今天这个推文甚至算不上一个教程,但是里面的代码其实是复制粘贴就可以运行哦。之所以写它,主要是是因为交流群有粉丝总是问各种各样的代码问题,风险因子森林图啊列线图的,归根到底就是R基础知识不牢固,所以报错连连。
抛开R代码知识不谈,我这里提出来一个有意思问题,有了风险因子森林图为什么还需要列线图?
认识自带数据
rm(list=ls())
options(stringsAsFactors = F)
library(survival)
colnames(cancer)
DT::datatable(cancer)
如下所示:
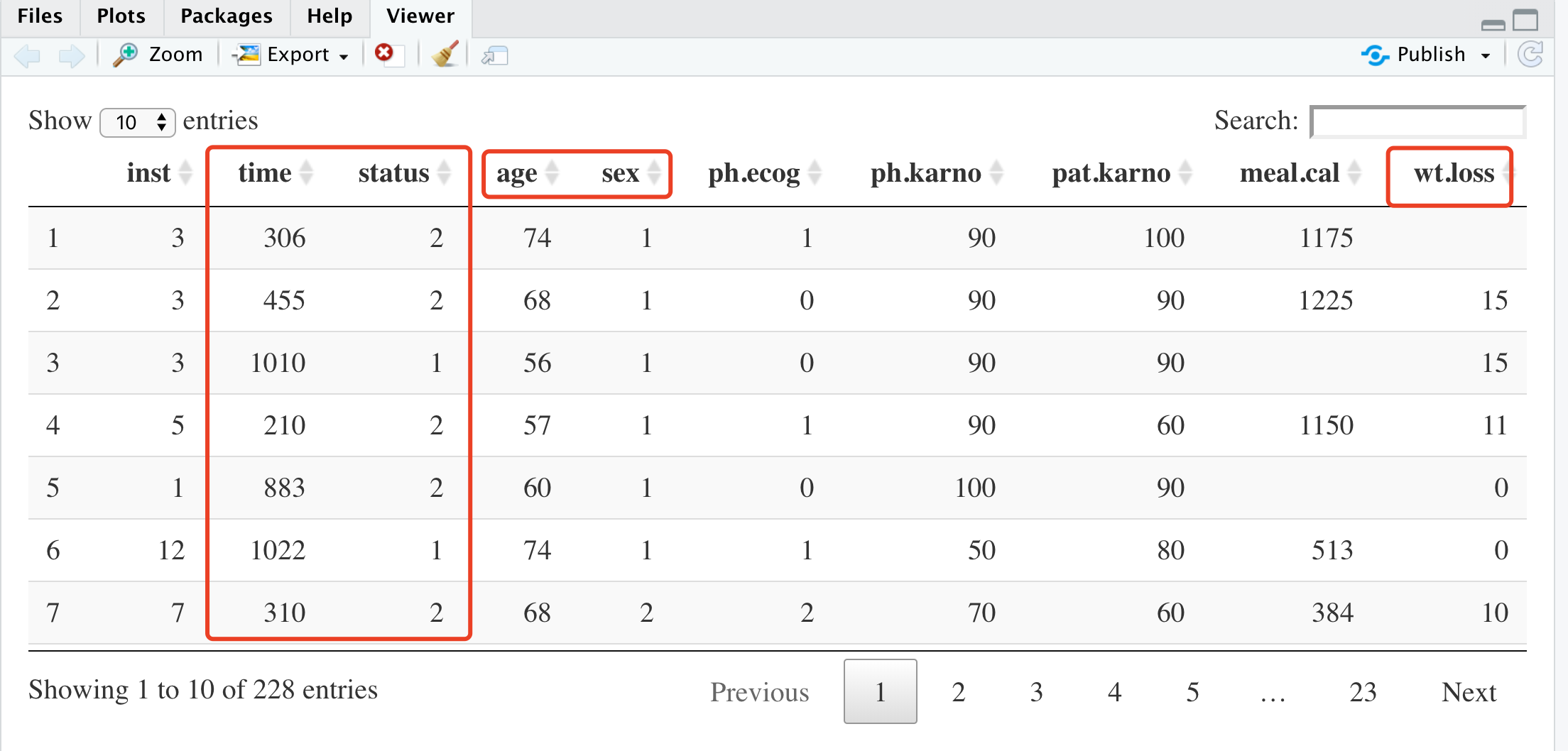
很明显,这个数据集包括了做生存相关分析的全部信息,尤其是每个病人的生存状态和随访时间。当然了,每个病人也有不少其它信息,比如 age + sex +ph.ecog + pat.karno +wt.loss ,这些信息都是有可能影响病人生存的。
就需要一系列统计学方法来判断,如果每个因素独立做KM生存分析会比较麻烦。log-rank检验是比较生存曲线是否有差异的最常用的方法,非参数检验。零假设是两组之间的生存率没有差异,log-rank统计量大致满足为卡方分布。
所以就有了coxph生存分析,一次性搞定多个因素。用于描述不同变量对于生存的影响;该方法不对“生存模型”做出假设,假设变量对生存的影响随时间变化是恒定的,并且在一个尺度中具有累加效应,因此不是真正的非参数,为半参数;生存曲线可视化无交叉表示满足PH设定;
首先看风险因子森林图
coxph(Cox proportional hazards)在R里面的代码实现起来非常容易,如下所示:
model <- coxph(Surv(time, status) ~ age + sex +ph.ecog + pat.karno +wt.loss,
data = cancer )
options(scipen=1)
ggforest(model, data = cancer,
main = "Hazard ratio",
cpositions = c(0.10, 0.22, 0.4),
fontsize = 1.0,
refLabel = "1", noDigits = 4)
还可以顺便绘制一个风险因子森林图,可以看到:
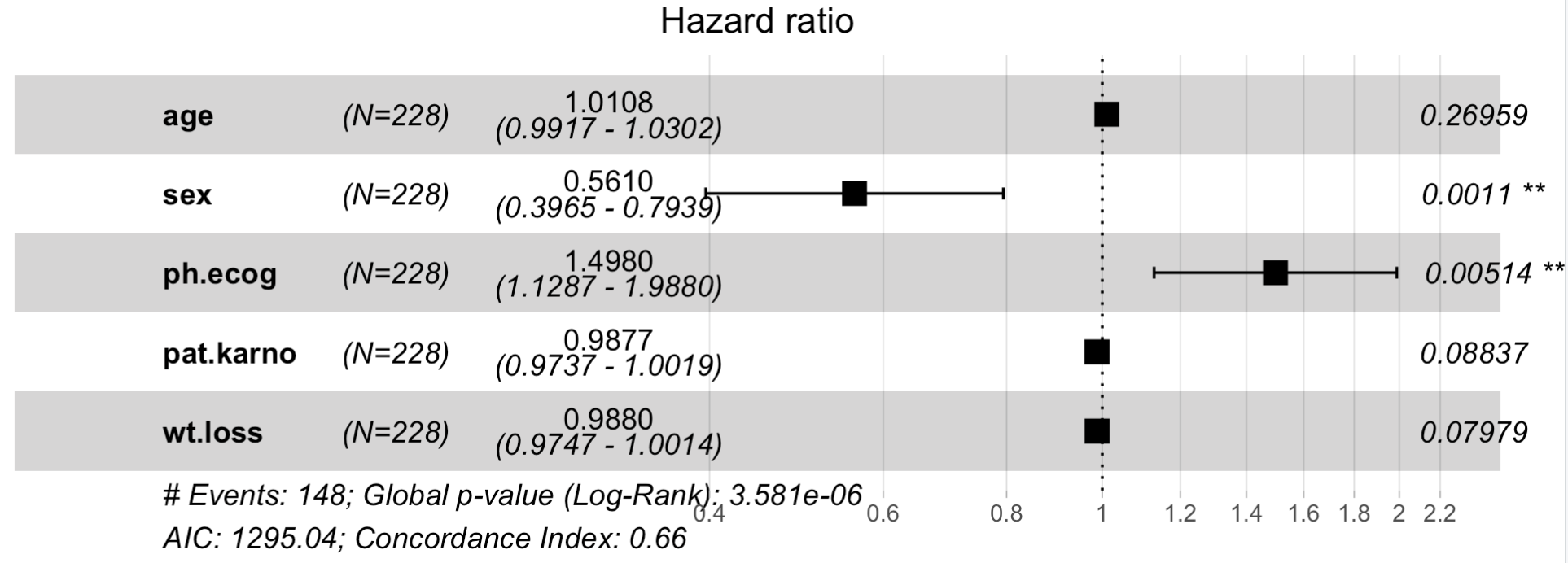
可以看到,对这个癌症来说,性别和ph.ecog这两个因素对病人的生存影响非常显著。
这个时候很多人都不满足于次,仍然是在各种交流群问诺莫图(Nomogram)的做法,其实在R里面也是实现起来超级容易,就是加载rms包,并且使用cph和nomogram函数即可。
接着看列线图
列线图,又称诺莫图(Nomogram),它是建立在回归分析的基础上,使用多个临床指标或者生物属性,然后采用带有分数高低的线段,从而达到设置的目的:基于多个变量的值预测一定的临床结局或者某类事件发生的概率。
bc<-cancer
dc<-datadist(bc);dc
options(datadist="dc")
library(rms)
# Cox Proportional Hazards Model and Extensions , cph {rms}
f <- cph(Surv(time, status) ~ age + sex +ph.ecog + pat.karno +wt.loss,
x=T, y=T, surv=T, data=cancer, time.inc=36)
summary(f)
# Fit Proportional Hazards Regression Model , coxph {survival}
surv<- Survival(f)
nom<- nomogram(f, fun=list(function(x) surv(36, x), function(x) surv(60, x),
function(x)surv(120, x)), lp=F, funlabel=c("3-year survival", "5-yearsurvival", "10-year survival"),
maxscale=10, fun.at=c(0.95,0.9, 0.85, 0.8, 0.75, 0.7, 0.6, 0.5))
plot(nom)
出图如下:
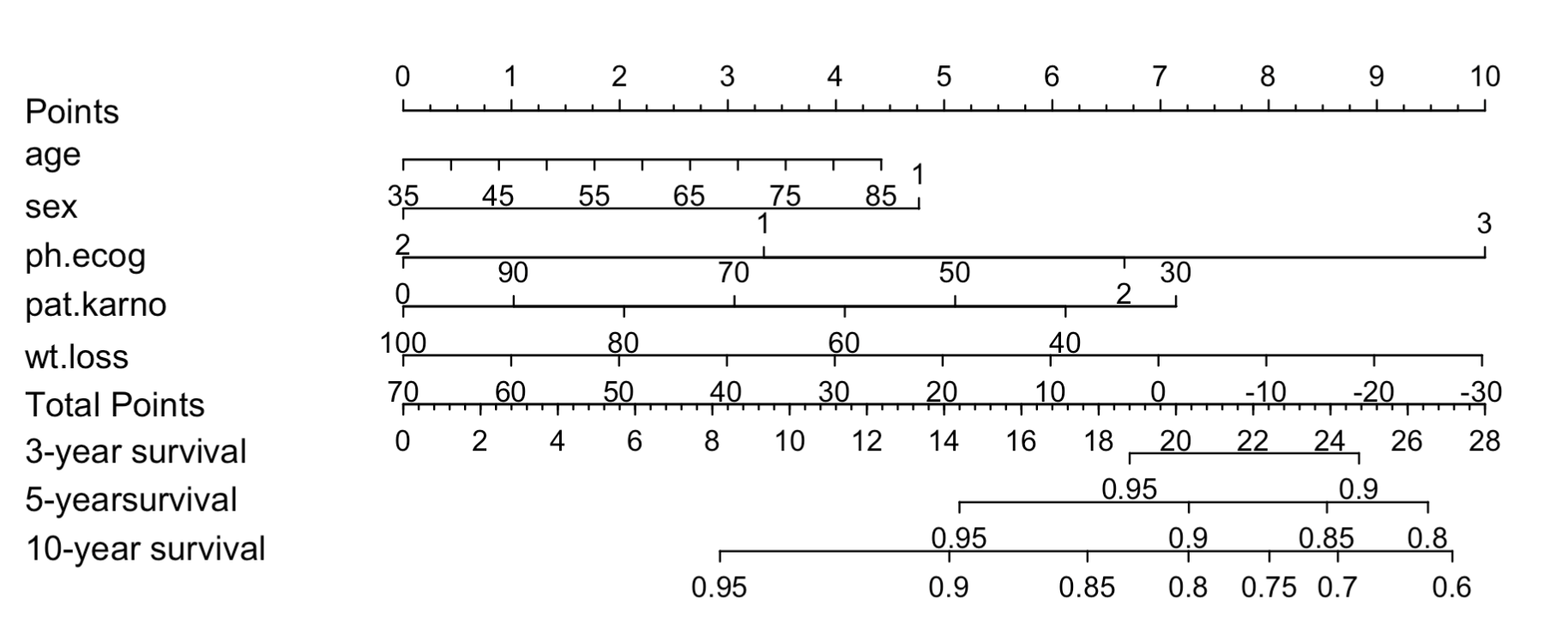
假如你有自己的数据也想做风险因子森林图和列线图
只需去看看 survival 包里面的 cancer这个内置数据集:
library(survival)
colnames(cancer)
DT::datatable(cancer)
把你自己的病人信息整理成为类似的数据结构,后面的代码就无需修改,全部出一模一样的图!
再怎么强调生物信息学数据分析学习过程的计算机基础知识的打磨都不为过,我把它粗略的分成基于R语言的统计可视化,以及基于Linux的NGS数据处理:
把R的知识点路线图搞定,如下:
- 了解常量和变量概念
- 加减乘除等运算(计算器)
- 多种数据类型(数值,字符,逻辑,因子)
- 多种数据结构(向量,矩阵,数组,数据框,列表)
- 文件读取和写出
- 简单统计可视化
- 无限量函数学习