我们七月份的学徒培养专注于单细胞数据处理,第一个学徒选择的文章很有意思,标题是:《Single-cell transcriptomic heterogeneity in invasive ductal and lobular breast cancer cells》,这个单细胞文章仅仅是单个10X样品,但是测8个细胞系,Number of cells:
- MCF7 (n=977)
- T47D WT (n=509)
- T47D KO (n=491)
- MM134 (n=439)
- SUM44 (n=314)
- BCK4 (n=512)
- MCF10A (n=491)
- HEK293T(n=881).
可以看到,不同细胞系,降维聚类分群后,泾渭分明。但是没办法从单个或者多个标记基因的角度来对细胞系进行命名:
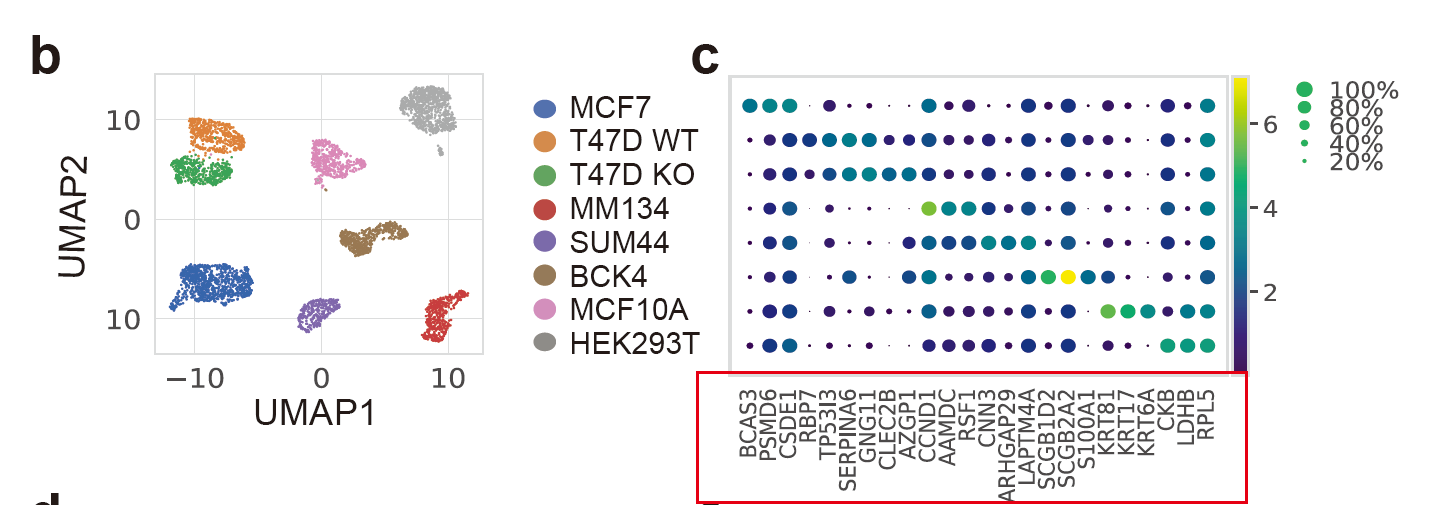
可以看到不同细胞系各自的高表达量基因并不是非常特异性,不同细胞系仅仅是某些基因的表达高低而不是表达与否的差异。
我给学徒的建议是根据文章里面的描述,去CCLE数据库,以及GEO数据库,找到里面的各种细胞系的芯片或者测序的表达量矩阵,然后对这个单细胞降维聚类分群后的8个细胞亚群取表达量平均值。把全部的细胞系和全部的单细胞亚群的表达相关性矩阵(Pearson correlation coefficient)热图可视化即可。
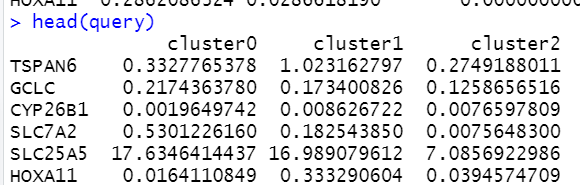
首先拿到细胞亚群基因表达量平均值
使用 AverageExpression 函数即可:
sce <- readRDS("../step1_聚类/sce_all.Rds")
query <- AverageExpression(sce, group.by = "RNA_snn_res.0.2",
features = rownames(reference) ,
slot = "data")
query <- as.data.frame(query[["RNA"]])
head(query)
如下所示 的矩阵,就是 细胞亚群基因表达量平均值 :
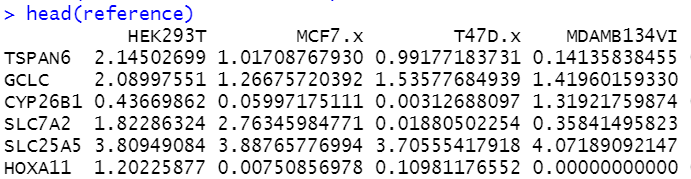
然后 拿到多个细胞系的表达量矩阵,这个 epxr_reference.csv 是自己去 去CCLE数据库,以及GEO数据库,找到里面的各种细胞系的芯片或者测序的表达量矩阵哦,其中的艰难险阻,省略五千字。
如下所示 :
reference <- read.csv("../6个参考数据集/epxr_reference.csv",
row.names = 1)
reference <- textshape::column_to_rownames(reference, loc =1)
head(reference)
colnames(reference)
sce_tmp <- CreateSeuratObject(counts = reference)
sce_tmp <- NormalizeData(sce_tmp)
reference <- as.data.frame(sce_tmp@assays[["RNA"]]@data)
细胞系表达量矩阵如下所示:
有了这两个数据集,就可以计算 相关性矩阵(Pearson correlation coefficient),代码如下 :
load(file = 'for_cor.Rdata')
head(reference)
head(query)
reference$X=rownames(reference)
query$X=rownames(query)
identical(query$X, reference$X)
data_merged <- dplyr::full_join(reference, query, by = "X")
head(data_merged)
data_merged <- textshape::column_to_rownames(data_merged, loc = 'X')
head(data_merged)
# step3.计算相关性
colnames(data_merged)
head(data_merged)
str(data_merged)
tmp=apply(data_merged, 2,as.numeric)
colnames(tmp)=colnames(data_merged)
rownames(tmp)=rownames(data_merged)
tt <- cor(tmp,
method = "pearson")
heatmap(tt)
tt1 <- tt[1:12,13:20]
tt2 <- tt1[sort(rownames(tt1)),]
pheatmap::pheatmap(tt2)
如下可视化 得到的 达相关性矩阵(Pearson correlation coefficient) :
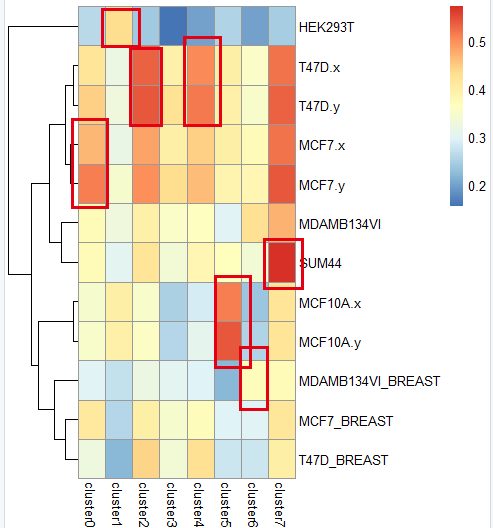
是不是很容易看到各个亚群各自最相关的细胞系啊,就可以进行命名了!
手动注释如下:
# st ep4. 手动注释细胞类型------
# cluster0 MCF7
# cluster1 HEK293
# cluster2 T47D
# cluster3 BCK4 # 排除法
# cluster4 T47D
# cluster5 MCF10A
# cluster6 MM134
# cluster7 SUM44
可以看到,cluster2和cluster4都是T47D细胞系,这个时候需要根据CDH1基因表达量进行进一步区分。另外,cluster3 对应的 BCK4 也是没办法命名,因为我们整理好的细胞系矩阵里面本来就没有它。

这个文献及其数据处理也会纳入我们的两个b站单细胞栏目,持续更新半年,基本上涵盖了大家需要的技能:
- https://www.bilibili.com/video/BV1DK4y1X7bb/ 更新至第8篇,「生信技能树」100个单细胞文献解读(8/100)
- https://www.bilibili.com/video/BV19Q4y1R7cu/ section 3已更新,「生信技能树」单细胞公开课2021
如果是简单的降维聚类分群,可以参考前面的例子:人人都能学会的单细胞聚类分群注释 ,我们演示了第一层次的分群。
如果你对单细胞数据分析还没有基础认知,可以看基础10讲: