总是有粉丝在我们的各个公众号教程下面留言关于单细胞数据处理的细节问题,比如为什么我们过滤线粒体基因表达量超15%的细胞啊,为什么看核糖体基因表达量占比啊等等。其实看一下基础10讲: Continue reading
六
25
总是有粉丝在我们的各个公众号教程下面留言关于单细胞数据处理的细节问题,比如为什么我们过滤线粒体基因表达量超15%的细胞啊,为什么看核糖体基因表达量占比啊等等。其实看一下基础10讲: Continue reading
这两天在朋友圈看到了不少10X相关会议哦,宣传它们的10X单细胞产品相关文章多达2000篇啦,不乏CNS大作。 Continue reading
2021年Single Cell Genomics Day在美国东部时间2021年3月26日星期五上午10点至下午5点线上进行。主要议题有: Continue reading
今天要介绍的文章是: Tumour heterogeneity and intercellular networks of nasopharyngeal carcinoma at single cell resolution. Nat Commun 2021 Feb 2;12(1):741. PMID: [33531485] Continue reading
早些年,我们在你都不感谢我凭什么要求我帮你宣传:有奖征集了发文章的规范化致谢格式!
格式超级简单:We thank Dr.Jianming Zeng(University of Macau), and all the members of his bioinformatics team, biotrainee, for generously sharing their experience and codes.
不过,很少宣传,所以看到了这个规范化致谢格式的并不多,偶尔就会有人在我们《生信技能树》公众号后台提问这件事。但是我们看后台的频率并不高,所以还是专门的再宣传一下吧,而且并不是只有你发表了SCI才能致谢我们生信技能树,绝大部分朋友不一定会去搞科研,发文章本来就没意义对大部分人来说。
如果我们这七年在《生信技能树》,《生信菜鸟团》,《单细胞天地》的系列教程确实对你有帮助,你的本硕博毕业论文,也可以加上啊,毕竟每个人都会毕业哦!

其实真没有,毕竟我们这七年在《生信技能树》,《生信菜鸟团》,《单细胞天地》的系列教程都是免费给大家的,你都不付费,再要求好处就有点过分了!
而且呢,如果使用好处来诱惑你去致谢我,这个就显得不伦不类了,而且很可能是学术不端了。
但是呢,赠人玫瑰,手有余香,我们写这个推文,只是提醒那些真心觉得我们的付出对大家的学术科研工作确实是有帮助但是不记得可以致谢的小伙伴!如果你致谢了,我会很开心,咱们会混个脸熟,至少某一天你需要我的帮助了,我会优先回答你的问题!
七八年前我开始自学生物信息学的时候,乐此不疲的收集了很多相关英文pdf书籍,比如: Continue reading
很早以前我就在《生信技能树》的推文:新的ngs流程该如何学习(以CUT&Tag 数据处理为例子),提到了我自己是不太可能去把所有的ngs流程全部录制视频的,只能说是更好的传达学习方法给到大家。
其实如果你看过我表观组学系列,比如《ChIP-seq数据分析》 和 《ATAC-seq数据分析》 就会知道这些技术都可以被单细胞化, 如果你具备比较好的背景知识,理论上是可以自己根据文档把它们对应的单细胞水平的数据分析摸索成功。那就作为学徒作业吧,摸索scChIPseq流程!
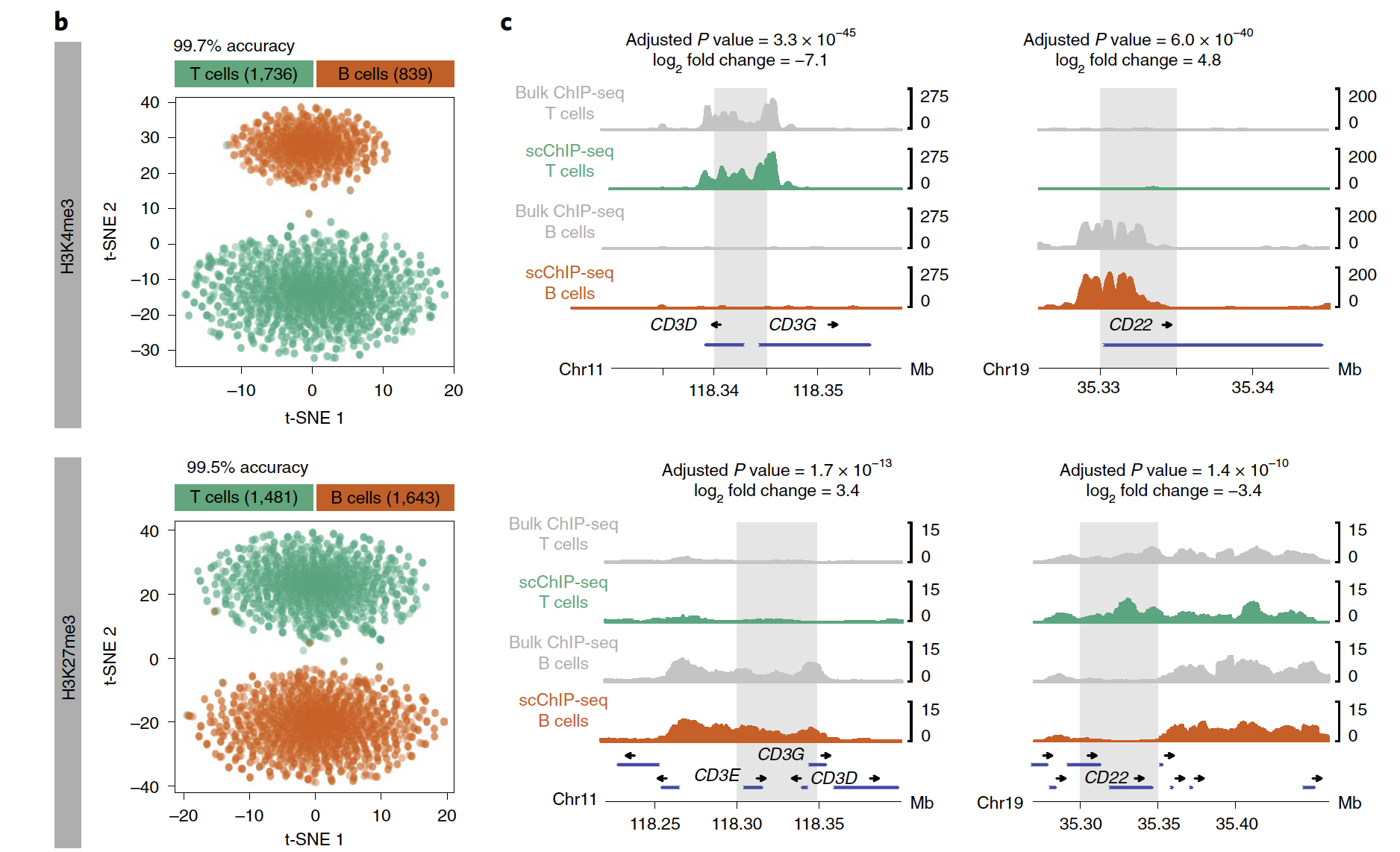
文章是:High-throughput single-cell ChIP-seq identifies heterogeneity of chromatin states in breast cancer. Nat Genet 2019 Jun;51(6):1060-1066. PMID: 31152164
数据在:https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE117309
GSM3290887 H3K4me3_scChIPseq_Jurkat-Ramos
GSM3290888 H3K27me3_scChIPseq_Jurkat-Ramos
GSM3290889 H3K27me3_scChIPseq_HBCx-95
GSM3290890 H3K27me3_scChIPseq_HBCx-95-CapaR
GSM3290891 H3K27me3_scChIPseq_HBCx-22
GSM3290892 H3K27me3_scChIPseq_HBCx-22-TamR
# 下面的4个单细胞都是10x技术的
GSM3290893 H3K27me3_scRNAseq_HBCx-95
GSM3290894 H3K27me3_scRNAseq_HBCx-95-CapaR
GSM3290895 H3K27me3_scRNAseq_HBCx-22
GSM3290896 H3K27me3_scRNAseq_HBCx-22-TamR
可以看到,区分T和B细胞亚群的效果非常好!
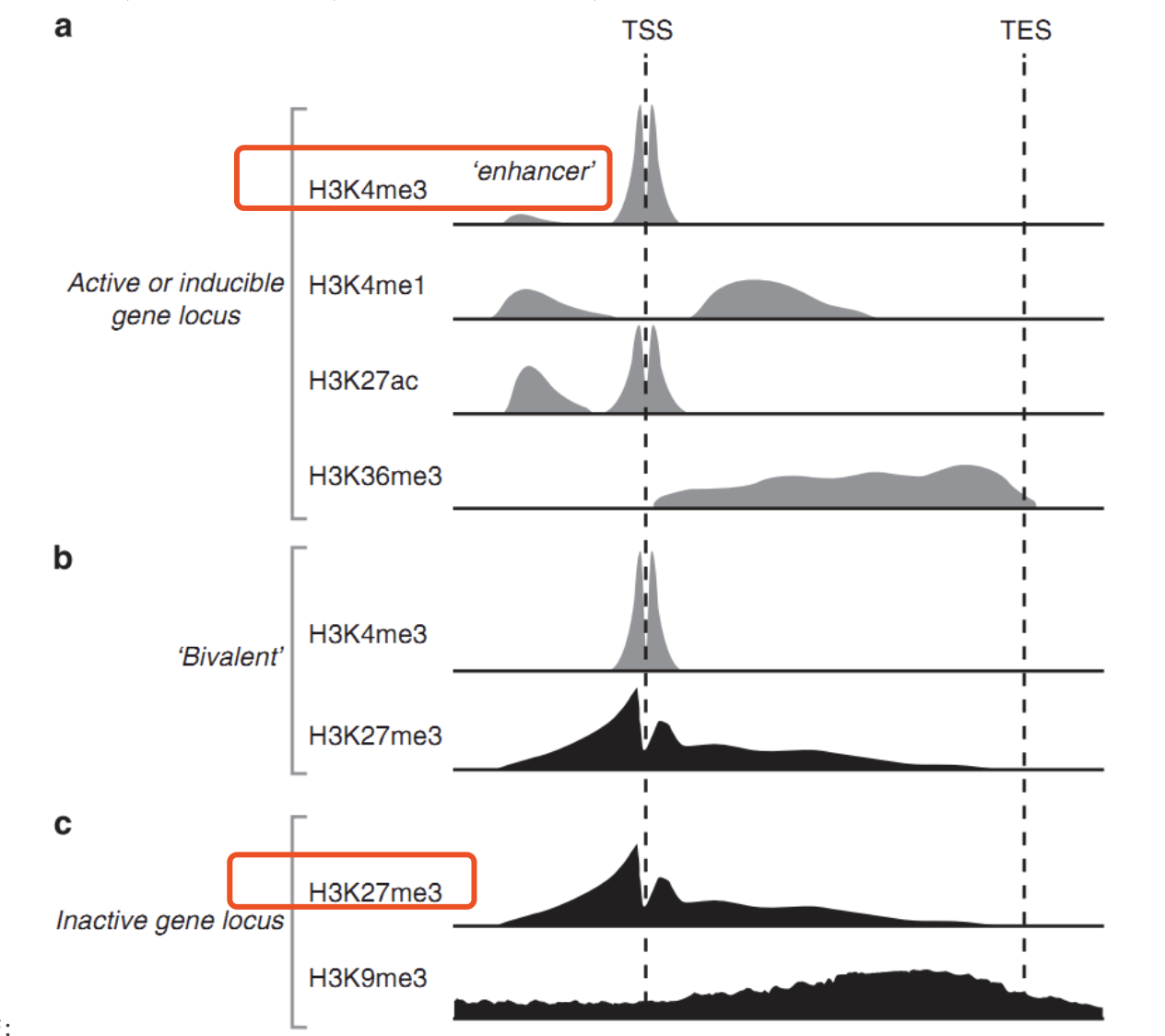
两种组蛋白修饰情况:
这两个两种组蛋白修饰的生物学意义完全不一样哦:
数据分析方面也是拿到矩阵,主要是Bowtie v.1.2.2比对到mm10和 hg38两个 参考基因组,去除PCR重复,:
如果你没有单细胞转录组认知,需要先看看基础10讲:
最基础的往往是降维聚类分群,参考前面的例子:人人都能学会的单细胞聚类分群注释
生物信息学资源基本上都是欧洲的EBI的sanger研究所和美国的MIT的broad研究所创造和整理,单细胞领域也不例外: Continue reading
我们非常强调进入一个领域需要读综述来获取基本认知,尤其是单细胞,我们在《单细胞天地》公众号给大家精选了2017-2020的4篇综述: Continue reading
我B站有一个免费视频教学课程,miRNA-Seq数据挖掘实战
空间转录组服务(16个样本质检、优化、建库)只需要10W人民币哦,高通量单细胞转录组实验服务 (制备、质检、测序和分析,8样本)也只是需要20W人民币哦,你要是问我是怎么知道的,嘻嘻,有绝招: Continue reading
很久以前我在《生信技能树》分享过教程,如果你处理的是小鼠的基因芯片表达矩阵,最后做gsea等分析要对生物学数据库注释,发现绝大部分数据库都是人类的基因名字,有一个取巧的方法是把基因名字修改一下,如下所示: Continue reading
嗨,你好,告诉你个好消息,我们在Frontiers in Genetics (IF2020:3.258; 5 year ~3.5) 杂志上主持的癌症耐药性的research topic开始征稿啦,有兴趣的朋友快来围观。 Continue reading
在周运来的提议下,我们开启了一个颇有仪式感的元旦寄语活动,所以大家在2021年的1月1号的0点看到了这封由单细胞天地编辑团队全体成员“拼凑”出来的信,蓦然回首,发现在这个已经是去了的几乎每天都是在“见证历史”的2020,咱们其实也不差,该发文章的发文 Continue reading
2019的尾巴我们还在发愁来年该如何安排30个城市的巡讲,毕竟全国各地的粉丝都迫切期待我们前往大家所在的城市一起交流生物信息学数据处理技术,没想到突如其来的的疫情让所有的脚步都停了下来。 Continue reading
在朋友圈看到了有人吐槽她下载的表达矩阵里面出现日期基因,挺好玩的,就把gse号码要过来了,是 GSE122083,其日期基因如下: Continue reading
最近有一些小伙伴看到了我六年前的《直播我的基因组》系列,觉得我可能是基因检测解读方面的“专家”,哈哈哈! Continue reading
在CNS图表复现09—上皮细胞可以区分为恶性与否,我分享过有一些上皮细胞亚群是跨越病人的聚类情况,所以先暂时认为他们是非恶性细胞。而在 [CNS图表复现17—inferCNV结果解读及利用之进阶] Continue reading
通常我们安装R包,是来自于 CRAN或者bioconductor,如果要安装大量R包,我们以前分享过一个简化代码,如下:
最近接了一个单细胞转录组项目,有80个10X样品,每个样品的单细胞测序数据都是100G左右的fq.gz文件,很不容易跑完了全部的cellranger流程,发现了一个很有意思的事情,每个样品的输出文件都很很复杂。这个时候我需要把各自样品的html文件拷贝并且改名后先给客户开卡,如下所示的结构: Continue reading