最近在系统性整理肿瘤研究领域的单细胞研究,看到了一个2019的文章《High-dimensional cytometric analysis of colorectal cancer reveals novel mediators of antitumour immunity》居然是35个病人,因为文章里面有10X的关键词,所以我蛮吃惊的。2018和2019是10X商业化早 Continue reading
九
18
最近在系统性整理肿瘤研究领域的单细胞研究,看到了一个2019的文章《High-dimensional cytometric analysis of colorectal cancer reveals novel mediators of antitumour immunity》居然是35个病人,因为文章里面有10X的关键词,所以我蛮吃惊的。2018和2019是10X商业化早 Continue reading
前面的教程:混合到同一个10X样品里面的多个细胞系如何注释,我们提到了可以使用细胞系的表达量矩阵去跟细胞亚群表达量矩阵进行相关性计算。 Continue reading
火山图大家应该是也基本上都没有问题,下面的MA图其实跟火山图非常的类似,两者都是log2FC信息,不同的是火山图展现P值,而MA图展现的是表达量情况! Continue reading
最近接了一个61个10x的单细胞转录组样品项目,使用以前的流程,自动进行质量控制,降维聚类分群,本来应该是分分钟的事情,但是在一个步骤居然卡死了,我看了的这个函数,doubletFinder_v3 ,是去除单细胞转录组里面的双细胞作用,报错如下所示: Continue reading
前些天推荐了第20届国际生物信息学会议(InCoB 2021)将于11月6日至8日在中国云南省昆明市举行给粉丝,见:什么,第20届国际生物信息学大会?,今天又在朋友圈看到了第17届生物信息学研究与应用国际研讨会。我一直以为自己从事生物信息学行业很久了,也算是老兵一个,现在看来,我就是一个弟弟! Continue reading
一般来说,我们进行数据库注释,基因数量在20到500之间,其实100个左右是比较理想的!比如使用Y叔的clusterProfiler进行gsea分析,就有 minGSSize = 10, 和 maxGSSize = 200, 的设置,全部代码如下所示: Continue reading
没想到啊, 居然在中国昆明!
第20届国际生物信息学会议(InCoB 2021)将于11月6日至8日在中国云南省昆明市举行,由中国昆明市昆明理工大学科学院主办。 Continue reading
上周的《单细胞图表复现100篇》栏目,我们分享了2个NSCLC的文献,这周六我们应该是要分享4个ccRCC的文献,PPT已经制作完毕!感兴趣的可以推荐下面的会议,准时参加!(会议密码是: 1024 ) Continue reading
假如你使用如下所示的代码,进行GitHub网站的文件读取:
readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-07-28/penguins.csv')<img class="wp-more-tag mce-wp-more" title="阅读更多…" src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" alt="" data-wp-more="more" data-mce-resize="false" data-mce-placeholder="1" data-mce-src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7">
会有如下所示的报错:
Error in open.connection(con, "rb") :
Failed to connect to raw.githubusercontent.com port 443: Connection refused
这个时候很多R语言小白会下意识的以为是自己的R语言代码有问题,其实如果你仔细 看报错,就应该是明白网络有问题,因为中国大陆绝大部分地区访问GitHub其实是很困难的。
首先,你需要对这个链接有一个基础认识:
rfordatascience 用户名
tidytuesday 仓库名
master 分支名
data/2020/2020-07-28/penguins.csv 文件名及其路径
你之所以无法访问,就是因为 这个 https://raw.githubusercontent.com/ 网页前缀并不是很适合你。你可以试试看cdn加速,只需要进行如下所示的替换:
https://cdn.jsdelivr.net/gh/rfordatascience/tidytuesday@master/data/2020/2020-07-28/penguins.csv
可以复制粘贴这个 url 到你的浏览器,下载这个csv文件就很容易啦,当然,这个时候你的R语言读取它也不是问题。
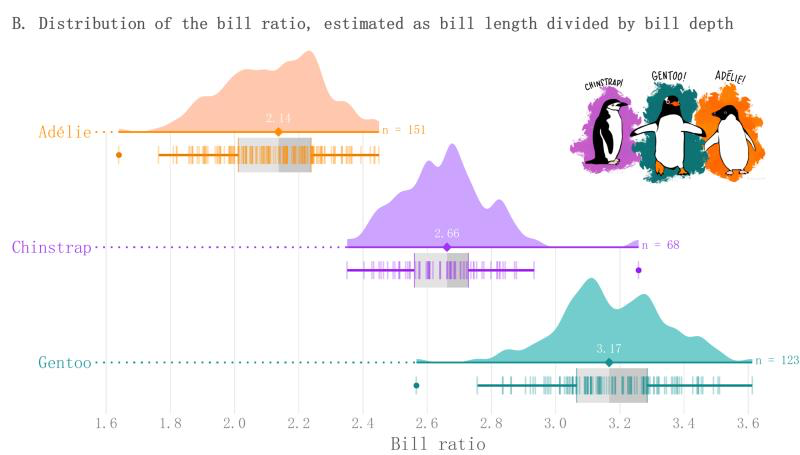
那么,聪明如你,赶快试试看 https://raw.githubusercontent.com/z3tt/TidyTuesday/master/R/2020_31_PalmerPenguins.Rmd 这个教程里面的 散点图箱线图小提琴图联合展示
再怎么强调生物信息学数据分析学习过程的计算机基础知识的打磨都不为过,我把它粗略的分成基于R语言的统计可视化,以及基于Linux的NGS数据处理:
把R的知识点路线图搞定,如下:
前面我们在生信技能树分享了:中国大学MOOC的生物信息学公开课之河南科技大学 ,然后在生信菜鸟团分享了:中国大学MOOC的生物信息学之华中农业大学。 Continue reading
前面我们在生信技能树分享了:中国大学MOOC的生物信息学公开课之河南科技大学 ,然后在生信菜鸟团分享了:中国大学MOOC的生物信息学之华中农业大学。 Continue reading
前面我们在生信技能树分享了:中国大学MOOC的生物信息学公开课之河南科技大学 ,然后在生信菜鸟团分享了:中国大学MOOC的生物信息学之华中农业大学。 Continue reading
本来是想测试一下,使用pyscenic做转录因子分析,然后记录笔记给大家! 所以就有了昨天的:使用pyscenic做转录因子分析,但实际上我在里面埋下了一个伏笔,就是使用conda安装的这个pyscenic,它依赖于一系列的python模块,就会在这里报错!比如我遇到的就是其中一个python模块pandas的报错: Continue reading
肿瘤微环境这个热点应该不仅仅是集中在免疫细胞,其实还有基质细胞,其中热度最高的基质细胞应该是Cancer-associated fibroblasts (CAFs) 。 Continue reading
以前我只知道 CIBERSORT 里面是内置了LM22基因集,CIBERSORT是2015年在Nature Methods发表的一个方法,工具在: (http://cibersort.stanford.edu).,这个方法,直接衍生出了一系列数据挖掘文章, 如果你使用 CIBERSORT + bioinformatics 的关键词去搜索: Continue reading
最近学员群有提问,说他加载了一个包,却无法使用它里面的函数。老实说,我对他这样的提问感到非常的头疼,因为接下来就无休止的沟通,比如具体是什么包是什么函数,然后学员的电脑操作系统,R版本等等。 Continue reading
Smart-seq2和10x这两个单细胞技术是现在初学者进入单细胞领域最需要掌握的,它们代表着单细胞的两个全然不同的发展策略。 Continue reading
上次我们分享了 指定病人的指定基因的突变全景瀑布图,好像一下子戳中了大家的痛点,很多粉丝留言表示感谢,这下子他们终于可以在自己的风险预后模型区分了病人高低分组后,可视化铁死亡基因集,细胞焦亡基因集的突变情况,对比展示。 Continue reading
曾经(大约是2010附近)普通的bulk的转录组测序跟如今的单细胞转录组一样火爆,是个样品就去测序,都不会理会类似的实验设计是否有已经发表的文章。都妄想用经费堆,去摘低垂的果实,所以大量数据烂在手上,拖到后面就越来越难以发表,能捡到个普通杂志发表出去就谢天谢地了。 Continue reading
我们在R语言授课时候最希望传达的一个代码组织习惯就是不同步骤在不同文件夹,而且每个文件夹里面都需要一个Rproject文件,这样鼠标双击就可以打开你的rstudio软件,而且同步定位到当前文件夹作为你的工作目录。 Continue reading