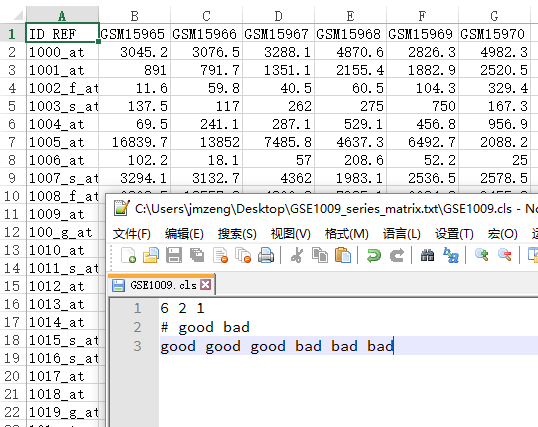
熟悉GSEA软件的都知道,它只需要GCT,CLS和GMT文件,其中GMT文件,GSEA的作者已经给出了一大堆!就是记录broad的Molecular Signatures Database (MSigDB) 已经收到了18026个geneset,但是我奇怪的是里面竟然没有包括cancer testis的gene set,MSigDB的确是多,但未必全,其实里面还有很多重复。而且有不少几乎没有意义的gene set。那我想做自己的gene set来用gsea软件做分析,就需要自己制造gmt格式的数据。因为即使下载了MSigDB的gene set,本质上就是gmt格式的数据而已:http://software.broadinstitute.org/cancer/software/gsea/wiki/index.php/Data_formats#GMT:_Gene_Matrix_Transposed_file_format_.28.2A.gmt.29 Continue reading
十二
15