不止一个人问我,他单细胞差异分析的结果,因为p值过于显著,无限接近于0,导致火山图展现非常诡异!
这个是单细胞自身特性导致,它两个分组的细胞数量太多,大概率会导致p值过于显著,无限接近于0。我们以 SeuratData包里面的 pbmc3k 数据集举例说明:
library(SeuratData) #加载seurat数据集
getOption('timeout')
options(timeout=10000)
# InstallData("pbmc3k")
data("pbmc3k")
sce <- pbmc3k.final
library(Seurat)
table(Idents(sce))
deg = FindMarkers(sce,ident.1 = 'NK',
ident.2 = 'B')
head(deg[order(deg$p_val),])
可以看到,我们这里使用 NK细胞和B细胞的差异结果:
> head(deg[order(deg$p_val),])
p_val avg_log2FC pct.1 pct.2 p_val_adj
GZMB 3.186146e-97 5.507567 0.961 0.017 4.369480e-93
NKG7 1.262672e-94 6.262287 1.000 0.087 1.731628e-90
PRF1 1.835435e-93 4.612813 0.948 0.029 2.517115e-89
GZMA 3.036581e-93 4.466820 0.929 0.015 4.164367e-89
CTSW 3.151498e-93 4.203776 0.987 0.070 4.321965e-89
CST7 9.767143e-92 4.380031 0.948 0.038 1.339466e-87
> table(Idents(sce))
Naive CD4 T Memory CD4 T CD14+ Mono B CD8 T
697 483 480 344 271
FCGR3A+ Mono NK DC Platelet
162 155 32 14
这个时候的差异分析结果其实就是两个单细胞亚群各自的标记基因,上面显示的NK细胞亚群相对于B细胞来说, 统计学显著上调的基因就是 “GZMB” “NKG7” “PRF1” “GZMA” “CTSW” “CST7” 这些耳熟能详的NK细胞的特性标记基因啦。
一个简单的火山图,使用EnhancedVolcano包 ,代码如下所示:
library(EnhancedVolcano)
EnhancedVolcano(res,
lab = rownames(res),
x = 'avg_log2FC',
y = 'p_val_adj')
效果如下所示:
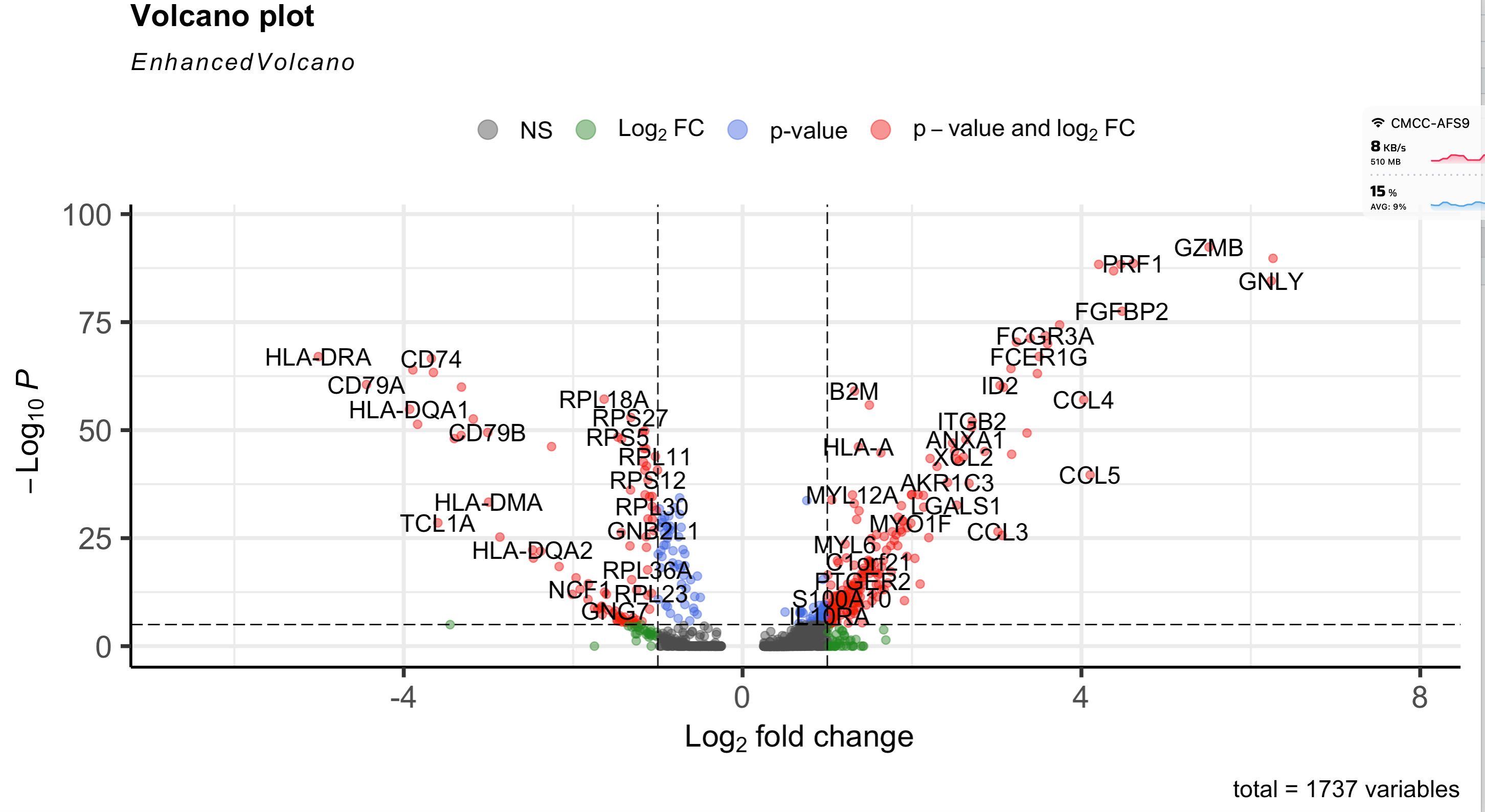
因为这个举例的火山图还算是可以,并没有出现致p值过于显著,无限接近于0的情况发生,因为细胞数量并不多,就155个NK细胞和344个B细胞的差异分析而已。但是如果是大家的真实单细胞数据集,现在细胞数量都很可观,很容易出现 p值过于显著,无限接近于0的情况发生。上面的火山图代码可能会出现很诡异的可视化效果。
恰好我最近看到了一个有意思的展现方式,就是忽略这个统计学指标p值,因为反正都是统计学显著的,大于0.01即可,p值再小也不是我们关心的重点。
发表在NATURE COMMUNICATIONS | (2021) 的 文章:《CD177 modulates the function and homeostasis of tumor-infiltrating regulatory T cells》,链接是:https://www.nature.com/articles/s41467-021-26091-4
如下所示:
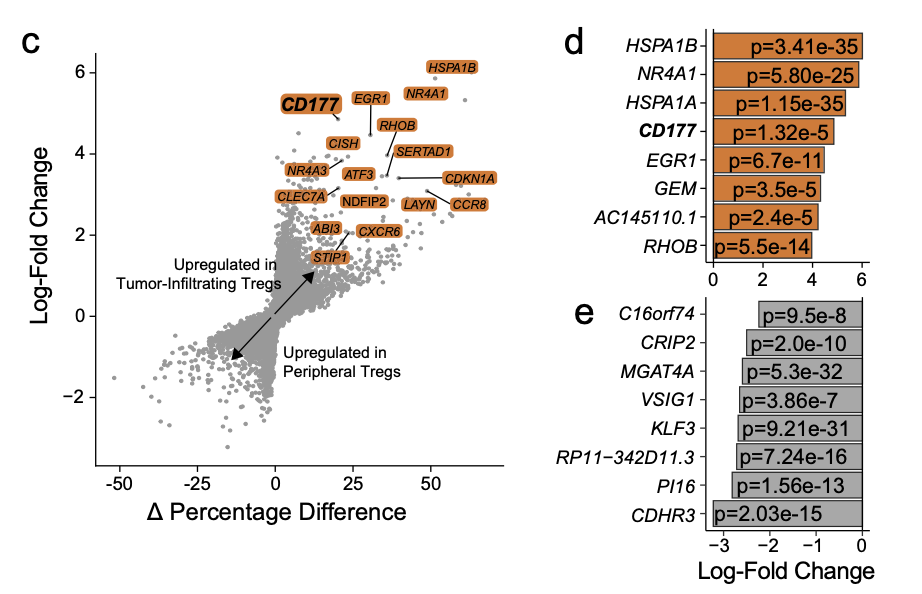
文章对这两个图的描述是:
- c Differential gene expression analysis using the log-fold change expression versus the difference in the percentage of cells expressing the gene comparing TI versus PB Treg cells (Δ Percentage Difference). Genes labeled have log-fold change > 1, Δ Percentage Difference > 20% and adjusted P-value from Wilcoxon rank sum test <0.05.
- d Top eight upregulated genes by log-fold change in TI Treg cells with adjusted P-value <0.05.
左边的图c就是一个普普通通的散点图,但是添加了一些基因:
plot(deg$avg_log2FC,(deg$pct.1 - deg$pct.2))
右边的d和e图,就更简单的,就是普普通通的条形图,比较耗费时间的应该是把p值写进去条形图里面,最好是ggplot相关语法会方便一点。