NCBI的重要性我就不多说了,Gene Expression Omnibus database (GEO)是由NCBI负责维护的一个数据库,设计初衷是为了收集整理各种表达芯片数据,但是后来也加入了甲基化芯片,lncRNA,miRNA,CNV芯片等各种芯片,甚至高通量测序数据!所有的数据均可以在ftp站点下载:ftp://ftp-trace.ncbi.nih.gov/geo/ Continue reading
八
02
NCBI的重要性我就不多说了,Gene Expression Omnibus database (GEO)是由NCBI负责维护的一个数据库,设计初衷是为了收集整理各种表达芯片数据,但是后来也加入了甲基化芯片,lncRNA,miRNA,CNV芯片等各种芯片,甚至高通量测序数据!所有的数据均可以在ftp站点下载:ftp://ftp-trace.ncbi.nih.gov/geo/ Continue reading
- chromatin structure (5C)
- open chromatin (DNase-seq and FAIRE-seq)
- histone modifications and DNA-binding of over 100 transcription factors (ChIP-seq)
- RNA transcription (RNAseq and CAGE)
以前我写过如何使用GEOquery和GEOmetadb, 它们的确很强大,也很好用,做芯片数据pipeline的时候可以省很多力,但最近很多朋友都反应它联网有问题,经常无法下载数据!
为了解决这个问题,我仔细又研究了一下GEO数据库,其实官网本身就提供了WEB API接口,直接根据需求定制化下载数据!
我们使用GEO数据,无非就是想根据study ID号(比如:GSE1009)得到它的raw CEL文件,或者表达矩阵,或者样本分组信息!!!
如果用R包GEOquery来完成这个目的,请参考我的说明书:
其实raw CEL文件,直接自己拼接url即可
ftp://ftp.ncbi.nlm.nih.gov/geo/series/GSE1nnn/GSE1009/matrix/GSE1009_series_matrix.txt.gz
##表达矩阵,需要用在R里面read,skip掉注释信息,tab键分割
ftp://ftp.ncbi.nlm.nih.gov/geo/series/GSE1nnn/GSE1009/suppl/GSE1009_RAW.tar
##芯片原始数据,用affy包来读取
http://www.ncbi.nlm.nih.gov/geo/browse/?view=samples&series=1009&mode=csv
###样本分组信息
根据任意study ID号,非常容易就可以拼接出这些url,完全hold住GEOquery这个包的所有功能!
如果该研究涉及到的样本较多,你还可以根据下面的文件列表来有选择性的抓取样本!
ftp://ftp.ncbi.nlm.nih.gov/geo/series/GSE1nnn/GSE1009/suppl/filelist.txt
你要明白的就是浏览器的get请求而已,把下面的字符串组合成一个完整的URL即可
view=series& ## 四种,zsort=date&mode=csv& ##很重要,可以直接下载csv文件page=$i&display=5000 ##很重要查看总数:curl --silent "http://www.ncbi.nlm.nih.gov/geo/browse/" | grep "total_count"
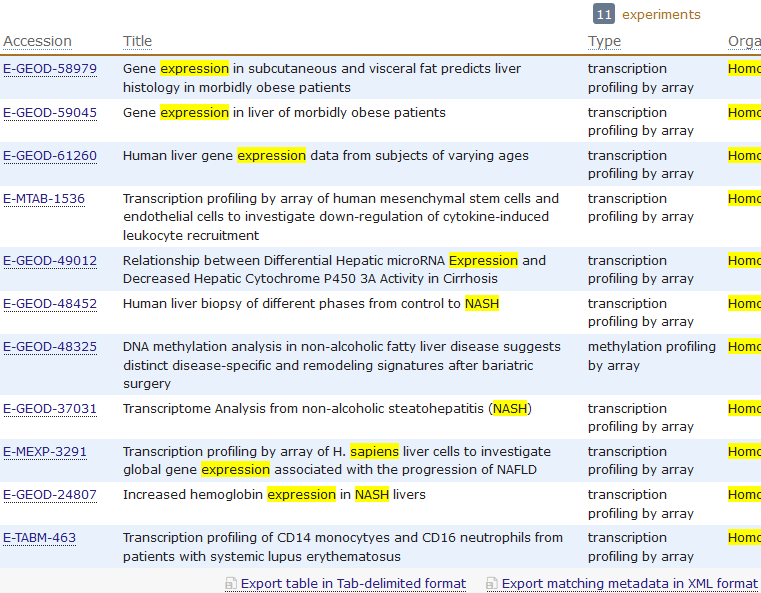
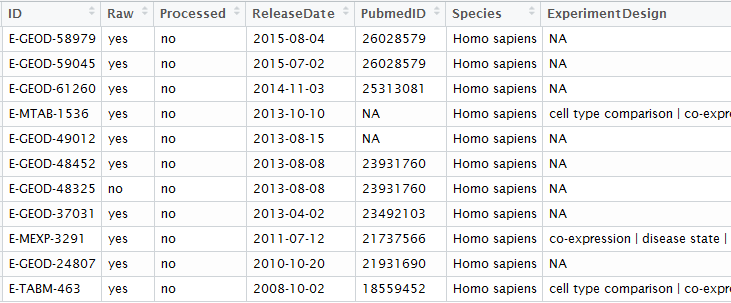
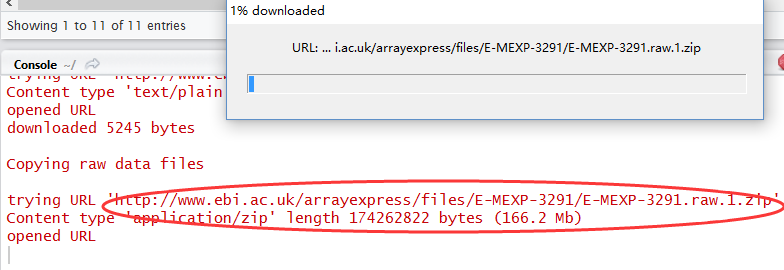
rawset = ArrayExpress("E-MEXP-3291")
理论上我前面提到的GEOquery包就可以根据一个GSE索引号来获取NCBI提供的所有关于这个GSE索引号的数据了,包括metadata,表达矩阵,soft文件,还有raw data
但是很多时候,那个metadata并不是很整齐,而且一个个下载太麻烦了,所以就需要用R的bioconductor的另一个神奇的包了GEOmetadb
它的示例:http://bioconductor.org/
library(GEOmetadb)
if(!file.exists('GEOmetadb.sqlite')) getSQLiteFile()
file.info('GEOmetadb.sqlite')
con <- dbConnect(SQLite(),'GEOmetadb.sqlite')
dbDisconnect(con)
但是一般不会成功,因为这个包把它的GEOmetadb.sqlite文件放在了国外网盘共享,在国内很难访问,推荐大家想办法下载到本地
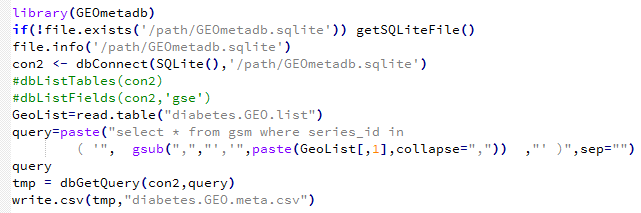 用这个代码就会成功了,需要自己下载GEOmetadb.sqlite文件然后放在指定目录:/path/GEOmetadb.sqlite 需要自己修改
我们的diabetes.GEO.list文件内容如下:
GSE1009
GSE10785
GSE1133
GSE11975
GSE121
GSE12409
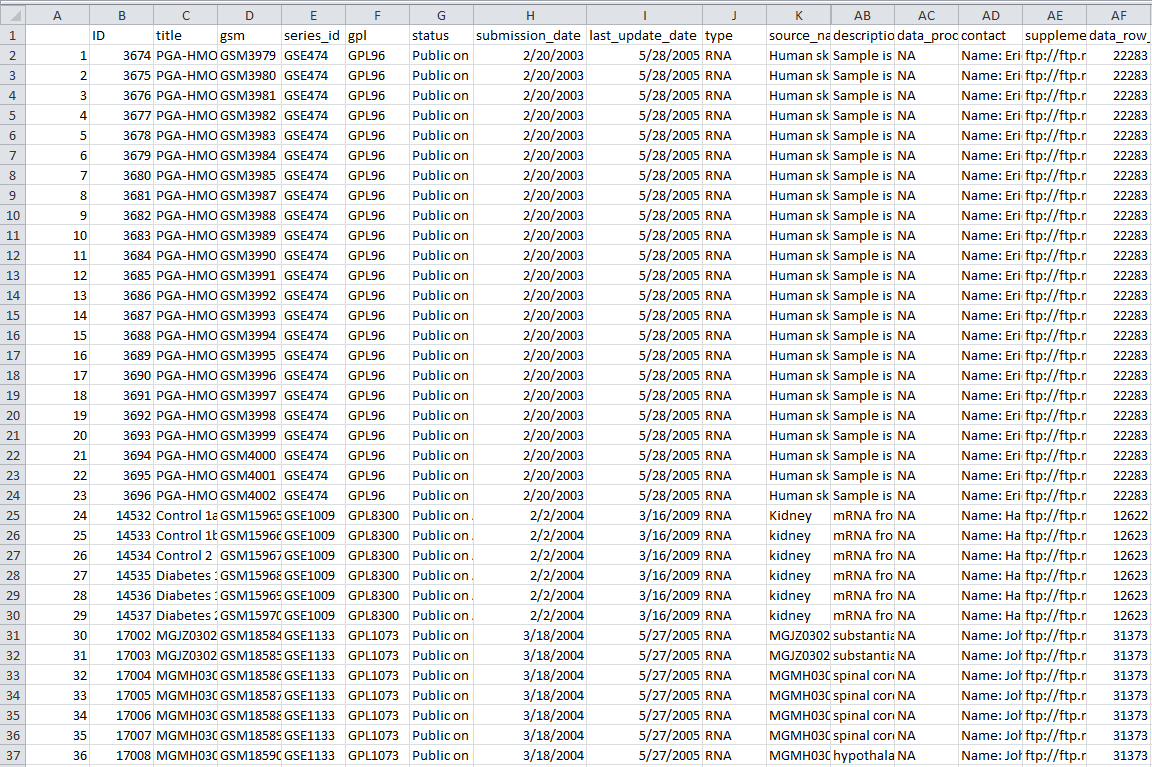
那么会产生的表格文件如下:共有32列数据信息,算是蛮全面的了
用这个代码就会成功了,需要自己下载GEOmetadb.sqlite文件然后放在指定目录:/path/GEOmetadb.sqlite 需要自己修改
我们的diabetes.GEO.list文件内容如下:
GSE1009
GSE10785
GSE1133
GSE11975
GSE121
GSE12409
那么会产生的表格文件如下:共有32列数据信息,算是蛮全面的了