.spandidos-publications.com/10.3892/ol.2017.7083甲基化芯片通常和mRNA表达芯片联合起来
大部分人感兴趣的是数据挖掘,通常我们说甲基化芯片数据挖掘,不仅仅是前面提到的单一数据的分析,往往是会把它跟mRNA表达芯片联合起来。因为它们可以有共同的基因做桥梁,甲基化探针设计在基因的不同功能区域,包括启动子,外显子,内含子,mRNA表达芯片探针通常是设计在基因的转录本上面。
比如发表在Front. Genet., 19 December 2018 | https://doi.org/10.3389/fgene.2018.00663 的文章,题目(很长):Using Integrative Analysis of DNA Methylation and Gene Expression Data in Multiple Tissue Types to Prioritize Candidate Genes for Drug Development in Obesit ,主要是关于Visceral adipose tissue (VAT) and subcutaneous adipose tissue (SAT)的分析。
- 两个mRNA表达芯片联数据集:GSE2508 (10 obese vs. 10 lean) and GSE88837 (15 obese vs. 15 lean) for the SAT and VAT
- 两个甲基化芯片数据集:GSE88940 (10 obese vs. 10 normal VAT samples) and GSE65057 (8 obese vs. 7 normal liver samples)
发表在 September 27, 2017 文章 https://www.spandidos-publications.com/ol/14/6/7171 题目是Identification of potentially critical differentially methylated genes in nasopharyngeal carcinoma: A comprehensive analysis of methylation profiling and gene expression profiling - 两个 (GSE52068 and GSE62336) 甲基化数据,得到1,676 hypermethylated genes, 28 hypomethylated genes, 17 DMIs
- 3个表达芯片:(GSE53819, GSE13597 and GSE12452) 得到上下调基因:2,983 DEGs (1,655 upregulated and 1,328 downregulated)
发表在 September 2019 :European Archives of Oto-Rhino-Laryngology 的 文章 ,Comprehensive analysis of gene expression and DNA methylation for human nasopharyngeal carcinoma 也做了挖掘:https://link.springer.com/article/10.1007/s00405-019-05525-2 - 2个甲基化芯片 (GSE52068 and GSE62336) 数据:综合得到 719 DMCs including 1 hypermethylated sites and 718 hypomethylated sites
- 5个表达芯片数据:GSE64634, GSE40290, GSE53819, GSE13597 and GSE12452 ,综合得到上下调基因;1074 genes were up-regulated and 939 genes were down-regulated.
实际上,这个时候你应该是意识到,之所以联合甲基化芯片和mRNA表达芯片,就是因为它们可以通过基因这个桥梁,所以理论上mRNA-seq当然也可以跟甲基化芯片或者测序联合起来分析的啦!发表在BMC Systems Biology December 2011的文章 An integrative analysis of DNA methylation and RNA-Seq data for human heart, kidney and liver 就是这样的一个例子。其它小众甲基化芯片
Agilent 的SurePrint甲基化芯片:
- 1、 Agilent Human CpG Island Microaray 1x244K 覆盖27,800个人类CpG岛
- 2、Agilent Human DNA Methylation Microarray 1x244K覆盖27,627个人类CpG岛和5081个UMR区域
- 3、Agilent Mouse CpG Island Microarray, 2x105K 覆盖16,030个小鼠CpG岛
Roche 的 NimbleGen甲基化芯片 - 1、Roche-NimbleGen CpG promoter芯片
- 2、Roche-NimbleGen启动子芯片
- 3、Roche-NimbleGen全基因组Tiling芯片
- 4、microRNA DNA甲基化芯片
感兴趣的朋友可以去GEO的GPL合辑里面搜索找一下,看看这些平台到底小众到什么程度。收费群(甲基化芯片数据处理交流)
最后微信公众号推出了一个好玩的产品,就是付费 推文,我们以前的群聊都是靠小助手一个个拉人加入,非常的辛苦,如下:
- lncRNA数据分析传送门
- 450K甲基化芯片数据处理传送门
- ChIP-seq基础入门传送门
- 转录组入门传送门
- ATAC-Seq入门加高阶传送门
- 蛋白质组学习小组起飞啦!
- TCGA数据库挖掘学习小组
所以,这次我们借用微信公众号的付费 推文模式,还是老规矩,18.8元进群,一个简单的门槛,隔绝那些营销号!
同时,我们也会在群里共享一些DNA甲基化相关资料,仅此而已,考虑清楚哦!
请点下面“阅读全部”获取群二维码▼