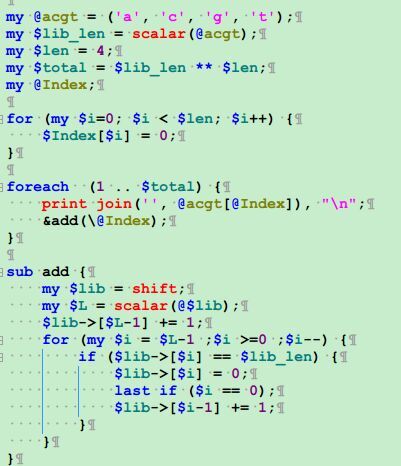
如果我要匹配一个字符串$a="ATTCCGGGAT";那么直接在shell里面grep它即可,写脚本也行$seq =~ /$a/;,但是如果我想查找这个字符串的模糊匹配,允许一个错配的情况,那么就非常多了!这时候简单的匹配已经不能达到目的,但是我们仍然可以用perl强大的正则匹配功能达到目的。
比如,它的匹配模式应该:
/.TTCCGGGAT/
/A.TCCGGGAT/
/AT.CCGGGAT/等等,可以把这些模式都综合起来就是下面这个
$b=(?^:(?:A(?:T(?:T(?:C(?:C(?:G(?:G(?:G(?:A.|.T)|.AT)|.GAT)|.GGAT)|.GGGAT)|.CGGGAT)|.CCGGGAT)|.TCCGGGAT)|.TTCCGGGAT))
所以我们就应该通过程序来生成这个字符串,然后用
$seq =~ /$b/;来替代$seq =~ /$a/;
而允许两个错配的格式就更复杂了:
(?^:(?:A(?:T(?:T(?:C(?:C(?:G(?:G(?:G..|.(?:A.|.T))|.(?:G(?:A.|.T)|.AT))|.(?:G(?:G(?:A.|.T)|.AT)|.GAT))|.(?:G(?:G(?:G(?:A.|.T)|.AT)|.GAT)|.GGAT))|.(?:C(?:G(?:G(?:G(?:A.|.T)|.AT)|.GAT)|.GGAT)|.GGGAT))|.(?:C(?:C(?:G(?:G(?:G(?:A.|.T)|.AT)|.GAT)|.GGAT)|.GGGAT)|.CGGGAT))|.(?:T(?:C(?:C(?:G(?:G(?:G(?:A.|.T)|.AT)|.GAT)|.GGAT)|.GGGAT)|.CGGGAT)|.CCGGGAT))|.(?:T(?:T(?:C(?:C(?:G(?:G(?:G(?:A.|.T)|.AT)|.GAT)|.GGAT)|.GGGAT)|.CGGGAT)|.CCGGGAT)|.TCCGGGAT)))
[perl]
$a="ATTCCGGGAT";
$one_match=fuzzy_pattern($a,1);
print "$one_match\n";
sub fuzzy_pattern {
my ($original_pattern, $mismatches_allowed) = @_;
$mismatches_allowed >= 0
or die "Number of mismatches must be greater than or equal to zero\n";
my $new_pattern = make_approximate($original_pattern, $mismatches_allowed);
return qr/$new_pattern/;
}
sub make_approximate {
my ($pattern, $mismatches_allowed) = @_;
if ($mismatches_allowed == 0) { return $pattern }
elsif (length($pattern) <= $mismatches_allowed)
{ $pattern =~ tr/ACTG/./; return $pattern }
else {
my ($first, $rest) = $pattern =~ /^(.)(.*)/;
my $after_match = make_approximate($rest, $mismatches_allowed);
if ($first =~ /[ACGT]/) {
my $after_miss = make_approximate($rest, $mismatches_allowed-1);
return "(?:$first$after_match|.$after_miss)";
}
else { return "$first$after_match" }
}
}
[/perl]
只需要控制$one_match=fuzzy_pattern($a,1);里面的参数即可控制自己想要的匹配情况。
然后把生成的匹配模式用了进行序列匹配$seq =~ /$one_mismatch/;
这个程序的重点就是解析需要生成的匹配字符串规则,然后用递归来生成这个匹配字符串。
这种匹配,在引物搜索特别有用。