看到了新华社 在2023-12-04 发布的新闻:《三甲医院超收21万余元医疗费,官方通报!》,提到了医院过度收费而且违规使用医保基金的问题,如下所示:

然后就顺藤摸瓜搜索了一下这件事的前因后果,发现 经济观察报 在2023-12-03 发布的:《名校博士自述:我是怎样查出医院多收我爸10万医疗费的》,讲清楚了名校博士是如何与违法违规套取医保基金、侵害老百姓“救命钱”的医疗蛀虫战斗的。
首先需要拿到每日医疗花费明细
这个可以是每天找护士打印医疗花费明细,但是就需要手动录入这些纸质版信息到电脑Excel里面,不过现在有很多自动化扫描软件可以识别纸质版信息。
另外一个简单的方案就是如果医院有自动化信息接口,理论上可以根据每个患者的唯一id号去在线获取全部的医疗花费明细,如下所示:
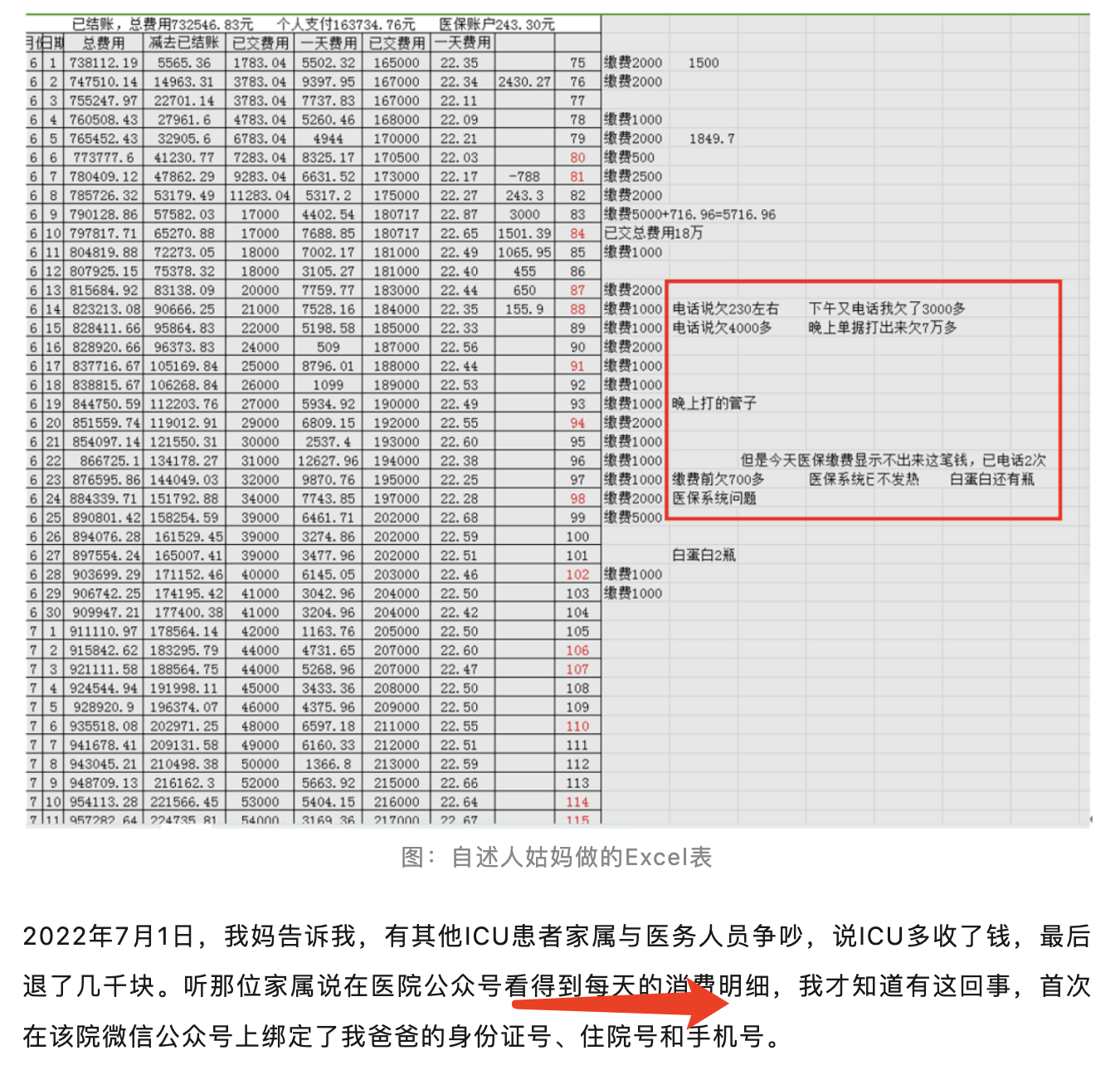
出院的时候一定要复印并封存了全部病历资料和医疗花费明细,在与原件核对一致后,由院方加盖公章,符合《医疗纠纷预防和处理条例》第十六条之规定,于是后面对费用的核查就有了相关依据。
然后在统计软件针对医疗花费明细数据进行建模
其实都不需要太高级的统计学知识,仅仅是肉眼看看那些波动比较奇怪的项目即可,如下所示:
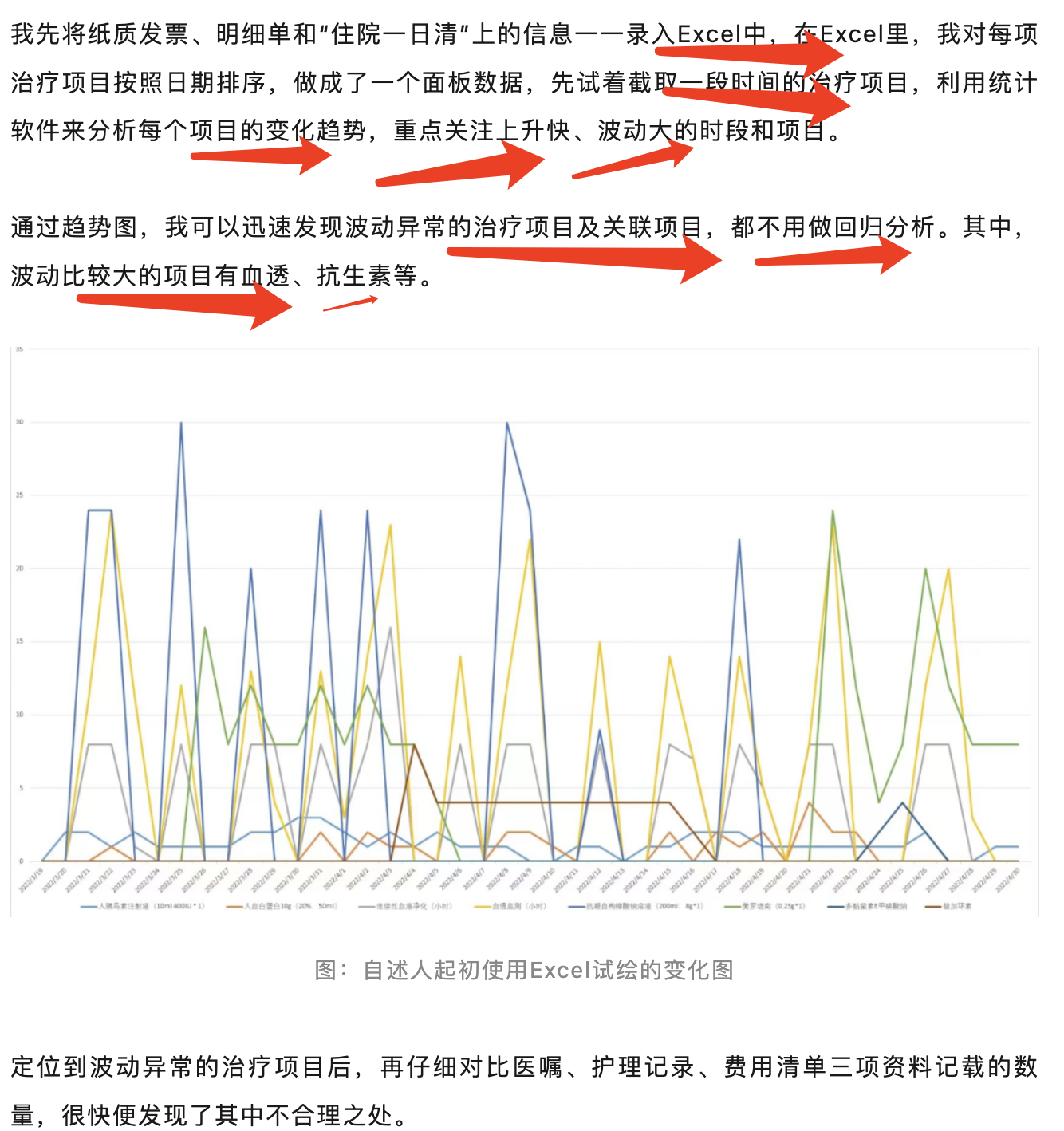
有一些造假可能更隐蔽
前面提到的医疗花费明细的造假仅仅是医疗人员的临时起意或者说没有统计学融入的人工掺假,其实还蛮容易靠肉眼发现。因为仅仅是依靠统计学常识就能发现医院的不合理收费啦,比如如下所示的正态分布常识:
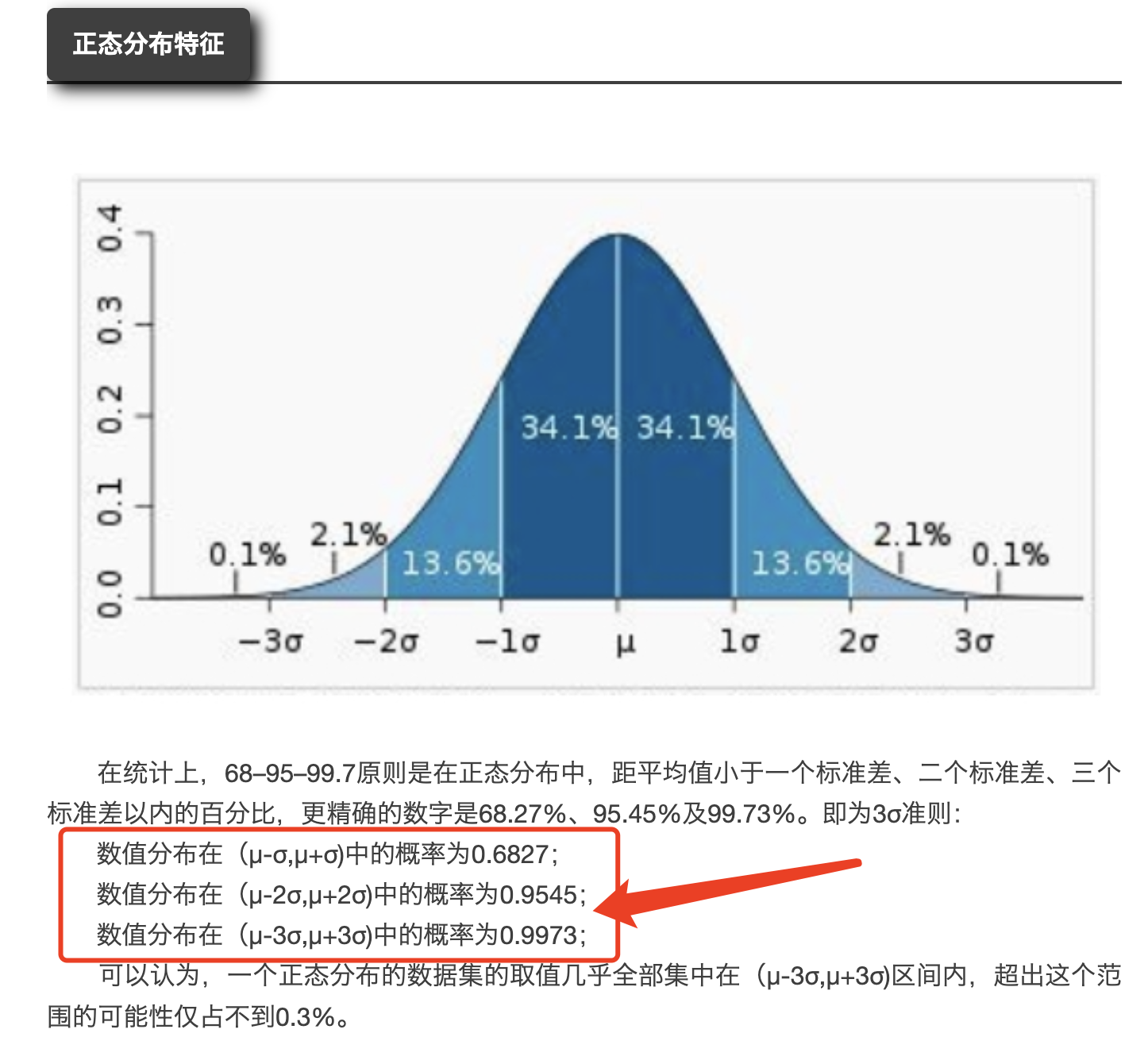
但是如果医院是成体系的依靠统计学背景来“人工制造”让你肉眼看起来合理的收费,这个时候就可能是需要深度统计学建模了。在另外一个公众号确实是看到了类似的描述,需要使用R语言这样的专业的数据分析软件啦:
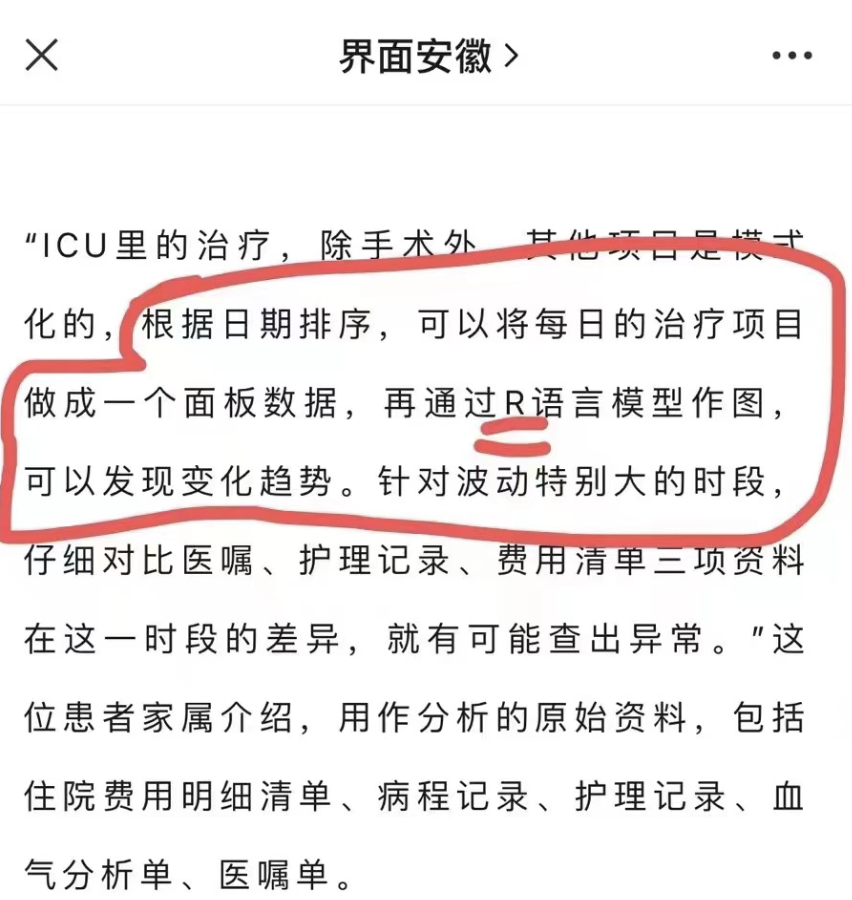
统计分布是概率论和统计学中的一个重要概念,用于描述随机变量在可能取值上的分布情况。统计分布可以帮助我们理解随机变量的可能取值以及这些值出现的概率。统计分布通常由概率密度函数(Probability Density Function,PDF)或累积分布函数(Cumulative Distribution Function,CDF)来描述。概率密度函数描述了随机变量在不同取值上的概率分布情况,而累积分布函数则描述了随机变量小于等于某个特定取值的累积概率。
R语言内置了许多用于生成各种统计分布的函数。以下是一些常见的内置统计分布系列函数:
- 均匀分布(Uniform Distribution):
runif(n, min, max): 生成n个服从指定区间[min, max]的均匀分布的随机数。
- 正态分布(Normal Distribution):
rnorm(n, mean, sd): 生成n个服从指定均值和标准差的正态分布的随机数。
- 二项分布(Binomial Distribution):
rbinom(n, size, prob): 生成n个服从指定试验次数(size)和成功概率(prob)的二项分布的随机数。
- 泊松分布(Poisson Distribution):
rpois(n, lambda): 生成n个服从指定均值(lambda)的泊松分布的随机数。
- 伽马分布(Gamma Distribution):
rgamma(n, shape, scale): 生成n个服从指定形状参数(shape)和尺度参数(scale)的伽马分布的随机数。
- 指数分布(Exponential Distribution):
rexp(n, rate): 生成n个服从指定速率参数(rate)的指数分布的随机数。
- 贝塔分布(Beta Distribution):
rbeta(n, shape1, shape2): 生成n个服从指定形状参数(shape1, shape2)的贝塔分布的随机数。
- 卡方分布(Chi-Square Distribution):
rchisq(n, df): 生成n个服从指定自由度(df)的卡方分布的随机数。
- t分布(t-Distribution):
rt(n, df): 生成n个服从指定自由度(df)的t分布的随机数。
- F分布(F-Distribution):
rf(n, df1, df2): 生成n个服从指定自由度(df1, df2)的F分布的随机数。
这些函数可以用于生成服从不同统计分布的随机数,供统计模拟、假设检验、蒙特卡洛方法等使用。注意,每个函数的参数可能有所不同,具体的参数含义可以在R的帮助文档中查找。
最后汇总一下识别医疗乱收费的3个方法
- 数据分析:使用数据分析工具和技术来检测异常模式或趋势,可能表明数字的操纵。
- 统计学方法:应用统计学方法来评估数据的真实性和一致性,以及是否存在不寻常的波动或异常。
- 专业机构的业务流程审查:审查医疗的业务流程,了解是否存在可能导致数字操纵的内部控制弱点。
前面的两个环节是个人可以依靠自己的数据分析能力参与的,但是专业机构的业务流程审查我们大概率是帮不上忙了,取决于当地医疗体系的氛围啦。不过,如果自己通过数据分析拿到了证据,是可以走法律流程解决这样的医疗蛀虫行为。
如何提高自己的数据分析能力呢
首先是起码得懂一些统计学基础名词,比如前面提到的正态分布,有一个“小白学统计”公众号做的不错,介绍了很多统计学概念和一些观点的通俗介绍,如标准误到底是什么意思,P值如何理解,中心极限定理是在说什么,等等。
- (1)P值的理解
- (2)假设检验的理解
- (3)一类错误和二类错误的理解
- (4)标准差和标准误
- (5)置信区间的理解
- (6)正态分布的理解
- (7)分类资料与计数资料
- (8)计数资料与连续资料
- (9)什么是虚拟变量
- (10)关于抽样误差
- (11)样本量大于30就算正态了吗?
- (12)判断正态性的一些简易方法
- (13)多变量与多因素的区别
- (14)信度与效度评价
- (15)问卷用不用做信度和效度评价
- (16)问卷用不用做信度和效度评价之二
- (17)传染病模型中的拐点
- (18)传染病数学模型简介
- (19)从统计学角度解读有效率
然后推荐statquest学习小组长笔记:
- StatQuest生物统计学专题 - 基础概念
- StatQuest生物统计学专题 - p值
- StatQuest生物统计学 - 拟合基础
- StatQuest生物统计学 - 线性拟合的R2和p值
- StatQuest生物统计学专题 - 分位数及其应用
- StatQuest生物统计学专题 - 极大似然估计
- StatQuest生物统计学专题 - PCA
- StatQuest生物统计学专题 - PCA的奇异值分解过程
- StatQuest生物统计学专题 - LDA
- StatQuest生物统计学专题 - MDS
- StatQuest生物统计学专题 - tSNE的基础概念
- StatQuest生物统计学专题 - 聚类及其算法(1)
- StatQuest生物统计学专题 - 聚类及其算法(2)
- StatQuest生物统计学专题 - K近邻算法
- StatQuest生物统计学专题 - 决策树(1)
- StatQuest生物统计学专题 - 决策树(2)
- StatQuest生物统计学专题 - 随机森林(1) 构建与评价
- StatQuest生物统计学专题 - 随机森林(2) R实例
这一切的前提是掌握好一门统计学编程语言
比如R语言,再怎么强调生物信息学数据分析学习过程的计算机基础知识的打磨都不为过,我把它粗略的分成基于R语言的统计可视化,以及基于Linux的NGS数据处理:
把R的知识点路线图搞定,如下:
- 了解常量和变量概念
- 加减乘除等运算(计算器)
- 多种数据类型(数值,字符,逻辑,因子)
- 多种数据结构(向量,矩阵,数组,数据框,列表)
- 文件读取和写出
- 简单统计可视化
- 无限量函数学习