bioconductor系列的包都是一样的安装方式:
source("http://bioconductor.org/biocLite.R")
biocLite("ConsensusClusterPlus")
这个包是我见过最简单的包, 加载只有做好输入数据,只需要一句话即可运行,然后默认输出所有结果
读这个包的readme,很容易学会
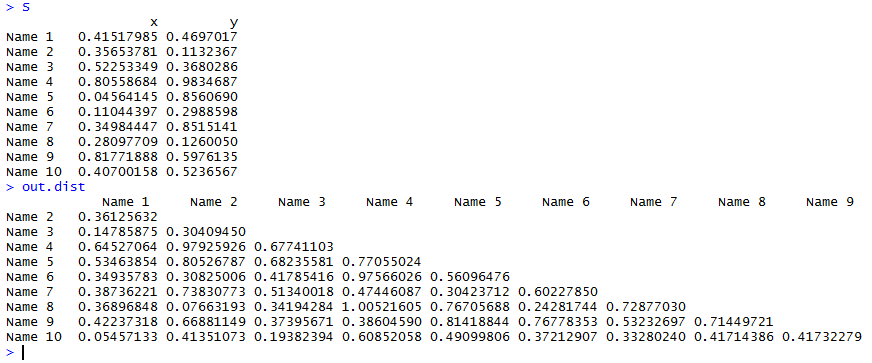
就是做好一个需要来进行分类的样品的表达量矩阵。或者选择上一篇日志用GEOquery这个包下载的表达量矩阵也可以进行分析
因为这个包是用ALL数据来做测试的,所以可以直接加载这个数据结果,这样就能得到表达矩阵啦
library(ALL)
data(ALL)
d=exprs(ALL)
d[1:5,1:5]
可以看到数据集如下
> d[1:5,1:5]
01005 01010 03002 04006 04007
1000_at 7.597323 7.479445 7.567593 7.384684 7.905312
1001_at 5.046194 4.932537 4.799294 4.922627 4.844565
1002_f_at 3.900466 4.208155 3.886169 4.206798 3.416923
1003_s_at 5.903856 6.169024 5.860459 6.116890 5.687997
1004_at 5.925260 5.912780 5.893209 6.170245 5.615210
> dim(d)
[1] 12625 128
共128个样品,12625个探针数据
也有文献用RNAs-seq的RPKM值矩阵来做
对上面这个芯片表达数据我们一般会简单的进行normalization ,然后取在各个样品差异很大的那些gene或者探针的数据来进行聚类分析
mads=apply(d,1,mad)
d=d[rev(order(mads))[1:5000],]
d = sweep(d,1, apply(d,1,median,na.rm=T))
#也可以对这个d矩阵用DESeq的normalization 进行归一化,取决于具体情况
library(ConsensusClusterPlus)
#title=tempdir() #这里一般改为自己的目录
title="./" #所有的图片以及数据都会输出到这里的
results = ConsensusClusterPlus(d,maxK=6,reps=50,pItem=0.8,pFeature=1,
title=title,clusterAlg="hc",distance="pearson",seed=1262118388.71279,plot="png")
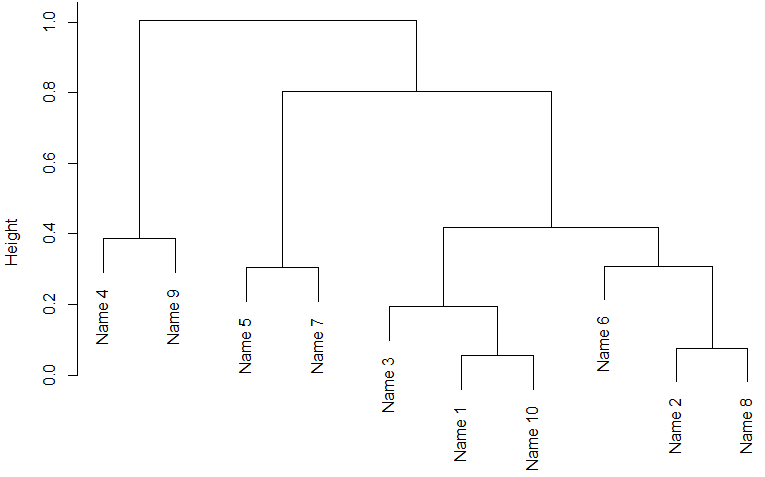
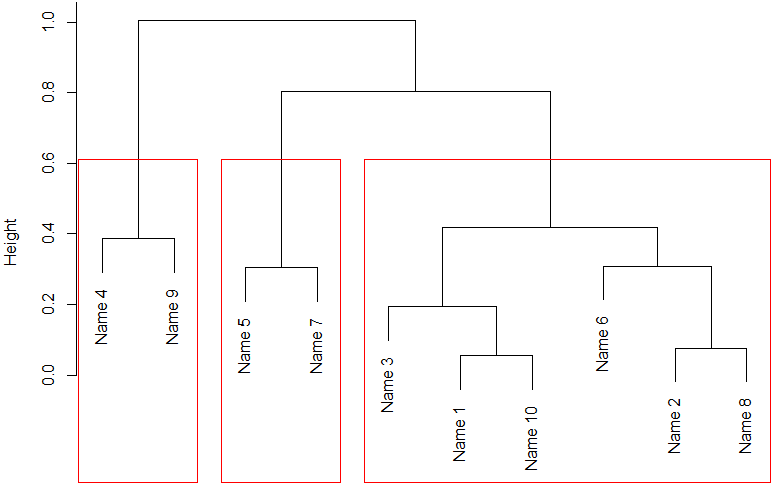
这样就OK了,你指定的目录下面会输出大于9个图片
大家看看说明书就知道这个包的输出文件是什么了。
很多参数都是需要调整的,一般我们的maxK=6是根据实验原理来调整,如果你的样品应该是要分成6类以上,那么你就要把maxK=6调到一点。
查看结果results[[2]][["consensusClass"] 可以看到各个样品被分到了哪个类别里面去
results[[3]][["consensusClass"]
results[[4]][["consensusClass"] 等等