对两次差异分析取交集的思路,被滥用最严重的就是数据挖掘领域,有一个 ESTIMATE 算法,是根据肿瘤样品转录组测序数据表达量矩阵来推断其肿瘤微环境构成,主要是肿瘤纯度,基质细胞和免疫细胞。
肿瘤免疫微环境我们讲了很多内容了,主要是 ESTIMATE 算法和CIBERSORT算法 ,目录是:
- estimate的两个打分值本质上就是两个基因集的ssGSEA分析
- 针对TCGA数据库全部的癌症的表达量矩阵批量运行estimate
- 不同癌症内部按照estimate的两个打分值高低分组看蛋白编码基因表达量差异
- 使用CIBERSORT算法推断全部tcga样品的免疫细胞比例
也有几百篇类似的数据挖掘文章了,它们总是喜欢落脚到estimate或者CIBERSORT结果的预后意义。让我最不能理解的是文章:《Screening the Cancer Genome Atlas Database for Genes of Prognostic Value in Acute Myeloid Leukemia》,研究者们探索了 tumor microenvironment (TME) in acute myeloid leukemia (AML). 就是 ESTIMATE 算法,这个算法会给每个病人3个打分,其中基质细胞和免疫细胞打分是连续值,可以根据中位值对病人进行分组:
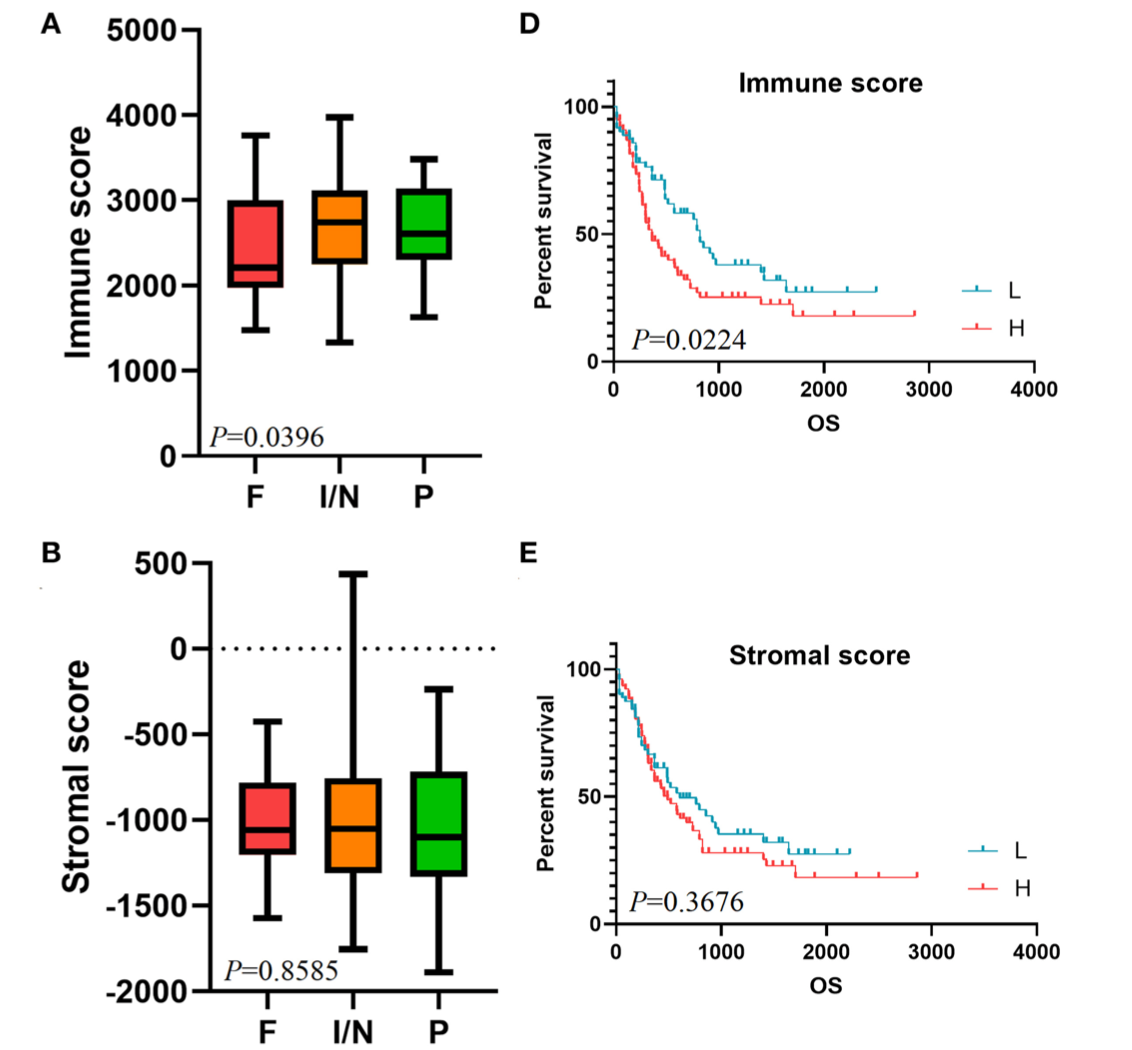
有了高低分组,就可以进行简单的差异分析,两个差异分析就可以取交集:
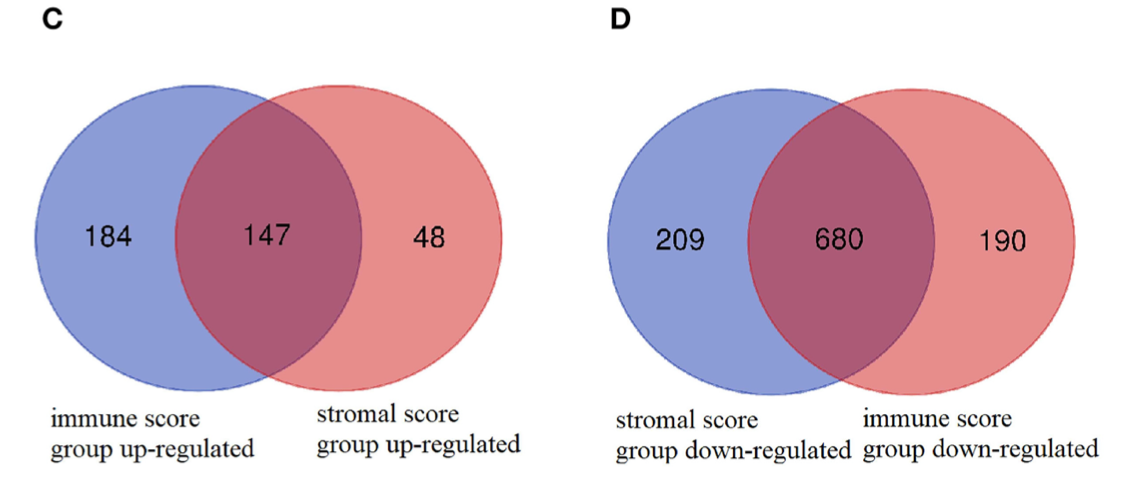
这些基因就可以进行生物学功能数据库注释,进行数据库网络分析找中心节点,进行数据库药物查询凑图。 - In the Venn plots, 147 up-regulated intersected genes (Figure2C) and 680 down- regulated intersected genes were screened (Figure 2D).
- PPI network contained 786 nodes and 1,774 edges. Results from STRING were further analyzed by Cytoscape. The results of algorithms from cytoHubba applied in hub gene identification were shown in Figure 4.
- After hub genes were detected, we evaluated the prognostic value by K-M analysis based on log-rank test. P < 0.05 was regarded as statistically significant.
问题是, 肿瘤微环境这个概念对实体瘤是有意义的,但是对血液肿瘤来说, 取样测序的时候,就是 bone marrow or peripheral blood samples from patients with acute myeloid leukemia (AML) ,这个 ESTIMATE 算法首先就不适合啊!
其次,哪怕是实体瘤,确实有肿瘤微环境,使用了 ESTIMATE 算法对每个转录组测序样品给到了 基质细胞和免疫细胞打分,也确实是可以高低分组各自差异分析,然后取交集,比如:《Bioinformatic identification of renal cell carcinoma microenvironment- T associated biomarkers with therapeutic and prognostic value》, 如下所示:

如果你使用 Bioinformatic + ESTIMATE + cancer 这样的关键词进行文献搜索,你会发现33种癌症基本上都被做了一个遍。实在是无法理解,这样的交集是想说明什么,还是说纯粹为了交集而交集呢?并不是说交集思维不可取
交集其实是无处不在,毕竟它是科研设计的底层逻辑之一,比如文章:Schulten et al. J Transl Med (2017) ,标题是《Comprehensive molecular biomarker identification in breast cancer brain metastases》,链接是 https://doi.org/10.1186/s12967-017-1370-x
一个很简单的转录组芯片队列,分成了3组: - 3个 Breast cancer brain metastases å(BCBM)
- 16 non‐brain metastatic BC
- 16 primary brain tumors (prBT)
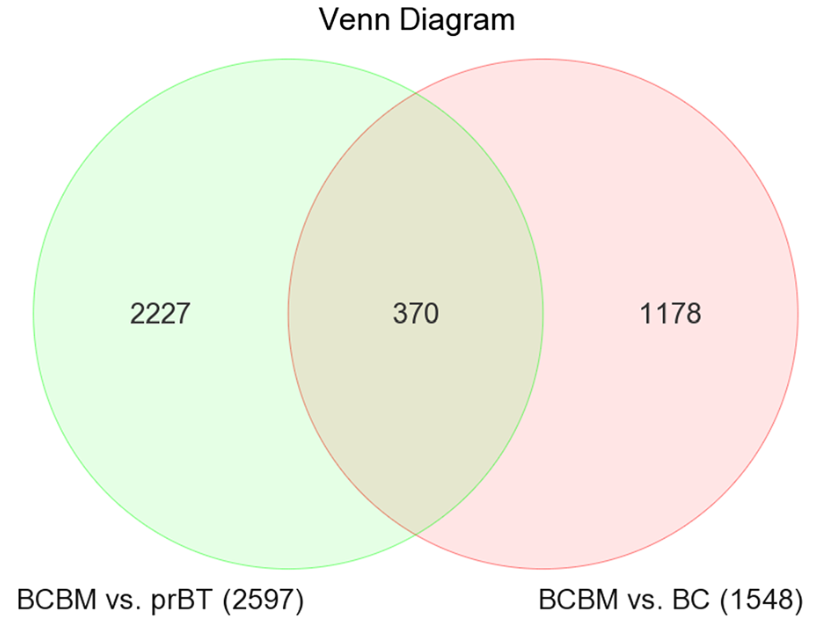
这3个分组, 做两次差异分析,都是 BCBM vs. BC and prBT,而且都是同样的阈值: a false discovery rate (FDR) p < 0.05 and fold change (FC) > 2. 两次差异分析的交集就是肺癌脑转移的特异性高表达基因。
韦恩图如下所示 :
接下来也是非常简单的对这些基因进行生物学功能数据库富集,生存分析等等。