首先是宾夕法尼亚州立大学(The Pennsylvania State University缩写PSU)的生信课件下载,这个生信不仅有课件,而且在中国的优酷视频网站里面还有全套授课视频,非常棒!
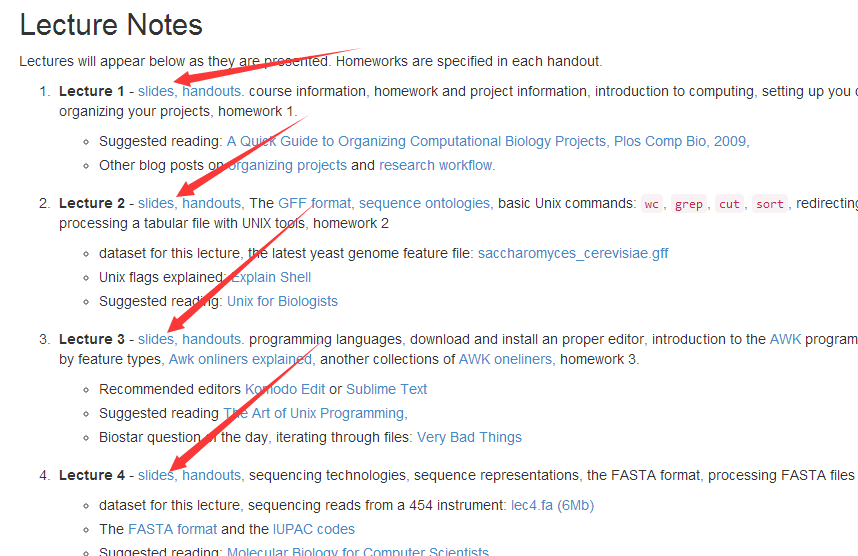
课程主页是http://www.personal.psu.edu/iua1/courses/2013-BMMB-597D.html
可以看出所有的课件pdf链接都在这一个页面,所以是非常简单的代码!
下面是R代码:
library(XML)
library(RCurl)
library(dplyr)
psu_edu_url='http://www.personal.psu.edu/iua1/courses/2013-BMMB-597D.html';
wp=getURL(psu_edu_url)
base='http://www.personal.psu.edu/iua1/courses/file';
#pse_edu_links=getHTMLLinks(psu_edu_url)
psu_edu_links=getHTMLLinks(wp)
psu_edu_pdf=psu_edu_links[grepl(".pdf$",psu_edu_links,perl=T)]
for (pdf in psu_edu_pdf){
down_url=getRelativeURL(pdf,base)
filename=last(strsplit(pdf,"/")[[1]])
cat("Now we down the ",filename,"\n")
#pdf_file=getBinaryURL(down_url)
#FH=file(filename,"wb")
#writeBin(pdf_file,FH)
#close(FH)
download.file(down_url,filename)
}
因为这三十个课件都是接近于10M,所以下载还是蛮耗时间的
其实R语言里面有这个down_url函数,可以直接下载download.file(down_url,filename)
然后我开始下载德国自由大学的生信课件,这次不同于宾夕法尼亚州立大学的区别是,课程主页里面是各个课题的链接,而pdf讲义在各个课题里面,所以我把pdf下载写成了一个函数对我们的课题进行批量处理
library(XML)
library(RCurl)
library(dplyr)
base="http://www.mi.fu-berlin.de/w/ABI/Genomics12";
down_pdf=function(url){
links=getHTMLLinks(url)
pdf_links=links[grepl(".pdf$",links,perl=T)]
for (pdf in pdf_links){
down_url=getRelativeURL(pdf,base)
filename=last(strsplit(pdf,"/")[[1]])
cat("Now we down the ",filename,"\n")
#pdf_file=getBinaryURL(down_url)
#FH=file(filename,"wb")
#writeBin(pdf_file,FH)
#close(FH)
download.file(down_url,filename)
}
}
down_pdf(base)
list_lecture= paste("http://www.mi.fu-berlin.de/w/ABI/GenomicsLecture",1:15,"Materials",sep="")
for ( url in list_lecture ){
cat("Now we process the ",url ,"\n")
try(down_pdf(url))
}

同样也是很多pdf需要下载
接下来下载Minnesota大学的关于生物信息的教程的ppt合集
主页是: https://www.msi.umn.edu/tutorial-materials
这个网页里面有64篇pdf格式的ppt,还有几个压缩包,本来是准备写爬虫来爬去的,但是后来想了想有点麻烦,而且还不一定会看,反正也是玩玩
就用linux的命令行简单实现了这个爬虫功能。
curl https://www.msi.umn.edu/tutorial-materials >tmp.txt
perl -alne '{/(https.*?pdf)/;print $1 if $1}' tmp.txt >pdf.address
perl -alne '{/(https.*?txt)/;print $1 if $1}' tmp.txt
perl -alne '{/(https.*?zip)/;print $1 if $1}' tmp.txt >zip.address
wget -i pdf.address
wget -i pdf.zip
这样就可以啦!
用爬虫也就是几句话的事情,因为我已经写好啦下载函数,只需要换一个主页即可下载页面所有的pdf文件啦!