roadmap的官网是:http://www.roadmapepigenomics.org/
精选的129个细胞系,细胞系的介绍如下:http://www.broadinstitute.org/~anshul/projects/roadmap/metadata/EID_metadata.tab
对每个细胞系,都至少处理了5个核心组蛋白修饰数据,还有其它若干转录因子数据。
官网介绍的很详细,我就不翻译了:
- chromatin structure (5C)
- open chromatin (DNase-seq and FAIRE-seq)
- histone modifications and DNA-binding of over 100 transcription factors (ChIP-seq)
- RNA transcription (RNAseq and CAGE)
估计很多小伙伴都没有听过sepsis,现在翻译成中文是脓毒病,很多人会把它与那个缺乏维他命C的败血症混淆,其实完全不一样,因为sepsis致死率非常高!
| sepsis | 英[ˈsepsɪs] | 美['sepsɪs] |
| n. | 脓毒病; 脓毒疾; |
自从我写了那篇关于创业的想法的文章后,传送门: 我也想开个公司(上) , 很多熟悉的朋友,还有不少陌生的朋友都给我来信,跟我讨论我的想法,尤其是几个海外的朋友特别热情,我们深度的讨论了创建自由职业者联盟的可行性,公司如何活下去,盈利点是什么,什么样的价值观才能铸就百年企业等各种话题,可能我们在创业这个领域都还是蹒跚学步的状态,但是大家的热心帮助让我很感动,这也坚定了我继续做知识传播者的想法。我这里简单分享一下我们讨论的几个公司战略方向,因为我还有四五年的博士生涯要度过,暂时无法全心全意的发展事业,如果有人看到了也想朝这个方向发展,我可以免费做咨询服务,我非常乐意看到有人能实现我的想法。 Continue reading
有网友咨询过对于没有参考基因组或者转录组的物种,如何做RNA-seq分析。我觉得这个问题太大了,而且我还真的对这个没有经验。但是我以前看到过一篇文献,里面提到过一个非常全面的转录组 de novo组装注释流程,所以我摘抄了文章里面的生物信息学处理部分,分享给大家: Continue reading
讲到这里,我们的自学CHIP-seq分析系列教程就告一段落了,当然,我会随时查漏补缺,根据读者的反馈来更新着系列教程。其实可视化这已经是一个比较复杂的方向了,不仅仅是针对于CHIP-seq数据。可视化本身是发文章的先决条件,而让人一目了然图片也说明了数据分析人员对数据本身的理解。我这里就列出一些目录和一些工具,和ppt。这个主要靠大家自学了,而且我博客空间有限,就不上传一大堆图片了,大家随便找一些经典的paper里面都会有很多可视化分析。
首先强烈推荐两个网页版工具,针对找到的peaks可视化:
然后再推荐一个哈佛刘小乐实验室出品的软件,也是专门为了作图http://liulab.dfci.harvard.edu/CEAS/usermanual.html
最近有很多朋友咨询我关于生物信息学数据处理的各种问题,有通过QQ直接对话聊天的,或者在QQ群里at我的,或者在知乎上面给我发短信息的,还有给我的163邮箱发信的。怎么说呢,首先还是感谢大家对我的信任,愿意花时间来跟我交流生物信息学数据处理的相关技术,然后我要简单说明一下为什么有些时候我没有答复你,虽然可能对你来讲,我是没有礼貌或者是太傲气了,但是我在这个领域浸淫了这么久,虽然你愿意跟我交流,但是你们的很多问题对我来说要么是都是太小儿科了,简单的google就能解决,要么是太空泛了,我无从答起,甚至我也给不出正确答案,更多的是有些人压根不用心的提问,纯粹是耽误你我的时间,所以我觉得很有必要写这篇博客简单说明一下,什么情况下我会回答你的问题。(如果你的问题非常吸引人,下面你就不用看了,我一定会抢着回答你的!) Continue reading
经过前面的CHIP-seq测序数据处理的常规分析,我们已经成功的把测序仪下机数据变成了BED格式的peaks记录文件,我选取的这篇文章里面做了4次CHIP-seq实验,分别是两个重复的野生型MCF7细胞系的 BAF155 immunoprecipitates和两个重复的突变型MCF7细胞系的 BAF155 immunoprecipitates,这样通过比较野生型和突变型MCF7细胞系的 BAF155 immunoprecipitates的结果的不同就知道该细胞系的BAF155 突变,对它在全基因组的结合功能的影响啦。
#我这里直接从GEO里面下载了peaks结果,它们详情如下:wc -l *bed
6768 GSM1278641_Xu_MUT_rep1_BAF155_MUT.peaks.bed
3660 GSM1278643_Xu_MUT_rep2_BAF155_MUT.peaks.bed
11022 GSM1278645_Xu_WT_rep1_BAF155.peaks.bed
5260 GSM1278647_Xu_WT_rep2_BAF155.peaks.bed
49458 GSM601398_Ini1HeLa-peaks.bed
24477 GSM601398_Ini1HeLa-peaks-stringent.bed
12725 GSM601399_Brg1HeLa-peaks.bed
12316 GSM601399_Brg1HeLa-peaks-stringent.bed
46412 GSM601400_BAF155HeLa-peaks.bed
37920 GSM601400_BAF155HeLa-peaks-stringent.bed
30136 GSM601401_BAF170HeLa-peaks.bed
25432 GSM601401_BAF170HeLa-peaks-stringent.bed
每个BED的peaks记录,本质是就3列是需要我们注意的,就是染色体,以及在该染色体上面的起始和终止坐标,如下:
#PeakID chr start end strand Normalized Tag Count region size findPeaks Score Clonal Fold Change
chr20 52221388 52856380 chr20-8088 41141 +
chr20 45796362 46384917 chr20-5152 31612 +
chr17 59287502 59741943 chr17-2332 29994 +
chr17 59755459 59989069 chr17-667 19943 +
chr20 52993293 53369574 chr20-7059 12642 +
chr1 121482722 121485861 chr1-995 9070 +
chr20 55675229 55855175 chr20-6524 7592 +
chr3 64531319 64762040 chr3-4022 7213 +
chr20 49286444 49384563 chr20-4482 6165 +
我们所谓的peaks注释,就是想看看该peaks在基因组的哪一个区段,看看它们在各种基因组区域(基因上下游,5,3端UTR,启动子,内含子,外显子,基因间区域,microRNA区域)分布情况,但是一般的peaks都有近万个,所以需要批量注释,如果脚本学的好,自己下载参考基因组的GFF注释文件,完全可以自己写一个,我这里会介绍一个R的bioconductor包ChIPpeakAnno来做CHIP-seq的peaks注释,下面的包自带的示例:
library(ChIPpeakAnno)
bed <- system.file("extdata", "MACS_output.bed", package="ChIPpeakAnno")
gr1 <- toGRanges(bed, format="BED", header=FALSE)
## one can also try import from rtracklayer
library(rtracklayer)
gr1.import <- import(bed, format="BED")
identical(start(gr1), start(gr1.import))
gr1[1:2]
gr1.import[1:2] #note the name slot is different from gr1
gff <- system.file("extdata", "GFF_peaks.gff", package="ChIPpeakAnno")
gr2 <- toGRanges(gff, format="GFF", header=FALSE, skip=3)
ol <- findOverlapsOfPeaks(gr1, gr2)
makeVennDiagram(ol)##还可以用binOverFeature来根据特定的GRanges对象(通常是TSS)来画分布图
## Distribution of aggregated peak scores or peak numbers around transcript start sites.
可以看到这个包使用起来非常简单,只需要把我们做好的peaks文件(GSM1278641_Xu_MUT_rep1_BAF155_MUT.peaks.bed等等)用toGRanges或者import读进去,成一个GRanges对象即可,上面的代码是比较两个peaks文件的overlap。然后还可以根据R很多包都自带的数据来注释基因组特征:
data(TSS.human.GRCh37) ## 主要是借助于这个GRanges对象来做注释,也可以用getAnnotation来获取其它GRanges对象来做注释
## featureType : TSS, miRNA, Exon, 5'UTR, 3'UTR, transcript or Exon plus UTR
peaks=MUT_rep1_peaks
macs.anno <- annotatePeakInBatch(peaks, AnnotationData=TSS.human.GRCh37,
output="overlapping", maxgap=5000L)## 得到的macs.anno对象就是已经注释好了的,每个peaks是否在基因上,或者距离基因多远,都是写的清清楚楚
if(require(TxDb.Hsapiens.UCSC.hg19.knownGene)){
aCR<-assignChromosomeRegion(peaks, nucleotideLevel=FALSE,
precedence=c("Promoters", "immediateDownstream",
"fiveUTRs", "threeUTRs",
"Exons", "Introns"),
TxDb=TxDb.Hsapiens.UCSC.hg19.knownGene)
barplot(aCR$percentage)
}
得到的条形图如下,虽然很丑,但这就是peaks注释的精髓,搞清楚每个peaks在基因组的位置特征:
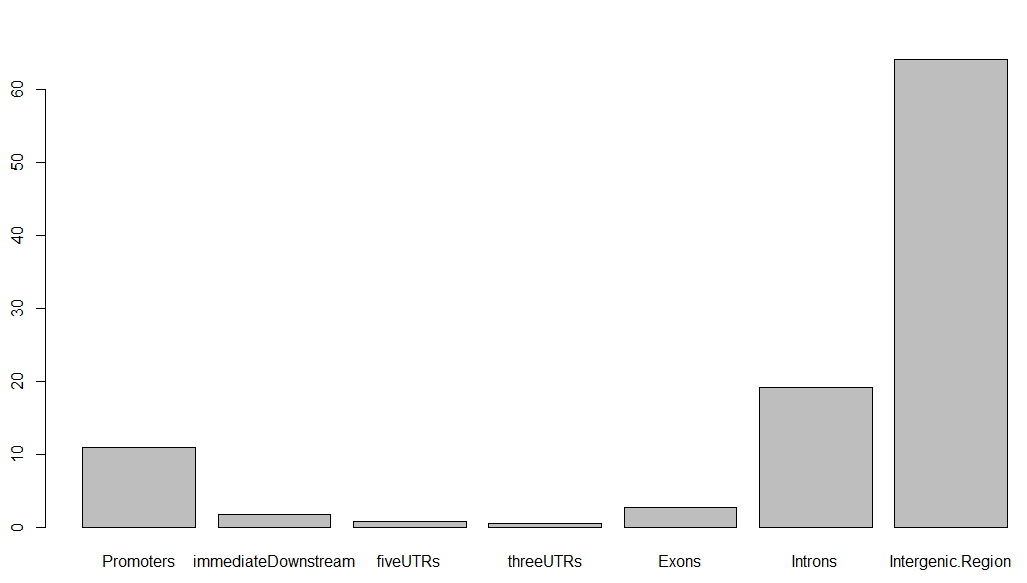
同理,对每个peaks文件,都可以做类似的分析!
但是对多个peaks文件,比如本文中的,想比较野生型和突变型MCF7细胞系的 BAF155 immunoprecipitates的结果的不同,就需要做peaks之间的差异分析,已经后续的差异基因注释啦
当然,值得一提的是peaks注释我更喜欢网页版工具,反正peaks文件非常小,直接上传到别人做好的web tools,就可立即出一大堆可视化图表分析结果啦,大家可以去试试看:
BayesPeak也是peaks caller家族一员,用的人也不少,我这次也试了一下,因为是R的bioconductor系列包,所以直接在R里面安装就好,但是有几个点需要注意,我比对的基因组不只是Chr1~22,X,Y,M,还有一些contig和scaffold,需要在bam文件里面去除的,而且BayesPeak比较支持读取BED文件,可以直接转为GRanges对象,虽然它号称可以使用多核,但是计算速度还是非常慢。 Continue reading
此文专门讲这个软件如何用,但是跟我以前写的软件说明书又不大一样,主要是因为我用MACS2这个软件call peaks并没有达到预期的结果,所以就多使用了几个软件,其中PeakRanger尤其值得一提,安装特别简单,而且处理数据的速度特别快,结果也非常容易理解,更重要的是它给出一个网页版的报告,里面有所有找到的符合要求的peaks的可视化图片!!!! Continue reading