最近在交流群看到了一个很有意思的讨论,就是他看到了他们领域的癌症高分文献,发现里面的差异分析结果跟之前的另外一个高分文献里面的基因很不一样,就以为我们生物信息学是万能魔法,可以让任意基因都有差异:
有这样的想法的人不在少数,所以有必要澄清一下,通常情况下,我们会做很多次差异分析然后取交集,这样的话保证拿到的基因是非常可靠的,这个过程中其实我们并不会关心不同的差异分析为什么会有不一样的地方,同样的实验设计可能导致不同的转录组差异分析结果和差异基因列表,这可能是由于以下因素导致的:
- 技术变异性(Technical Variability):在转录组测序中,存在技术上的变异性,包括样本制备、测序深度、测序平台等因素。不同的实验室或研究者可能使用不同的实验方法、仪器和分析流程,这些差异可能导致不同的结果。
- 生物变异性(Biological Variability):生物样本之间存在天然的变异性。即使在相同的实验设计下,不同样本之间的基因表达水平也会有一定的差异。这种生物变异性可能掩盖或引入差异基因。
- 数据预处理和分析方法:数据预处理步骤(如质量控制、归一化等)和差异分析方法的选择会影响最终的结果。不同的预处理和分析方法可能产生不同的差异基因列表。
- 统计显著性阈值:差异分析通常涉及对基因表达的统计显著性测试。不同的研究者或实验室可能使用不同的显著性阈值,如调整的p值或fold change,以确定哪些基因被视为差异表达。这些阈值的选择可以影响最终的结果。
- 样本大小:较小的样本大小可能导致统计功效不足,难以检测到真正的差异。因此,不同实验中的样本大小也可能影响结果的一致性。
- 生物学条件:有时,生物学条件可能因为微小的变化而导致不同的差异基因。例如,细胞的生长状态、处理条件、采样时间点等微小差异可能对差异基因的鉴定产生影响。
为了减少这些因素带来的差异,研究者通常采取以下策略:
- 使用标准化的实验流程和数据处理方法。
- 增加样本数量以提高统计功效。
- 使用多个独立的差异分析工具或方法进行验证。
- 仔细报告实验和数据分析的细节,以便其他研究者能够复制和验证结果。
总之,虽然同样的实验设计可能产生不同的差异分析结果,但通过标准化方法、适当的统计分析和透明的报告,可以增加结果的一致性和可靠性。科学界通常鼓励研究的复制和验证,以确保研究结果的可信度。如果我们反向取交集呢
如果是针对不同的差异分析结果取交集,很容易陷入一个困境,就是没有一个基因是在所有的多次结果都出现,所以通常呢如果要取那些在多个数据集出现过的基因,并不强求是在所有数据集都出现。
同样的道理是,如果我们针对那些没有差异的基因去取交集,会不会也出现没有任意一个基因在所有数据集都出现没有差异的现象呢?也就是说,如果我们反向取交集呢?真的是所有的基因都可以随心所欲的差异吗?
在前面的 院士课题组的WGCNA数据挖掘文章能复现吗 教程里面,我们使用Bile Duct Cancer (CHOL)]这个数据集,然后根据里面的样品的二分类属性(肿瘤样品和正常组织对照)做一个简单的差异分析,拿到了转录组差异分析后的上下调基因列表。
就可以作为学徒作业啦,每次都是从(肿瘤样品和正常组织对照)这两个分组里面随机取5个样品,然后做差异分析,这样的操作持续100次甚至1000次,看看是不是汇总得到的差异基因会逐渐增加,涵盖到全部的两万多个基因呢?比如做一下下面的差异基因数量增长曲线:
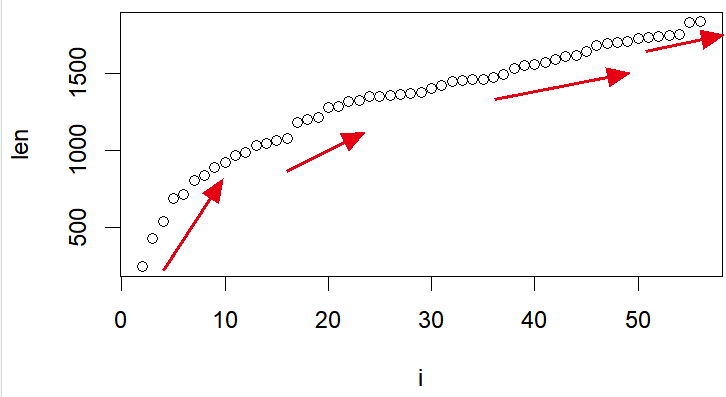
我演示了这个GSE65391数据集的两分组(72 are Healthy controls and 924 are SLE)的差异分析,然后呢我们从每个分组每次随机抽取5个样品组合成为两分组的差异分析,但是step-other-samples以及step-other-veen两个代码需要修改一下,大家可以帮忙吗? https://cowtransfer.com/s/e1d552e1c9db45 点击链接查看 [ GSE65391-SLE-illumina-array.zip ] , 这个是我写的草稿,我觉得蛮有意思的!
都可以作为一个生物信息学课题!其实只需要看基因在群体的方差即可
如果一个基因在群里里面的表达量非常稳定,就是方差很小,那么无论是我们怎么样分组,它都不可能会被统计学软件根据一系列指标判定为差异基因。
其中,我们最熟悉的管家基因就很多都是这样的基因,”管家基因”(housekeeping genes)通常不会被识别为差异表达基因,这是因为它们在不同组织或条件下的表达水平相对稳定。这些基因的主要功能是维持细胞的基本生活过程,如细胞代谢和细胞结构的维护,因此它们需要在各种情况下保持相对恒定的表达水平。
以下是一些解释为什么管家基因通常不会在差异分析中出现的原因:
- 稳定的表达水平:管家基因的表达水平通常不受外部条件的显著影响。它们在不同细胞类型和生理状态下的表达变化较小,因此不容易被标记为差异表达基因。
- 用于归一化:管家基因通常用于在差异表达分析中进行数据归一化。归一化是为了消除不同样本之间的技术变异性,使得比较更具可比性。由于它们的表达相对稳定,它们在这个过程中不会被认为是差异表达的。
- 不太具有生物学意义:由于管家基因的功能是维持基本的生命过程,它们的表达变化通常不与特定的生物学现象或疾病状态相关。因此,在寻找与特定条件或疾病相关的差异基因时,通常会排除这些稳定的基因。
要进行差异表达分析,研究者通常会选择那些在不同组之间表达水平显著不同的基因,因为这些基因可能与特定的生物学过程或条件相关联。虽然管家基因在差异分析中通常不被考虑,但它们在实验设计、数据归一化和质量控制等方面仍然具有重要的作用,以确保实验结果的准确性和可靠性。