前面我们假设自己的生物学背景不够,所以不需要把T细胞分成 “Naive CD4 T” , “Memory CD4 T” , “CD8 T”, “NK” 这些亚群,可以合并为T细胞这个大的亚群,也演示了代码情况。接下来我们看看,假如我们想更加细致的对部分细胞亚群进行重新降维聚类分群,并且探索它,该如何做。我们以 seurat 官方教程为例:
rm(list = ls())
library(Seurat)
# devtools::install_github('satijalab/seurat-data')
library(SeuratData)
library(ggplot2)
library(patchwork)
library(dplyr)
load(file = 'basic.sce.pbmc.Rdata')
DimPlot(pbmc, reduction = 'umap',
label = TRUE, pt.size = 0.5) + NoLegend()
sce=pbmc
如果你不知道 basic.sce.pbmc.Rdata 这个文件如何得到的,麻烦自己去跑一下 可视化单细胞亚群的标记基因的5个方法,自己 save(pbmc,file = ‘basic.sce.pbmc.Rdata’) ,我们后面的教程都是依赖于这个 文件哦!
首先定位到自己感兴趣的亚群
代码如下:
Idents(sce)
levels(sce)
head(sce@meta.data)
# 参考;https://mp.weixin.qq.com/s/9d4X3U38VuDvKmshF2OjHA
genes_to_check = c('PTPRC', 'CD3D', 'CD3E',
'CD4','IL7R','NKG7','CD8A')
DotPlot(sce, group.by = 'seurat_clusters',
features = unique(genes_to_check)) + RotatedAxis()
DotPlot(sce, # group.by = 'seurat_clusters',
features = unique(genes_to_check)) + RotatedAxis()
p1=DimPlot(sce, reduction = 'umap', group.by = 'seurat_clusters',
label = TRUE, pt.size = 0.5) + NoLegend()
p2=DotPlot(sce, group.by = 'seurat_clusters',
features = unique(genes_to_check)) + RotatedAxis()
library(patchwork)
p1+p2
如果这个时候,我们想提取CD4的T细胞,应该是选择 0 和2 这两个亚群:
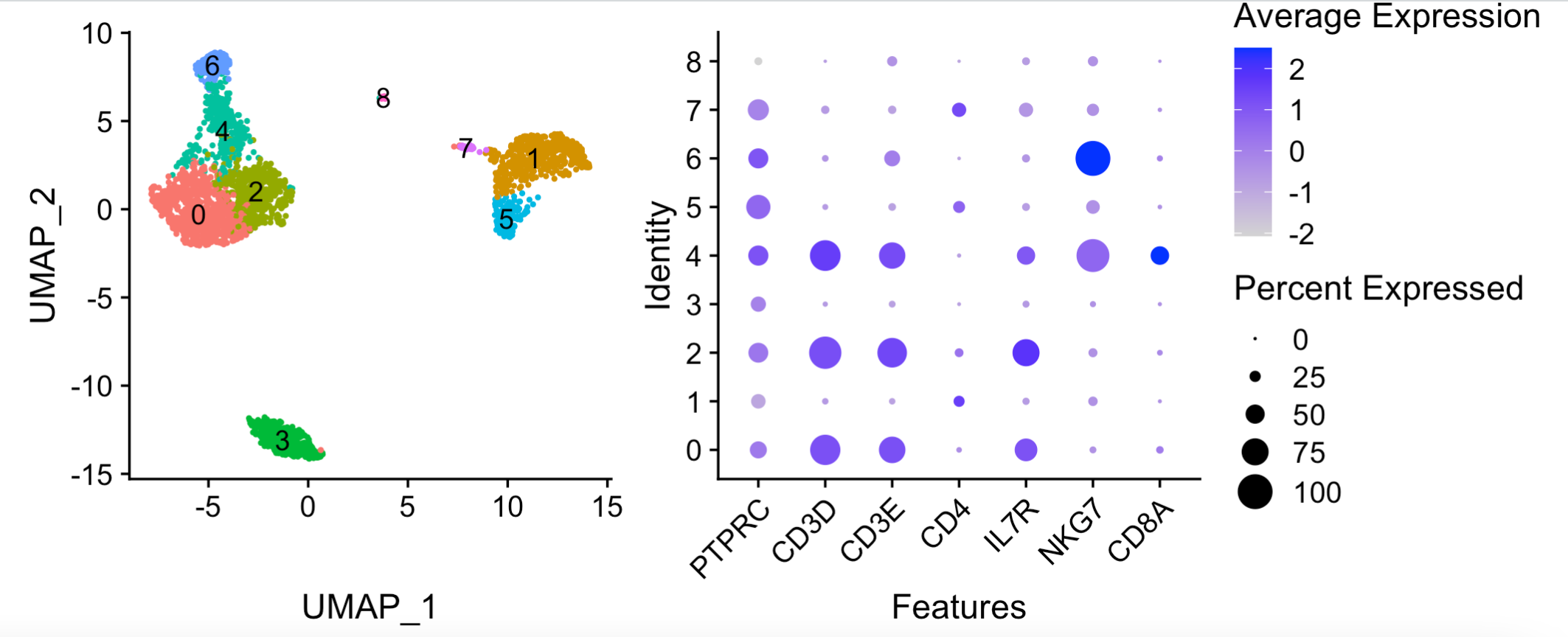
其实这个seurat官方示例里面的CD4的T细胞非常的诡异,因为它并不怎么高表达CD4这个基因。
提取指定单细胞亚群:
超级简单,代码如下:
cd4_sce1 = sce[,sce@meta.data$seurat_clusters %in% c(0,2)]
cd4_sce2 = sce[, Idents(sce) %in% c( "Naive CD4 T" , "Memory CD4 T" )]
# subset 函数也可以
你可以把seurat这样的对象,使用R 里面取子集的3种策略: 逻辑值,坐标,名字。
重新降维聚类分群
走标准代码即可:
sce=cd4_sce1
sce <- NormalizeData(sce, normalization.method = "LogNormalize", scale.factor = 1e4)
sce <- FindVariableFeatures(sce, selection.method = 'vst', nfeatures = 2000)
sce <- ScaleData(sce, vars.to.regress = "percent.mt")
sce <- RunPCA(sce, features = VariableFeatures(object = sce))
sce <- FindNeighbors(sce, dims = 1:10)
sce <- FindClusters(sce, resolution = 1 )
# Look at cluster IDs of the first 5 cells
head(Idents(sce), 5)
table(sce$seurat_clusters)
sce <- RunUMAP(sce, dims = 1:10)
DimPlot(sce, reduction = 'umap')
genes_to_check = c('PTPRC', 'CD3D', 'CD3E', 'FOXP3',
'CD4','IL7R','NKG7','CD8A')
DotPlot(sce, group.by = 'seurat_clusters',
features = unique(genes_to_check)) + RotatedAxis()
p1=DimPlot(sce, reduction = 'umap', group.by = 'seurat_clusters',
label = TRUE, pt.size = 0.5) + NoLegend()
p2=DotPlot(sce, group.by = 'seurat_clusters',
features = unique(genes_to_check)) + RotatedAxis()
library(patchwork)
p1+p2
save(sce,file = 'sce.cd4.subset.Rdata')
出图如下:
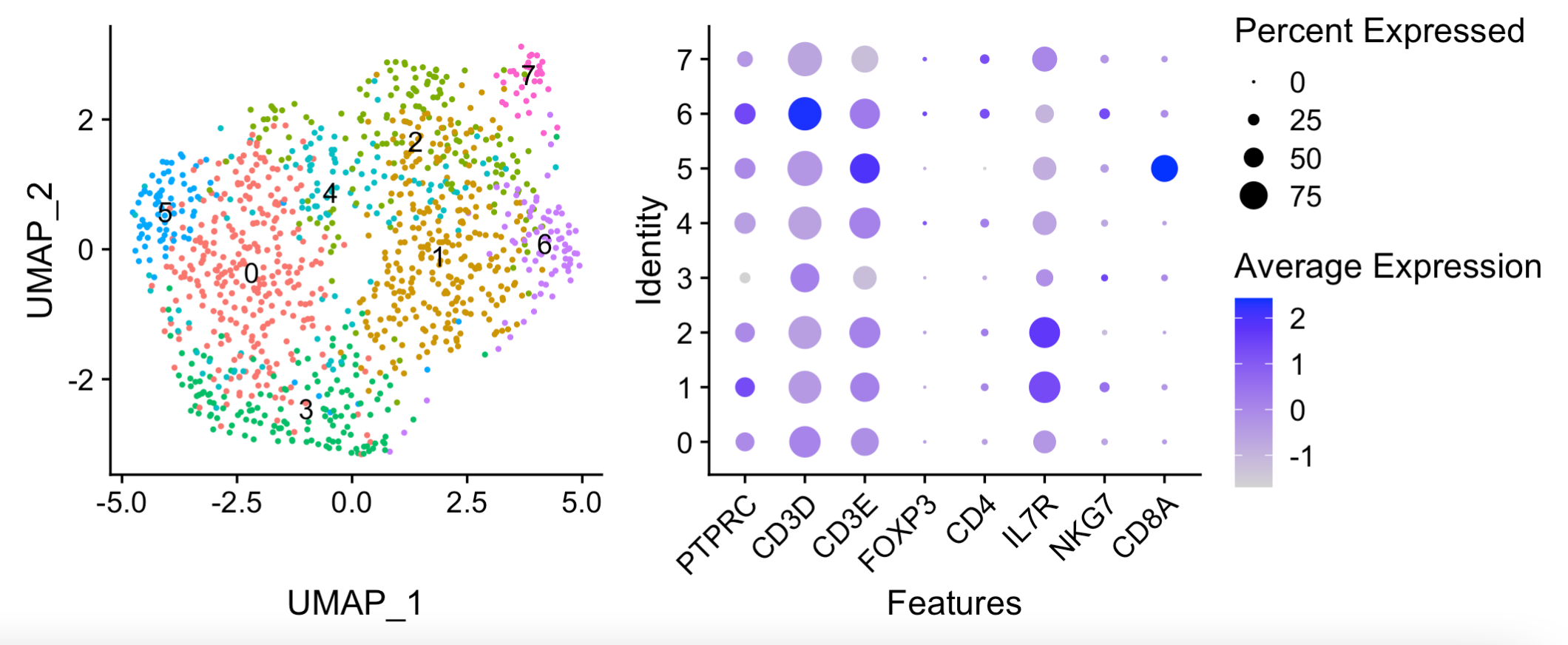
可以看到,这样的降维聚类分群已经是非常的勉强, 各个细胞亚群之间的界限并不是很清晰。有意思的是我们明明是排除了NK细胞和CD8 T细胞,但是仅仅是提取出来CD4的T细胞进行细分亚群,又多出来了一个CD8 T细胞亚群。