前面我们开始接数据分析业务了,比如 明码标价之普通转录组上游分析,马上就在《生信技能树》公众号后台接到了很多需求。
因为是小规模测试,所以我们接项目的时间和精力这段时间是很难满足全部的粉丝需求,不过我们会尽量做好每一单!其中一个学徒找我求助说不知道为什么他负责的那个小鼠的转录组测序数据比对率超级好,但是计量的时候非常诡异。让我们一起来看看比对率情况:
$grep 'overall alignment rate' *log.txt
log.hisat2.0.txt:96.29% overall alignment rate
log.hisat2.0.txt:96.18% overall alignment rate
log.hisat2.0.txt:96.33% overall alignment rate
log.hisat2.1.txt:96.42% overall alignment rate
log.hisat2.1.txt:95.59% overall alignment rate
log.hisat2.1.txt:96.31% overall alignment rate
log.hisat2.2.txt:96.50% overall alignment rate
log.hisat2.2.txt:96.25% overall alignment rate
log.hisat2.2.txt:96.08% overall alignment rate
可以看到比对率基本上都是95%上下,但是在计量的时候,如下所示:
$cat error/counts.id.log |grep 'Successfully assigned alignments'
|| Successfully assigned alignments : 4196373 (18.8%) ||
|| Successfully assigned alignments : 4415762 (18.9%) ||
|| Successfully assigned alignments : 4684891 (18.8%) ||
|| Successfully assigned alignments : 4255768 (18.3%) ||
|| Successfully assigned alignments : 4171532 (18.7%) ||
|| Successfully assigned alignments : 4232302 (17.2%) ||
|| Successfully assigned alignments : 4600880 (18.6%) ||
|| Successfully assigned alignments : 4309692 (18.3%) ||
|| Successfully assigned alignments : 4103653 (18.3%) ||
不到20%的成功率也确实是让人费解哦。学徒给了我一个怀疑的问题所在,就是 Per base sequence content ,如下所示:
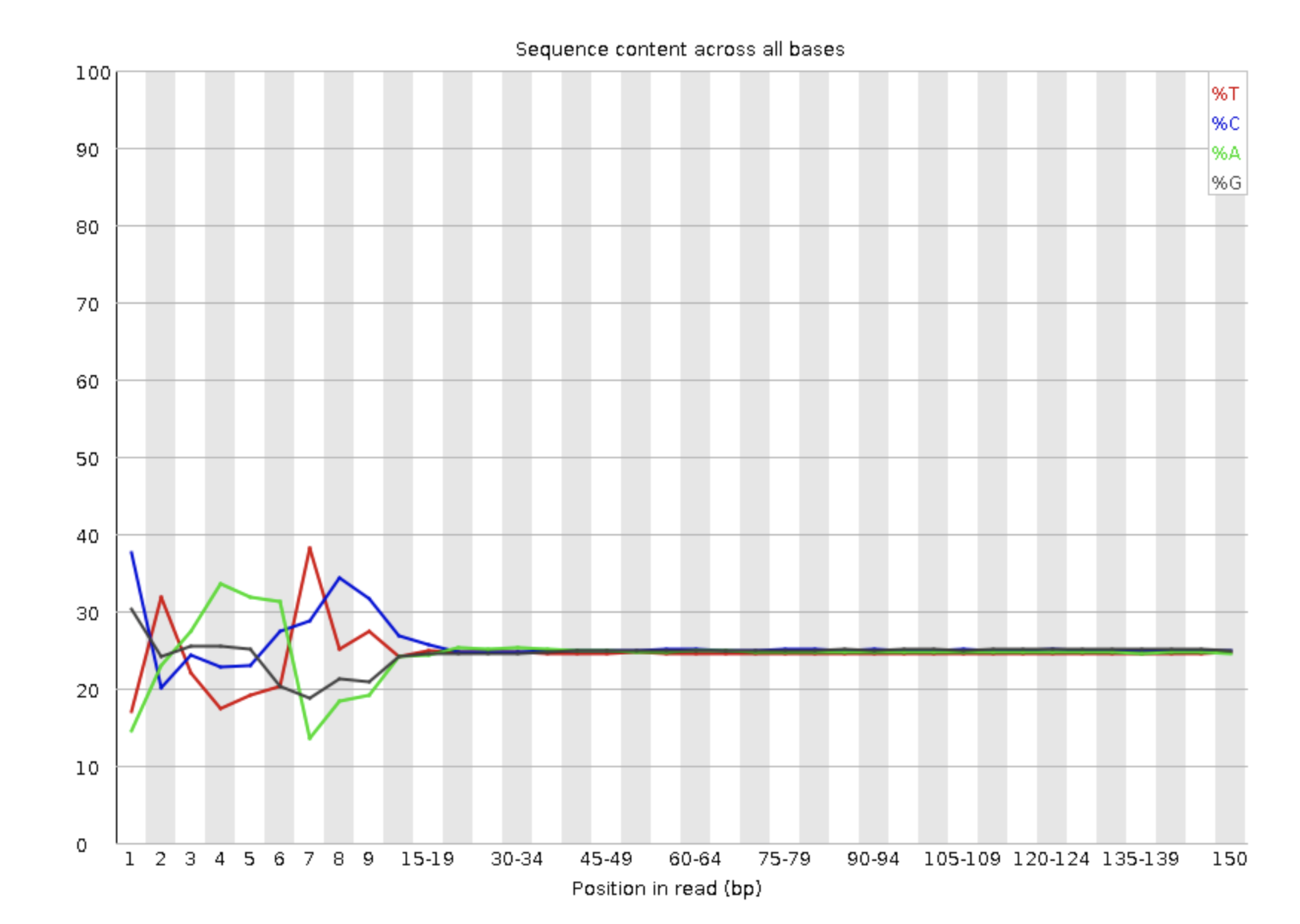
这个其实是因为学徒的知识储备还不够,不能理解为什么转录组测序数据的前面10多个碱基的GC含量不平衡问题。如果这个不平衡真的是问题所在,那么它影响的也应该是比对率而不是定量成功率。
我只好亲自出马去检查代码:
首先是比对,代码很复杂,但是重点就是 hisat2开头的那句话而已:
index=$HOME/reference/index/hisat/mm10/genome
ls -lh $index*
cat $config_file |while read id
do
echo $id
arr=($id)
fq1=${arr[1]}
fq2=${arr[2]}
sample=${arr[0]}
if((i%$number1==$number2))
then
if [ ! -f $sample.bam ]; then
start=$(date +%s.%N)
echo hisat2 `date`
hisat2 -p 4 -x $index -1 $fq1 -2 $fq2 | samtools sort -@ 4 -o $sample.bam -
echo hisat2 `date`
dur=$(echo "$(date +%s.%N) - $start" | bc)
printf "Execution time for hisat2 : %.6f seconds" $dur
fi ## end for if files
fi ## end for number1
i=$((i+1))
done ## end for $config_file
然后是定量:
# 走featureCounts定量流程
nohup featureCounts -T 5 -p -t exon -g gene_id -a gencode.vM26.annotation.gtf \
-o all.id.txt *.bam 1>counts.id.log 2>&1 &
看起来中规中矩,都是我教的,理论上没有问题。但实际上我还灌输了一个观点, 为了显示我们流程的先进性,务必使用最新版软件或者数据库文件。所以导致了问题,为了检查问题所在,我把另外一个项目的正常的定量日志跟这个有问题的日志一起检查,发现学徒这个定量哪怕是成功了,也是绝大部分情况下都是基因间隔区域啊。
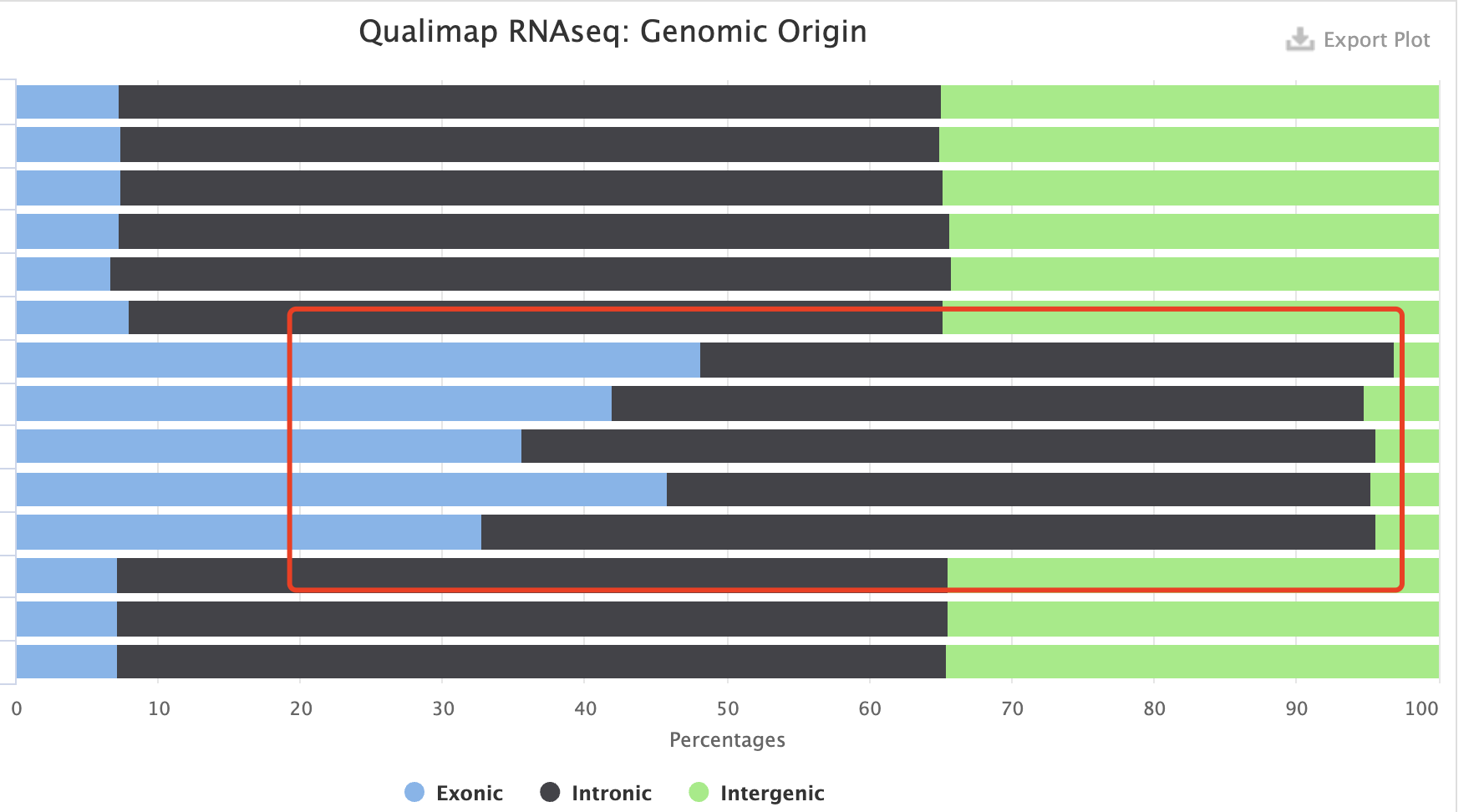
一般来说,这样的情况是因为数据库版本不匹配导致,尤其是参考基因组版本和gtf注释信息的版本,但是我明明是交待了学徒都是要最新的啊!
小鼠的gtf文件的更新
我去看了看更新日志:https://www.gencodegenes.org/mouse/releases.html 终于意识到了问题所在:
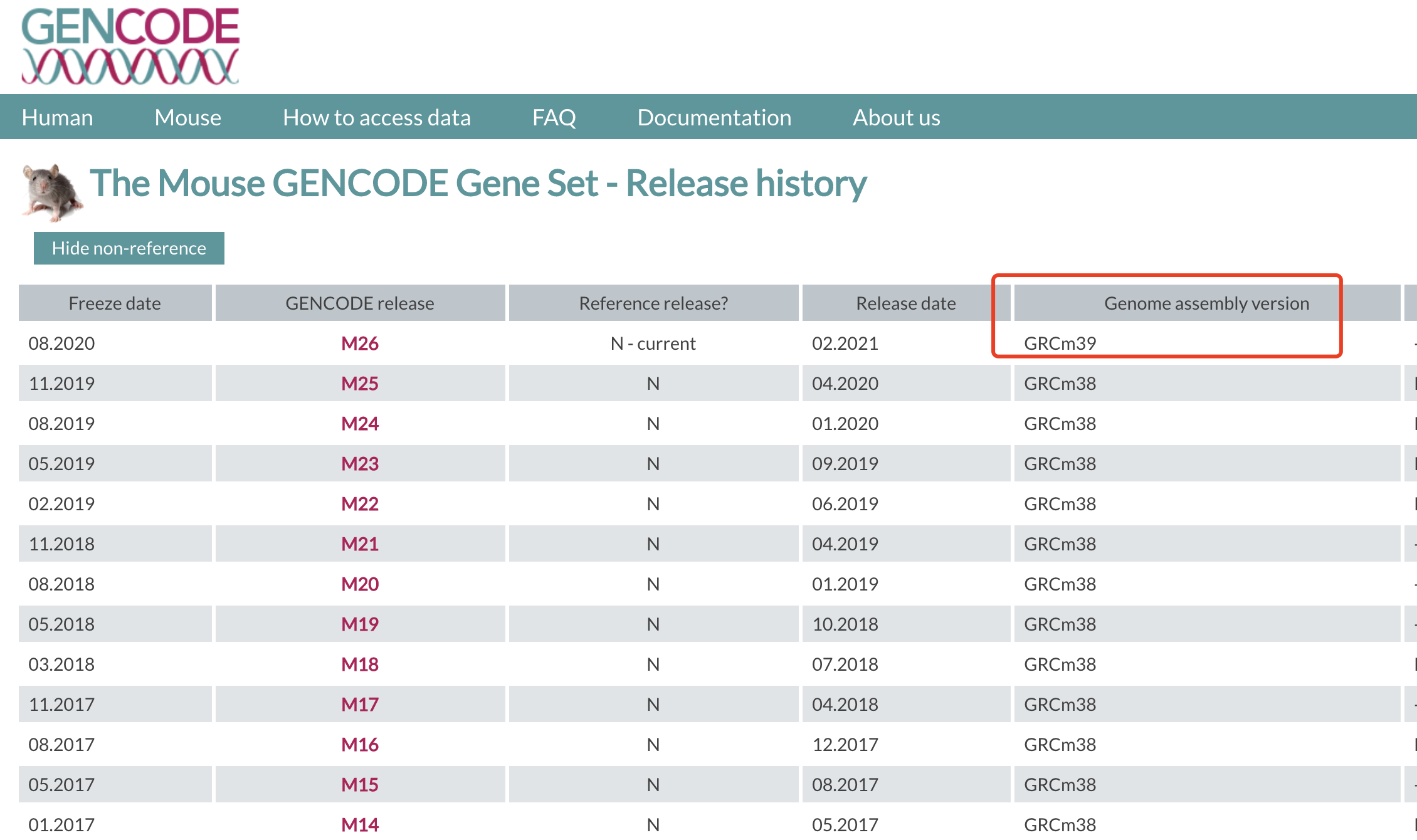
这个gtf文件对应的参考基因组版本是 GRCm39 ,就不再是 hisat/mm10/genome啦,因为 mm10对应的是 GRCm38 。
我目前还没有看到GRCm39的参考基因组hisat2的index文件,所以呢,就要求学徒把gtf降级一下。
问题就解决啦,可以看到全部的定量成功率都是由不到20%上升到了70%,棒棒哒!
$cat counts.id.log |grep 'Successfully assigned alignments'
|| Successfully assigned alignments : 15850312 (71.0%) ||
|| Successfully assigned alignments : 16738318 (71.6%) ||
|| Successfully assigned alignments : 17776727 (71.2%) ||
|| Successfully assigned alignments : 16481943 (70.9%) ||
|| Successfully assigned alignments : 15982860 (71.8%) ||
|| Successfully assigned alignments : 17039847 (69.2%) ||
|| Successfully assigned alignments : 17628370 (71.1%) ||
|| Successfully assigned alignments : 16725455 (71.2%) ||
|| Successfully assigned alignments : 15859338 (70.5%) ||
关于明码标价
有一个小伙伴解释的很好,我们是摆明了全部的代码,仍然是教学为主,只不过是对极少数非生物信息学专业方向的小伙伴来说,可能是时间精力不够或者说确实没有这个规划去学习咱们生物信息学,我们也希望可以标出价格给大家,避免大家上当受骗。
一个普通的 明码标价之普通转录组上游分析,就是800元,指定数据集,我们使用服务器去下载,去比对和定量,给出来矩阵供大家去下游分析,可以是热图或者差异分析更多。下游分析基本上可以参考表达芯片的公共数据库挖掘系列推文,感兴趣的也可以去看看;